update (March 3, 2021): The integration is finished, see our blog post
Motivation
The current autotvm requires pre-defined schedule templates. This makes autotvm only semi-automated: the search is automated, but the search space has to be manually defined by developers using the schedule templates. This approach has several drawbacks:
The templates are hard to write. It takes a great number of engineering efforts to develop these templates.
The number of required templates is large and continues to grow as new operators come.
The templates are far from optimal. There is still huge opportunity for performance improvements by enlarging the search space in templates, but manually enumerating these optimizations choices is prohibitive.
Our solution
We implemented Ansor, a new framework to replace the existing autotvm. Ansor has several key advantages:
Ansor automatically generates a much larger search space from compute declaration only
Ansor searches more efficiently than AutoTVM by utilizing improved cost model, evolutionary search and task scheduler
We have got good results on a variety of deep learning models (ResNet, MobileNet, 3D-ResNet, DCGAN, BERT) and hardware platforms (Intel CPU, NVIDIA GPU, ARM CPU). Ansor outperforms autotvm on all benchmarks with significant speedup.
Please see our tech report for more details.
In terms of implementations, there are several major components of Ansor:
The infrastructure for search: A new lightweight loop structure IR to enable flexible and efficient loop manipulation.
The search policy and new cost model
Relay integration
They are mainly implemented in C++ with around 10K lines of code. We plan to gradually upstream them for ease of review.
Integration Process
We will upstream our code with several pull requests and then deprecate autotvm. The steps are:
Upstream the infrastructure for search (i.e. the lightweight loop structure IR)
Upstream search policy and tutorials for auto-scheduling an operator or a subgraph
Upstream relay integration and tutorials for auto-scheduling a network
Design customization APIs to support customized search space
Deprecate autotvm
Our code is almost ready and we will send the first PR in the next week.
Thanks @merrymercy for this work! I have several questions regarding to this plan:
In Ansor paper there are relative performance number between current autotvm and ansor, it would be great to have some benchmark data in terms of latency. For example, for resnet50_v1 we can achieve 2.2 ms on p3(V100) and 5.4ms on c5.9xlarge, would be nice to see how much more improvement we can get with ansor.
In terms of deprecating autotvm, does it mean we will also deprecate current schedule system(op strategy as well?) Would it be better to introduce Ansor as a standalone module since we might still need handcraft schedule in some cases?
Also I think a benchmark to cover more models on more platforms would be necessary if we want breaking changes in the system. In addition, we can probably consider different methods of codegen in tvm as baseline. One example is that currently we use TVM+MKLDNN for bert on x86 cpu since x86 dense schedule is far less efficient than MKLDNN. By benchmarking all these different methods against Ansor, we can better understand the capability and boundary of Ansor(Tradeoffs between peprformance, tuning time and extra library dependency).
Thanks for this RFC, it looks awesome! I’ve had a quick read through the paper but I think it will take me some time to understand the details. Just a few initial questions:
Do you see this replacing most or all of the scheduling that’s currently in TOPI eventually?
Will there be a way to run Ansor with some ‘best guess’ heuristics to produce decent schedules without explicit tuning, perhaps something analagous to TopHub?
Have you looked into Mali GPU, and if not is Ansor flexible enough to support new targets?
Do you expect Ansor to work well with Hybrid Script (I have non-max suppression in mind)?
I’d also like to second Masahi in saying that seeing performance of quantised models would be very interesting.
I think framing Ansor as AutoTVM v2.0 is somewhat misleading as Ansor is taking a totally different approach from AutoTVM. Also, I feel that planning to have Ansor deprecate autotvm is a too strong statement. I will expect Ansor and AutoTVM (along with the existing schedules in TOPI) co-exist for a not short period of time.
While using ansor to deprecate AutoTVM is a strong statement, I think it is a goal we should strive to achieve. I do not think it will replace the op strategy though, since we need strategy for the graph level selection and dispatching.
In particular, I would encourage us to think toward that technical direction – bring a unified design that allows customizations, provide customization API similar to the current AutoTVM templates – so domain specific space customization can be migrated to ansor, while generalizes to more automated setting.
Thinking hard about the ideal design would help us to stay focused, and evolve the codebase towards a concise, composable and better solution in the long run.
IMO, AutoTVM + schedule template system represents a methodology which developer can create and fully control their own kernel optimization, which is functionally disjoint with Ansor. If deprecating AutoTVM means we will not discard any core functionalities but just unify them under a larger paradigm to allow both fully automate or semi-automate method, it will look more practical at this point. Probably unifying AutoTVM would be a more precise statement?
We do support to generate OpenCL, so we could run on Mali GPU. However, we don’t test it on Mali GPU when we complete Ansor. Some difference compared with Nvidia GPU we could see, for example, on Mali GPU, we shouldn’t use cache_read("shared") because Mali GPU doesn’t have separate shared memory like Nvidia GPU. And we should generate vectorize explicitly which doesn’t be required by Nvidia GPU. The workload shouldn’t be much as far as I can see.
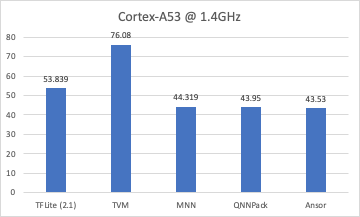
We have collected the performance data of TFLite quantized model (mobilenet v2) on ARM CPU. However we don’t put it on paper. I am glad to share it:
The target is 4 cores of cortext-a53, qnnpack commit is (b7bacb1899e6fa3a934c1dd6128096f2e1abf071) and only convolution been counted (because qnnpack is one library, not inference engine).
As you could see we have competitive performance compared with TFLite (2.1) and libraries like Qnnpack. However we should still have room to improve, for example we should generate the pari instruction (smlal / smlal2), which maybe could be done by tensorize.
The API for tuning a whole neural network will be the same as autotvm (extract tasks and tune all of them).
The API for writing templates is still under development. But it will be similar to autotvm.
Performance in absolute time
We didn’t run on c5.9x large. On our test machine (a 20-core cascadelake), we get around 10% improvements on resnet-50, which means around 0.5ms speedup.
Dense schedule
Ansor significantly outperforms autotvm on dense and can match MKLDNN. So this may not be a big issue. Combining MKLDNN and TVM is orthogonal to this RFC.
Quantized models
@FrozenGene got promissing results on ARM CPU. But we expect more work has to be done on tensorization.
Replacing AutoTVM
Currently, I am confident that Ansor can replace all fp32 autotvm templates.
I agree that current AutoTVM serves as a handy tool for manual exploration and we should not deprecate this functionality. We should support easy manual customization in Ansor and then replace AutoTVM.
Code generation without tuning
This is on my to-do list. We have a better and unified cost model (one model for all operators), so we should be able to get some results in this direction.
Hybrid Script
This is not supported and not easy to support. Ansor only accepts tvm.compute as input.
New backend
We need modifications of the search space. Ansor supports search space customization by allowing users to register composable rules. The framework is general for different backends.
Thanks @merrymercy
The point of bringing up MKLDNN is that for dense op these libraries have a bag of tricks which might be difficult to achieve in TVM. @haichen has done nice work on TVM+MKLDNN for bert, and has become the standard way we use to support bert on cloud CPU. It would be nice to see whether Ansor can be another option in this use case. This will provide us more insights between manual method and fully automated one.
For user API, will we have some kind of extra parameters to support both schedule template tuning and Ansor. Can you share more information about this?
I support fully deprecate template based AutoTVM. Technically, template based AutoTVM is a subset of Ansor’s search space. We may temperately allow one release to keep both AutoTVM and Ansor. But in a long run I can’t see any reason we should keep AutoTVM.
I agree. As long as we can demonstrate that Ansor customized rules can fully cover the current AutoTVM templates in terms of the semantic and performance, we can deprecate AutoTVM. While we are working to achieve this goal, we will definitely have a period of time to keep both solutions.
They had a public repo (removed a few days ago), i am still wondering if polyhedral priors could bring any benefit to Ansor (e.g. help to reduce/optimize the search space) ?