Both myself and @mbaret have been looking into a more robust way we can partition any directed acyclic graph for different compilers/backends. Below is what we came up with:
What’s wrong with the current partitioning algorithm?
Lack of support for sub-graphs with multiple outputs.
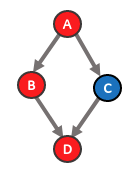
If multiple outputs were supported, the current algorithm wouldn’t be able to resolve data dependency issues, meaning that a graph can be partitioned in such a way that forms 2 (or more) uncomputable sub-graphs. For example the following graph (with each color representing a different compiler) will be partitioned incorrectly.
The result will be two sub-graphs: S1[A - B - D)] and S2[C]. However, this cannot be computed since S1 requires the output from S2 and S2 requires an output from S1. The correct way to partition the graph would be S1[A - B], S2[C], S3[D].
Our proposal
An algorithm which resolves these issues.
The principle behind resolving data dependency issues is the property that a data path which leaves a sub-graph cannot re-enter that sub-graph.
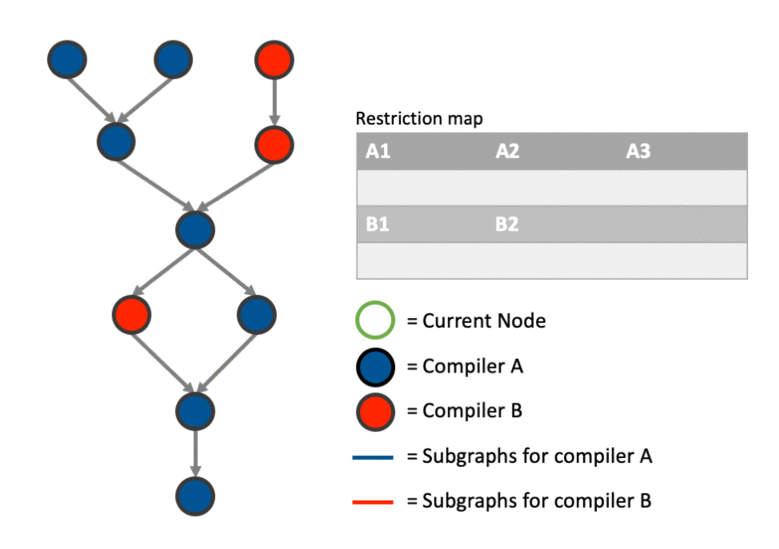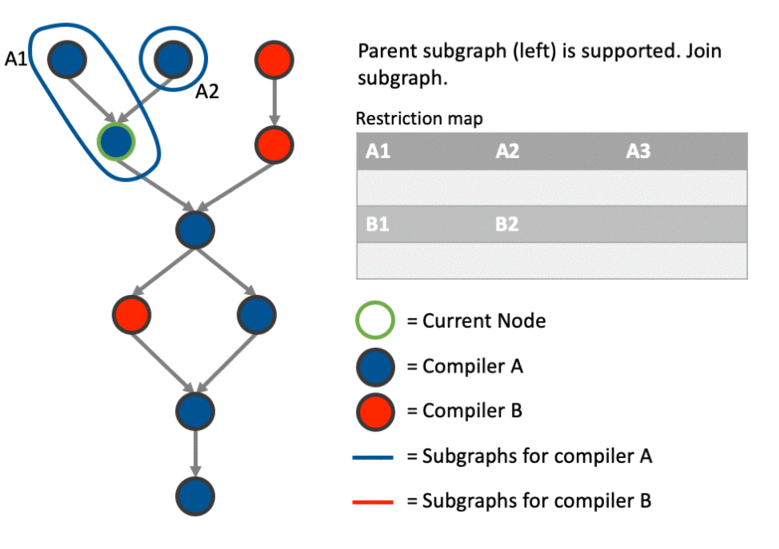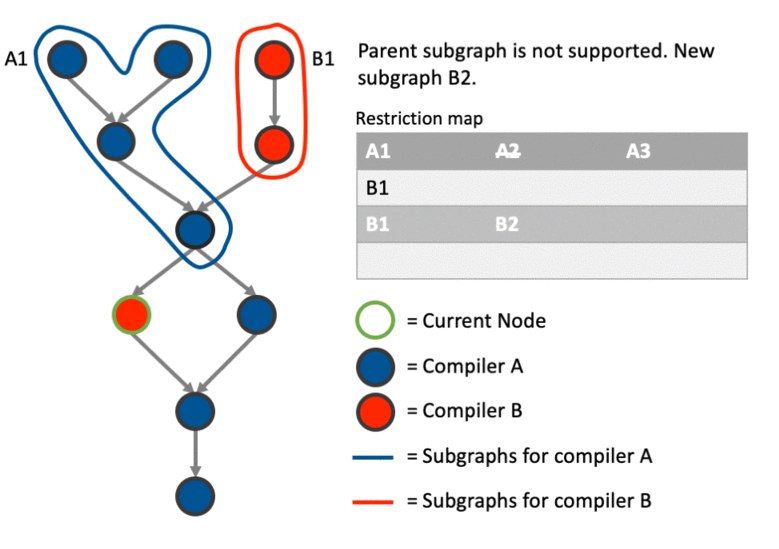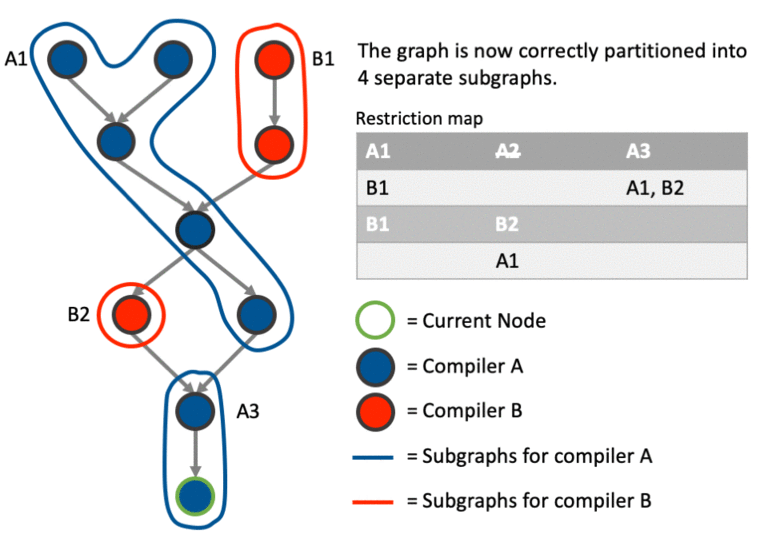
We start by recursively visiting each node in the input graph - starting at the graphs output nodes and only adding a node to a sub-graph once all its parents have sub-graphs assigned.
Once a node is encountered that can be added we create a set of all the sub-graphs the node is able to join:
Check whether any of the parent nodes sub-graphs are supported. The is-supported nature of each node will be taken care of by the annotation pass makes (this algorithm also opens up the possibility to annotate inline without a separate annotation pass).
We maintain a ‘restriction map’ which ensures the principle stated above isn’t violated. Once we have a set of supported sub-graphs we need to take away the sub-graphs that are restricted from one another.
Following the previous step, we can now add the current node to a sub-graph using one of 2 strategies:
Join an existing sub-graph (and then check if a merge is possible)
Create a new sub-graph
Due to the natural topological ordering of the recursive algorithm, the output is a series of sub-graphs that are correctly partitioned.
The restriction map
The restriction map is an unordered map that keeps track of sub-graphs as they are added and ensures that once a sub-graph has left it (and its parent sub-graphs) are no longer rejoined.
key - the sub-graph label that uniquely identifies a sub-graph in the graph.
value - a set containing other sub-graph labels that are restricted from joining the sub-graph represented by the key.
After a new sub-graph is joined or created for a particular node, the restriction map is updated so that the sub-graph just assigned is restricted from rejoining any other parent sub-graphs plus the inherited restrictions from those sub-graphs. Therefore, whenever a path leaves a sub-graph, it remembers it’s not allowed to reenter that sub-graph by adding the sub-graphs it has left as restrictions.
Example
The above much better explained with an example. This particular example shows how the graph can be partitioned correctly involving cases where we: create a new sub-graph, join an existing sub-graph, merge two sub-graphs after joining one and and deal with data dependencies using the restriction map.
@lhutton1 Its a very nice proposal. One additional fundamental element that should be somehow considered for a better graph partitioning algorithm is to take performance/profitability into account, i.e., it is not just about if the op is supported by a given compiler/device but also how efficient really is for that compiler/device when the op is supported by multiple compilers/devices on a system. The challenge is of course how can TVM be aware of this, but one way to do this is to give the user the possibility to provide some cost function or performance metric to TVM so that the graph partitioning algorithm can this into account. There are plenty of existing approaches that have addressed the problem of graph partitioning/mapping for heterogeneous systems that take performance/profitability into account.
Thanks @tico, we have briefly considered this and I believe, with the core function of the algorithm, it would be possible to implement something like this in the future. However, I think there are multiple hurdles we need to cross before we can get to this stage.
The graph partitioning problem could be tackled in a series of stages:
(the current implementation) sub-graphs where each one has only a single output with non-competing* back-end support for each op.
(our proposal) sub-graphs where each one has multiple outputs with non-competing* back-end support for each op.
(future) sub-graphs where each one has multiple outputs with competing* back-end support for each op.
* where competing means multiple backends where a prioritization order could not be determined.
Regarding existing approaches, do you have any references we could have a look at?
Great proposal! I have been an active user of MergeComposite and am looking forward to these improvements.
I agree with @tico in that we should design some way for AutoTVM to support finding optimal partitions, however I think that may be outside the scope of this RFC. I know there is ongoing work to extend AutoTVM up to the Relay level, but I’m not sure on the progress. @tico, do you happen to know?
The structure of AutoTVM doesn’t make it particularly well suited to partition optimization - I think we’d pretty much require a different tool altogether. There was at some point some effort put into a ‘graph tuner’ which may be more applicable, although I haven’t looked at it in detail.
I think determining the optimal set of partitions is outside of the scope here. This is simply about being able to produce partitions with arbitrarily many inputs/outputs in a valid way.
Thanks for the proposal. This algorithm is targeting to the subgraph merging problem that has not been covered at all in the current implementation. This is the next step we are planning to do after the op-based annotation PR has been merged, and this proposal also strengthens the motivation of op-based annotation (so guys, please help review and approve this PR).
I would like to first clarify the terms we are using so that we can discuss on the same page.
Graph annotation: Check if an op or a function can be supported by an external compiler, and insert compiler_begin, compiler_end to ops or functions.
Graph partitioning: For all ops/functions between compiler_begin and compiler_end, create a function with an attribute to indicate that it should be compiled and executed by an external compiler.
As can be seen, step 1 is the PR under review, and step 3 has been covered by the current graph partition pass. This proposal should be step 2, subgraph merging. Accordingly, here are some clarifications to the partition pass (step 3):
Assumption: Given a Relay graph with compiler_begin and compiler_end annotations. A pair of annotations can cover one or many nodes.
Function: Mutate the Relay graph to create function with proper arguments and attributes based on annotation pairs.
On the other hand, the cost function and AutoTVM are out of scope of this proposal. We should revisit that topic after all three steps are done and reasonably stable.
I think it is sensible to decouple the subgraph ‘merging’ from the partition creation. What I don’t understand is then if we have an explicit merging pass, what’s the purpose of the annotation pass?. That pass inserts the annotations depending on an op attribute, so it doesn’t actually add any new information into the graph. We could just as easily query the ‘is supported’ attribute directly in the merging pass (which is kind of implied in this RFC as no compiler annotations are mentioned explicitly).
Step 3. (as in the current implementation) has few issues in the current graph partition pass which I believe as follows :
It does not handle multiple outputs. It assumes that there will be a singular compiler_end for each such graph.
When a graph has such multiple outputs, it should make sure they are not ancestors of each other. (Thus, making the sub-graph not be able to computed, independently – highlighted as the data dependency problem in this RFC) – probably this could be handled in Step 2.
So I think Step 3 is not been covered by the current graph partition pass.
Moreover, it also raises the question is there a reason for Step 1 and Step 2 to exist without being followed by Step 3? In other words can we merge Step 3 into Step 2?
@mbaret You are right. We can actually only have merge pass and do something like is_supported. One of the reasons why we have the annotation pass was because we may have the case that an op can be used by different backends/compilers. There may be priorities then. We annotate it first to simplify logics like such scenarios so that the merging pass only needs to look at the information carried by the graph itself.
@manupa-arm You are right. Step 3 currently doesn’t cover multiple output and this is definitely a feature we should add.
Yes this should be handled by step 2 and you guys are welcome to contribute if available.
For merge step 2 and step 3, as @zhiics has mentioned, we hope the function for each pass to be simple and clear so that it is easy to maintain. We can consider to merge them later if we found that it’s necessary.
@zhiics I’m not sure if annotating single ops beforehand makes the merge pass simpler in the case of multiple backends. For instance, with this algorithm you can just check the ‘is supported’ method for each compiler you want to handle and have multiple types of subgraph (one type per backend). The main difficultly comes about in deciding which subgraphs to create when multiple backends support the same ops, and I don’t think that’s made easier by having explicit annotations present in the graph.
@comaniac I think the idea is that when we implement this merging pass, we’ll also make the necessary changes to the existing partitioning pass to support multiple outputs There may be an argument for fusing the passes together because in the merging pass we’ll have all the subgraphs already, but if we split it across two passes the first thing we’ll need to do is reconstruct the subgraphs from the compiler annotations. I need to think that through a bit more though.
@tqchen I think while this new infrastructure will be useful for merge composite/annotation, it probably won’t help with this particular algorithm as it can’t really be represented using pattern matching.
I do hope that the eventual algorithm can take the pattern language as input, so that graph partitioning can take considerations of descriptions like what is supported. It can be categorized as A3 as in [RFC][Relay] Program Matching for Relay Pt 1: A pattern language
@mbaret I just had a discussion with @zhiics and we agreed with you that annotating single ops beforehand is not necessary when this merging comes in. Since this algorithm has the exactly same input and output as the AnnotateTarget pass in our PR, how about you directly work on this pass? As a result, AnnotateTarget pass takes an original Relay graph and annotates compiler_begin, compiler_end based on the subgraphs identified by your algorithm. In this way, we can reuse user interfaces, and we believe this solution aligns the objectives from both of us.
@comaniac, @jonso, @mbaret I agree that optimal graph partitioning/mapping is out of the scope of this proposal. Nevertheless, it would be good to keep this mind so that it can be easily integrated in a future effort.
I have a performance related follow up question in the scope of the runtime, I was wondering if the partitions can be executed in parallel on different devices given that op dependencies allow it. Is this inter-op parallelism possible in the current TVM runtime or only inter-op parallelism is currently supported?
@tico Have a look at our proposal : [RFC][BYOC] An extended graph partitioning flow. I think the “optimal” graph partitioning/mapping could be easily plugged in as the “De-conflict” step that we are proposing (Although, we are currently proposing a generic simple greedy one). Moreover, I think finding the “optimal” is non-trivial because it will depend on lots of parameters of the backend. (e.g. supported layout, data movement costs, etc). Thus, our idea is to keep it open, so that a user could plug in a complex de-conflict pass to figure out the final disjoint set of subgraphs.
Hi,
Thanks for the nice animation and the work put into this.
I was wondering if the subgraph partitions for the same compiler (at this level) have any repercussions for downstream passes.
So for example assume that the last node of A1(called a1) is a Conv2d and the first of A3 (called a3) is an elemwise add.
Further assume that the “blue” compiler has a ‘very fast’ implementation of a Add(Tensor,Conv2d(Tensor)). This means that actually moving a1 into the A3 subgraph is a better option.
I guess this is similar to the previous concerns regarding the “optimal” subgraph partitioning, but without ‘many’ compilers. Since there is still only the “red” and “blue”
Hi, @aca88 I believe your example would be taken care of using the Merge Composite pass before partitioning. You can imagine that after running this pass add+conv2d for the blue compiler would be represented by a single node. The partitioning would then happen as you described. However, this would force this result, there is no consideration for the ‘optimal’ partitioning for the time being.
Currently there is ongoing work in the graph partitioning area. I don’t believe the new partitioning mechanism has support for Composite functions just yet, although this is something being looked into. @mbaret@manupa-arm may be able to comment more.
I believe your example would be taken care of using the Merge Composite pass before partitioning. You can imagine that after running this pass add+conv2d for the blue compiler would be represented by a single node.
Ok then I wasn’t really sure of what passes come before and after. So you are saying that Merge Composite would create a singe “blue” node (out of a1 and a3) which has a two incoming edges: