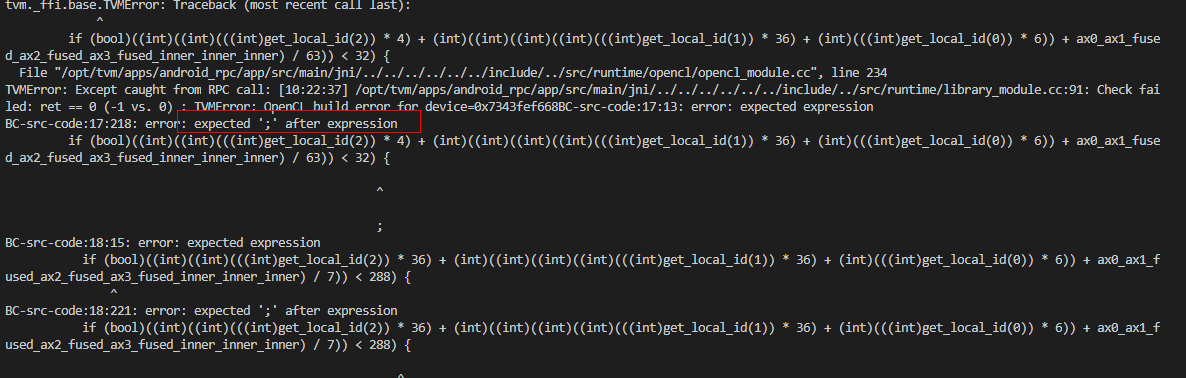
I am testing resnet18(mxnet gluon model) quantization int8 with relay on RPC app. The arm64 cpu (llvm) is passed. However, the opencl with quantization int8 is error:
compute[((((int)get_group_id(0)) * 256) + ((int)get_local_id(0)))] = max(min(max((placeholder[((((int)get_group_id(0)) * 256) + ((int)get_local_id(0)))] + placeholder1[((((int)get_group_id(0)) * 256) + ((int)get_local_id(0)))]), (char)0), (char)127), (char)-127);
I guess there is a bug with opencl quantization, how to solved it? Thanks for your help! The code is modified from github.
# -*- coding: utf-8 -*-
from __future__ import absolute_import, print_function
from collections import namedtuple
import argparse, json, os, requests, sys, time
from io import BytesIO
from os.path import join, isfile
from PIL import Image
import numpy as np
from matplotlib import pyplot as plt
from collections import namedtuple
import tvm
from tvm import relay
from tvm.relay import quantize as qtz
from tvm.contrib import download, util
from tvm import autotvm
from tvm.autotvm.tuner import XGBTuner, GATuner, RandomTuner, GridSearchTuner
import mxnet as mx
from mxnet import gluon
import logging
import os
import time
import logging
logging.basicConfig(level=logging.DEBUG)
from tvm.contrib.debugger import debug_runtime as graph_runtime
from tvm.contrib.download import download_testdata
from tvm.contrib import ndk
from tvm import rpc
tracker_host = "0.0.0.0"
tracker_port = 6007
key = "android"
arch = "arm64-v8a"
is_armcpu = False
temp = util.tempdir()
Config = namedtuple('Config', ['model', 'nbit_input', 'dtype_input', 'nbit_output', 'dtype_output', 'global_scale', 'batch_size'])
# Set number of threads used for tuning based on the number of
# physical CPU cores on your machine.
# num_threads = 2
# os.environ["TVM_NUM_THREADS"] = str(num_threads)
def get_mxnet_model(model_name, batch_size):
"""Get mxnet model.
Parameters
----------
model_name : str
batch_size : num
Returns
-------
mod : tvm.relay.Module
params : dict of str to tvm.NDArray
input_shape : tuple
"""
gluon_model = gluon.model_zoo.vision.get_model(model_name, pretrained=True)
img_path='./elephant-299.jpg'
from PIL import Image
image = Image.open(img_path).resize((299, 299))
x = np.array(image).reshape(1,3,299,299)
start_time = time.time()
y = gluon_model(mx.ndarray.array(x))
print("=======", (time.time()-start_time)*1000)
img_size = 299 if model_name == 'inceptionv3' else 224
input_shape = (batch_size, 3, img_size, img_size)
mod, params = relay.frontend.from_mxnet(gluon_model, {"data": input_shape})
return mod,params,input_shape
def quantize_relay_module(mod, params, qconfig=None):
""" Quantize the relay module with qconfig options.
Parameters:
------
mod : tvm.relay.module
The original module.
qconfig : tvm.relay.quantize.quantize.QConfig
The quantization configuration
Returns:
------
qfunc : vm.relay.expr.Function
The graph after quantization
"""
# default qconfig
if not qconfig:
qconfig = qtz.qconfig()
with qconfig:
logging.debug('current quantize config')
logging.debug(qtz.current_qconfig())
mod = qtz.quantize(mod,params=params)
logging.debug('after quantize')
logging.debug(mod['main'].astext(show_meta_data=False))
return mod
def autotvm_tune(func,params,target):
"""
Parameters:
----------
func : relay.expr.Function
params : dict of str to numpy array
target : tvm.target.Target
ops : List of relay.op
"""
# Array of autotvm.task.Task
tasks = autotvm.task.extract_from_program(func, target=target,
params=params, ops=(relay.op.nn.conv2d,))
print("extract_before")
# Check tasks.
for i in range(len(tasks)):
op_name = tasks[i].workload[0]
if op_name == 'conv2d':
func_create = 'topi_x86_conv2d_NCHWc'
elif op_name == 'depthwise_conv2d_nchw':
func_create = 'topi_x86_depthwise_conv2d_NCHWc_from_nchw'
else:
raise ValueError("Tuning {} is not supported on x86".format(op_name))
print ( "[Create Task %2d/%2d (%s, %s) ] " % (i+1, len(tasks), tasks[i].name, tasks[i].workload[0]))
tsk = autotvm.task.create(func_create, args=tasks[i].args,
target=tasks[i].target, template_key='direct')
tsk.workload = tasks[i].workload
tasks[i] = tsk
# turning option.
tuner='xgb'
n_trial=1
early_stopping=None
log_filename='tuning.log'
use_transfer_learning=True
measure_option = autotvm.measure_option(
builder=autotvm.LocalBuilder(timeout=10),
runner=autotvm.LocalRunner(number=10, repeat=1, min_repeat_ms=1000))
# runner=autotvm.RPCRunner(
# 'jon', # change the device key to your key
# '0.0.0.0', 3465,
# number=20, repeat=3, timeout=4, min_repeat_ms=150))
# create tmp log file
tmp_log_file = log_filename + ".tmp"
if os.path.exists(tmp_log_file):
os.remove(tmp_log_file)
for i, tsk in enumerate(reversed(tasks)):
prefix = "[Task %2d/%2d] " %(i+1, len(tasks))
# create tuner
if tuner == 'xgb' or tuner == 'xgb-rank':
tuner_obj = XGBTuner(tsk, loss_type='rank')
elif tuner == 'ga':
tuner_obj = GATuner(tsk, pop_size=100)
elif tuner == 'random':
tuner_obj = RandomTuner(tsk)
elif tuner == 'gridsearch':
tuner_obj = GridSearchTuner(tsk)
else:
raise ValueError("Invalid tuner: " + tuner)
if use_transfer_learning:
if os.path.isfile(tmp_log_file):
tuner_obj.load_history(autotvm.record.load_from_file(tmp_log_file))
# do tuning
tuner_obj.tune(n_trial=min(n_trial, len(tsk.config_space)),
early_stopping=early_stopping,
measure_option=measure_option,
callbacks=[
autotvm.callback.progress_bar(n_trial, prefix=prefix),
autotvm.callback.log_to_file(tmp_log_file)])
# pick best records to a cache file
autotvm.record.pick_best(tmp_log_file, log_filename)
os.remove(tmp_log_file)
def build_module(mod,params,target,best_records=None, host = None):
# build module
if best_records:
with autotvm.apply_history_best(best_records):
with relay.build_config(opt_level=3):
graph, lib, params = relay.build_module.build(mod, target=target, target_host = host, params=params)
else:
with relay.build_config(opt_level=3):
graph, lib, params = relay.build_module.build(mod, target=target,target_host = host, params=params)
return graph,lib,params
def transform_image(image):
image = np.array(image) - np.array([123., 117., 104.])
image /= np.array([58.395, 57.12, 57.375])
image = image.transpose((2, 0, 1))
image = image[np.newaxis, :]
return image
def get_transfer_img(img_path = None):
# synset_url = ''.join(['https://gist.githubusercontent.com/zhreshold/',
# '4d0b62f3d01426887599d4f7ede23ee5/raw/',
# '596b27d23537e5a1b5751d2b0481ef172f58b539/',
# 'imagenet1000_clsid_to_human.txt'])
# synset_name = 'imagenet1000_clsid_to_human.txt'
# synset_path = download_testdata(synset_url, synset_name, module='data')
synset_path = "./imagenet1000_clsid_to_human.txt"
with open(synset_path) as f:
synset = eval(f.read())
img= Image.open(img_path).resize((224, 224))
x = transform_image(img)
return x, synset
def img_test(mod, input_shape, ctx, params,img_path):
img, synset = get_transfer_img(img_path=img_path)
tvm_input = tvm.nd.array(img.astype('float32'))
mod.set_input('data', tvm_input)
mod.set_input(**params)
# execute
t1 =time.time()
mod.run()
t2 = time.time()
print("local_image_infer_time %s ms"%((t2-t1)*1000))
# get outputs
tvm_output = mod.get_output(0)
top1 = np.argmax(tvm_output.asnumpy()[0])
ftimer = mod.module.time_evaluator("run", ctx, number=1, repeat=10)
rof_res = np.array(ftimer().results) * 1000 # convert to millisecond
print("ave_time", np.mean(rof_res))
print('TVM prediction top-1:', top1, synset[top1])
def rpc_compiled_module(graph,lib,params,dir_path, ctx, is_armcpu = True):
if not os.path.exists(dir_path):
os.mkdir(dir_path)
##saved_to_localdisk
save_compiled_module(graph,lib,params, dir_path, rpc_model_save=True, is_armcpu = is_armcpu)
##
#lib_file = os.path.join(dir_path,"deploy_lib.so")
lib_file = temp.relpath("deploy_lib.so")
graph_file = temp.relpath('deploy_graph.json')
params_file = temp.relpath('deploy_param.params')
lib.export_library(lib_file, tvm.contrib.ndk.create_shared)
with open(graph_file,"w") as fo:
fo.write(graph)
with open(params_file,"wb") as fo:
fo.write(relay.save_param_dict(params))
#upload model
print('Run %s test ...'%(ctx))
remote.upload(lib_file)
remote.upload(graph_file)
remote.upload(params_file)
###
lib = remote.load_module("deploy_lib.so")
graph = open(graph_file).read()
params = bytearray(open(params_file, "rb").read())
# load parameters
mod =tvm.contrib.graph_runtime.create(graph, lib,ctx)
mod.load_params(params)
###
data_tvm = tvm.nd.array((np.random.uniform(size=input_shape)).astype('float32'))
mod.set_input('data', data_tvm)
# mod.set_input(**params)
# evaluate
logging.info("Evaluate inference time cost...")
ftimer = mod.module.time_evaluator("run", ctx, number=1, repeat=2)
prof_res = np.array(ftimer().results) * 1000 # convert to millisecond
logging.info("Mean inference time (std dev): %.2f ms (%.2f ms)" % (np.mean(prof_res), np.std(prof_res)))
#image_input
#test_result
img_path = "./elephant-299.jpg"
img, synset = get_transfer_img(img_path=img_path)
tvm_input = tvm.nd.array(img.astype('float32'))
mod.set_input('data', tvm_input)
# execute
t1 =time.time()
mod.run()
t2 = time.time()
print("image_infer_time %s ms"%((t2-t1)*1000))
# get outputs
tvm_output = mod.get_output(0)
top1 = np.argmax(tvm_output.asnumpy()[0])
print('TVM prediction top-1:', top1, synset[top1])
def save_compiled_module(graph,lib,params,dir_path, rpc_model_save = True, is_armcpu = True):
if not os.path.exists(dir_path):
os.mkdir(dir_path)
if is_armcpu:
lib_file = os.path.join(dir_path,"deploy_lib.so")
else:
lib_file = os.path.join(dir_path,"deploy_lib_opencl.so")
graph_file = os.path.join(dir_path,'deploy_graph.json')
params_file = os.path.join(dir_path,'deploy_param.params')
if rpc_model_save:
lib.export_library(lib_file, ndk.create_shared)
else:
lib.export_library(lib_file)
with open(graph_file,"w") as fo:
fo.write(graph)
with open(params_file,"wb") as fo:
fo.write(relay.save_param_dict(params))
print("rpc_model is saved on localdisk %s" %dir_path)
def load_module(dir_path,ctx=None,debug=False):
lib_file = os.path.join(dir_path,"deploy_lib.so")
graph_file = os.path.join(dir_path,'deploy_graph.json')
params_file = os.path.join(dir_path,'deploy_param.params')
# lib = tvm.module.load(lib_file)
lib = tvm.runtime.load_module(lib_file)
graph = open(graph_file).read()
params = bytearray(open(params_file, "rb").read())
# load parameters
if not debug:
module = tvm.contrib.graph_runtime.create(graph, lib, ctx) # Deploy Module
else:
module = tvm.contrib.debugger.debug_runtime.create(graph, lib,ctx)
module.load_params(params)
return module
def evaluate(mod,input_shape,ctx):
data_tvm = tvm.nd.array((np.random.uniform(size=input_shape)).astype('float32'))
mod.set_input('data', data_tvm)
# mod.set_input(**params)
# evaluate
logging.info("Evaluate inference time cost...")
ftimer = mod.module.time_evaluator("run", ctx, number=1, repeat=60)
prof_res = np.array(ftimer().results) * 1000 # convert to millisecond
logging.info("Mean inference time (std dev): %.2f ms (%.2f ms)" % (np.mean(prof_res), np.std(prof_res)))
if __name__ == '__main__':
mod,params,input_shape = get_mxnet_model('resnet18_v1', 1)
logging.info(mod['main'].astext(show_meta_data=False))
# Establish remote connection with target hardware
# Configure the quantization behavior
qconfig = qtz.qconfig(round_for_shift=True,
skip_conv_layers=[0],
nbit_input=8,
nbit_weight=8,
nbit_activation=8,
global_scale=8.0,
dtype_input='int8',
dtype_weight='int8',
#dtype_activation='int8',
store_lowbit_output=False,
debug_enabled_ops=None)
#reason to skip conv_layer :https://discuss.tvm.ai/t/skipping-first-layer-from-8-bit-quantization/4290
#mod= qtz.prerequisite_optimize(mod,params=params)
# logging.info(mod['main'].astext(show_meta_data=False))
###added_config_qtz
mod = quantize_relay_module(mod,params,qconfig)
###added_config_qtz
#autotvm_tune(mod['main'], params, target)
tracker = rpc.connect_tracker(tracker_host, tracker_port)
remote = tracker.request(key, priority=0,session_timeout=60)
if is_armcpu:
target = 'llvm -target=%s-linux-android' % arch
#note: v0.6.0, added -device=arm_cpu has error.
ctx = remote.cpu(0)
target_host1 = None
else:
target = 'opencl'
ctx = remote.cl(0)
target_host1 = 'llvm -target=%s-linux-android' % arch
graph, lib, params = build_module(mod, params, target, best_records= "tuning_resnet18v1.log", host= target_host1)
rpc_compiled_module(graph, lib, params, "model", ctx = ctx, is_armcpu = is_armcpu)
It will pass if I comment the line:
mod = quantize_relay_module(mod,params,qconfig)
TVM version: 0.7.dev0
Thanks for your help!