Problem
The ultimate goal of this RFC is to enable TVM to generate multiple kernels for operators with symbolic shapes. Currently, ops like conv2d and dense don’t support codegen for symbolic shapes. But it’s hard for a single kernel to achieve good performance universally under different shapes. Therefore, we need a mechanism in TVM to codegen and dispatch an op to different kernels based on runtime shapes.
Second, the current design of TOPI and autoTVM is overcomplicated which requires much effort to figure out and add new TOPI and autoTVM templates. The figure below depicts a high-level diagram of how a relay op is lowered to the actual implementation. The complicated dispatch logic has two major drawbacks: (a) it’s hard to find out which implementation is actually used for a target; (b) the test cases may not cover all the implementation in the TOPI.
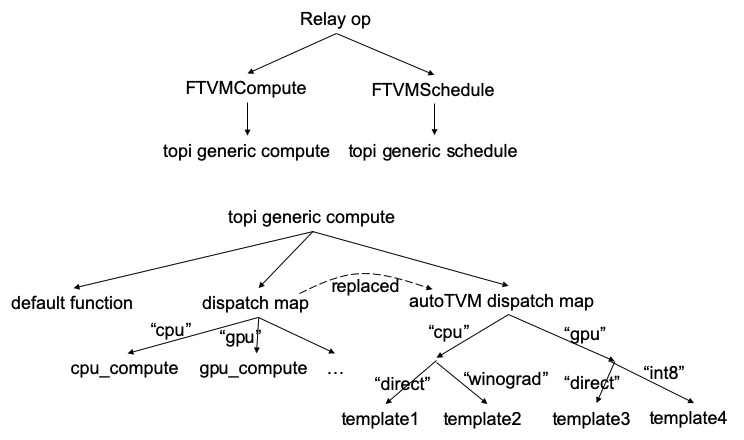
Third, template keys in autoTVM are used to represent different algorithms for op implementation, e.g., direct vs winograd for conv2d. But it has been abused to allow autoTVM to identify more templates. For example, “int8” is used as a template key, which seems inappropriate IMO.
Proposal
We propose to add FTVMStrategy function attr to Relay op that defines the kernel dispatch rules. Correspondingly we remove the dispatch logic from TOPI and remove the template key from autoTVM template to simplify the design. As a result, TOPI only contains a set of plain functions to define op compute and schedule for different targets, and some of which can be autoTVM templates. For instance, we can define compute/schedule function and autoTVM templates as follows:
def schedule_softmax(outs): ...
@autotvm.register_topi_compute("conv2d_nchw.x86") # autoTVM task name
def conv2d_nchw(cfg, data, kernel, strides, padding, dilation, layout, out_dtype): ...
@autotvm.register_topi_schedule("conv2d_nchw.x86") # autoTVM task name
def schedule_conv2d_nchw(cfg, outs): ...
Further, we don’t need to manually define autoTVM tasks for every template. What we need to do is to register compute and schedule template with the same unique autoTVM task name, then it can automatically match them together.
Now let’s look at the definition of FTVMStrategy. We define FTVMStrategy as a generic function, so that we can define different strategies for each target.
// Function signature:
// OpStrategy(const Attrs& attrs,
// const Array<Tensor>& inputs,
// const Type& out_type,
// const Target& target)
using FTVMStrategy = GenericFunc;
The data structure is defined as follows. We realize that in many cases, compute and schedule are highly coupled (e.g., conv2d in x86). Therefore, we use OpImplement that includes a pair of compute and schedule function to represent an op kernel implementation. Under each specialized condition (e.g., batch < 16), we can add multiple implementations with different priorities. Finally, an OpStrategy contains a set of specialization.
class OpImplementNode : public relay::ExprNode {
FTVMCompute fcompute;
FTVMSchedule fschedule;
Integer plevel;
};
class OpSpecialization : public relay::ExprNode {
Array<OpImplement> implements;
// could be undefined, indicating no condition required
SpecializedCondition condition;
};
class OpStrategyNode : public relay::ExprNode {
Array<OpSpecialization> specializations;
};
class OpStrategy : public relay::Expr {
void AddImplement(FTVMCompute fcompute,
FTVMSchedule fschedule,
int plevel);
};
The following figure shows the new codegen diagram. When compile engine encounters an op with concrete shapes, it collects all valid implementations, queries the autoTVM log if possible, and adopts the implementation with best performance or highest priority. If TVM compiles op with symbolic shape, it will generate multiple kernels, each corresponding to the implementation with highest priority under each specialized condition, and a dispatch kernel that invokes the corresponding kernel based on runtime shape. In the future, we should also enable auto-tuning for strategy and allow it to load config from file.
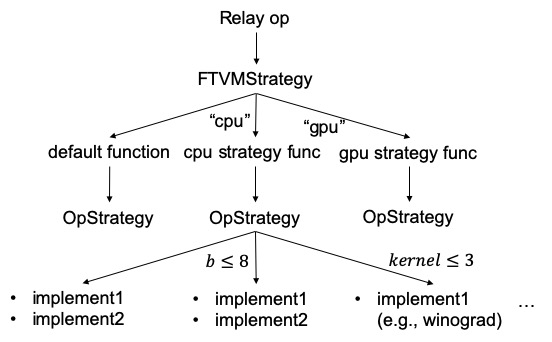
At last, the following code snippet shows two examples of how to define strategy. For simple ops like softmax and concatenate, which share the same compute across targets, we only need to register a schedule function for each target. Otherwise, the dense strategy shows a general case where we can define a more complicated strategy that uses different computes and schedules.
@schedule_softmax.register(["cuda", "gpu"])
def schedule_softmax(_, outs):
return topi.cuda.schedule_softmax(outs)
@dense_strategy.register("cpu")
def dense_strategy(attrs, inputs, out_type, target):
strategy = _op.OpStrategy()
m, k = inputs[0].shape
strategy.add_implement(wrap_compute_dense(topi.x86.dense_nopack),
wrap_topi_schedule(topi.x86.schedule_dense_nopack),
10)
if "cblas" in target.libs:
strategy.add_implement(wrap_compute_dense(topi.x86.dense_cblas),
wrap_topi_schedule(topi.x86.schedule_dense_cblas),
5)
with SpecializedCondition(k > 16):
strategy.add_implement(wrap_compute_dense(topi.x86.dense_pack),
wrap_topi_schedule(topi.x86.schedule_dense_pack))
return strategy
There are a few caveats for this change:
- NNVM compiler can no longer use TOPI since we only register the OpStrategy to Relay ops. It should be okay since NNVM compiler is already deprecated.
- Existing autoTVM logs cannot be used after this change as the workload name will be different.
I have a WIP implementation at https://github.com/icemelon9/tvm/tree/op-dispatch.
Since this is a significant change, let’s use this thread to discuss the design for some time.
@tqchen @kevinthesun @yzhliu @jroesch @comaniac @zhiics @ziheng @merrymercy @junrushao @masahi @eqy @ajtulloch