This RFC is built upon on the following prior RFCs :
A1) https://discuss.tvm.ai/t/relay-improved-graph-partitioning-algorithm/5830
A2) [Discuss] Annotation Defined Subgraphs - #8 by mbaret - pre-RFC - Apache TVM Discuss
Myself and @manupa-arm propose a revised target partitioning flow to:
- Introduce support for partitions with multiple outputs.
- Lay out a framework to better support partitioning for multiple targets.
- Improve support for ‘composite functions’.
We have an early draft PR which partially implements this new flow here: https://github.com/apache/incubator-tvm/pull/5100. Expect to see further updates to it over the coming days.
Some terminology we’re using:
Annotations: Annotations are represented in Relay as call nodes to an annotation operator. They should be considered as a ‘no op’. They exist on data flow edges and must necessarily have one parent and one child. They come in two flavours - begin and end. Begin-type annotations go on incoming data flow edges and end-type annotations on outgoing edges.
Regions: Regions are sections of the Relay program that are bounded by a set of begin/end annotations on all data flow edges. They are conceptual objects that are not literally present in the program. When you annotate a program, you create one or more annotated regions . Strictly, the annotations are themselves included in the region they define.
With an extended partitioning pipeline, we propose introducing a new type of annotation - Supported Annotations. The primary distinction between supported annotations and compiler annotations is that supported annotations can overlap one another, whereas compiler annotations must necessarily be disjoint. In particular:
Supported Annotations/Regions
- Indicate regions of the graph that are ‘atomically’ supported by a target
- Cannot be merged
- Can overlap
Compiler Annotations/Regions
- Indicate what target regions WILL be offloaded to
- Cannot overlap
- The set of all compiler regions must cover the entire program - everything must be assigned exactly one target
Currently both of these functions are fulfilled by the compiler annotations. This leads to some ambiguity over what role the annotations are performing, particularly when annotating multiple overlapping targets. In our initial draft PR, we do not yet introduce ‘Supported’ annotations (compiler annotations still fulfill both roles), but it is our intention to replace them shortly.
A diagram for the proposed flow:
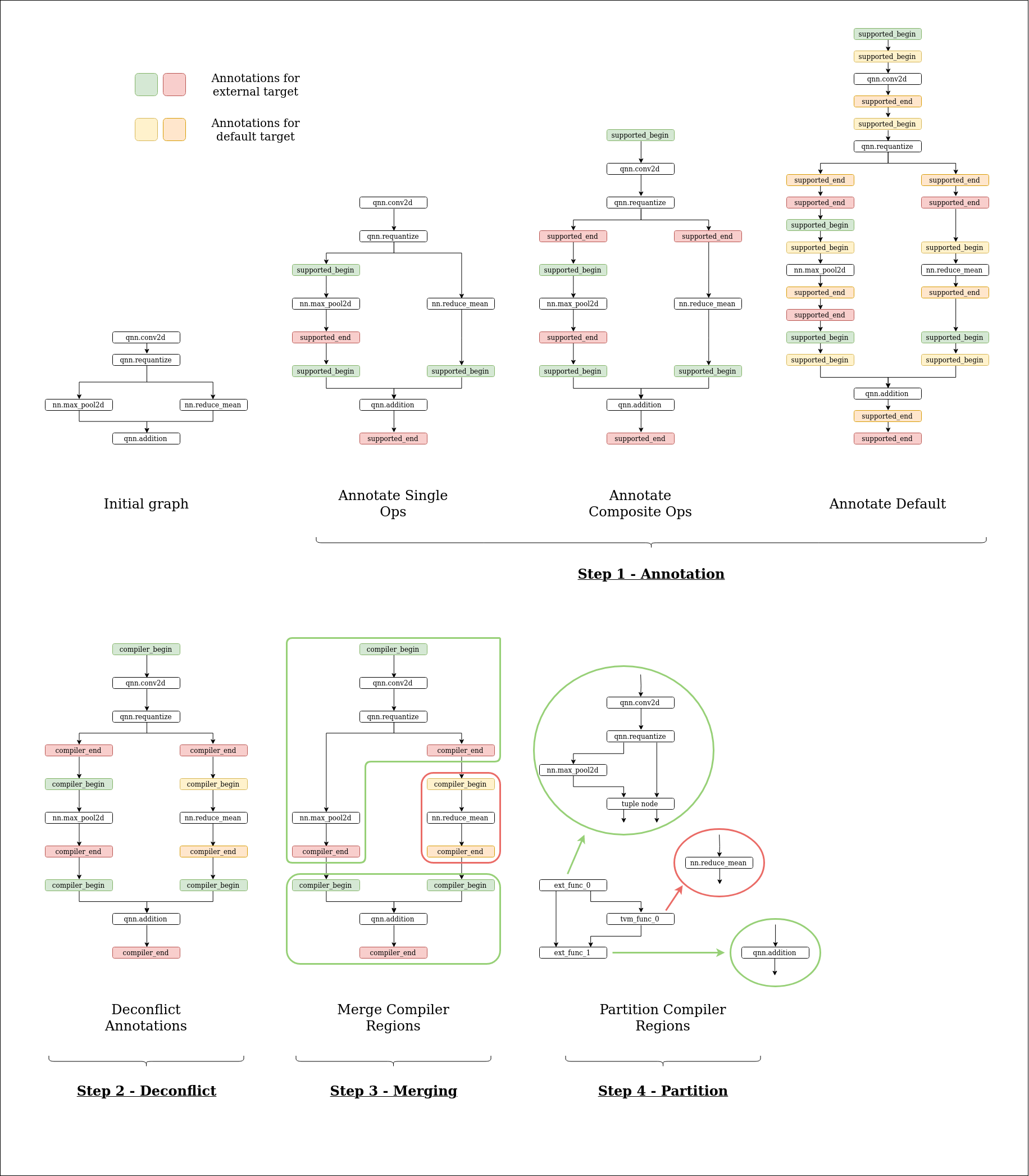
Step 1 - Annotation
During the annotation phase, we mark operators (or patterns of operators) as supported by a given target. This means introducing Supported Annotations around the Supported Regions . Currently, this is done in AnnotateTarget which only handles the case of single operations being supported. We can use that to handle both cases using MergeComposite, however in future we should look towards being able to directly annotate patterns as supported (probably when the pattern matching infrastructure is introduced). In the diagrams, I’ve broken down annotating single ops separately to annotating composite ops for clarity, but there’s no reason these can’t be combined into a single pass.
Additionally, to remove special-cased behaviour for the default compiler (TVM), we should have a mandatory ‘annotate default’ pass. This is the same as annotating for a target, only every node is supported.
NOTE: Default annotation currently happens in the merging pass (because we have no de-conflict) and only annotates regions which are not already annotated.
Step 2 - De-conflict
NOTE: This isn’t yet implemented in the draft PR and as such multiple target annotation isn’t yet supported.
Once annotation has taken place for all interested targets, a de-conflict pass is needed to run to decide which target each part of the program is going to be compiled for. We are proposing a simple greedy scheme where a priority order is provided by the user (e.g. ACL >> DNNL). Thus, all conflicting supported regions will be resolved in favour of the highest priority target. However, there’s the freedom to run a custom de-conflict pass to decide on the target. When this pass takes place, we will guarantee that each supported region becomes disjoint and that every node is assigned to exactly one target. Therefore, we promote the Supported Annotations to Compiler Annotations - inserted as compiler_begin and compiler_end to all the incoming and outgoing edges.
Step 3 - Merge Regions
Thereafter, the regions annotated by Compiler Annotations (which are disjoint by definition), can be merged. This allows codegens to see a larger part of the program at once which may allow for more extensive optimisation. The merging is handled by the algorithm in A1 which takes care of data flow dependency issues. We would like to call this MergeCompilerRegions ( NOTE: in the draft PR, it’s called MergeSupported).
Step 4 - Partition Regions
After obtaining merged disjoint regions annotated by Compiler Annotations, we use the PartitionGraph pass (suggest renaming to PartitionCompilerRegions) to export the regions as global functions. The existing PartitionGraph pass does not support multiple outputs and we propose an improved PartitionGraph pass that can create Tuples to handle this case.
As ever, we’re happy to answer any comments/questions! If there’s some agreement that this is the right approach to take, I’ll make a poll on possible names for the various elements of this RFC.