I try try to add vit model with llama. here is my some model code
@dataclass
class LlavaConfig:
def __init__(
self,
vision_image_size: int = 336,
vision_num_channels: int = 3,
vision_hidden_size: int = 1024,
vision_patch_size: int = 14,
vision_intermediate_size: int = 4096,
vision_num_hidden_layers: int = 24,
vision_num_attention_heads: int = 16,
vision_layer_norm_eps: float = 1e-5,
vision_image_path:str = "https://llava-vl.github.io/static/images/view.jpg",
mm_hidden_size: int = 1024,
dtype: str = "float16",
hidden_size: int = 1024,
feature_out_layer:int = -2,
**kwargs,
):
self.dtype = dtype
self.vision_image_size = vision_image_size
self.vision_num_channels = vision_num_channels
self.vision_hidden_size = vision_hidden_size
self.vision_patch_size = vision_patch_size
self.vision_intermediate_size = vision_intermediate_size
self.vision_num_hidden_layers = vision_num_hidden_layers
self.vision_num_attention_heads = vision_num_attention_heads
self.vision_layer_norm_eps = vision_layer_norm_eps
self.vision_image_path = vision_image_path
self.mm_hidden_size = mm_hidden_size
self.hidden_size = hidden_size
self.feature_out_layer = feature_out_layer
self.kwargs = kwargs
class Conv2D(nn.Module):
def __init__(self, in_features, out_features, kernel_size, strides, dtype, bias=False):
self.in_features = in_features
self.out_features = out_features
self.strides = strides
self.dtype = dtype
self.kernel_size = kernel_size
self.weight = nn.Parameter((out_features, in_features, kernel_size, kernel_size), dtype=dtype, name="conv2d_weight")
if bias:
self.bias = nn.Parameter((out_features,), dtype=dtype, name="conv2d_bias")
else:
self.bias = None
def forward(self, input: relax.Expr) -> relax.Var:
return nn.emit(relax.op.nn.conv2d(input, self.weight, self.strides))
class Embedding(nn.Module):
def __init__(self, num_embeddings, embedding_dim, dtype):
self.num_embeddings = num_embeddings
self.embedding_dim = embedding_dim
self.weight = nn.Parameter(
(num_embeddings, embedding_dim), dtype=dtype, name="embedding_weight"
)
def forward(self, x: relax.Expr) -> relax.Var:
ndim = x.struct_info.ndim
if ndim == 1:
return nn.emit(take(self.weight, x, axis=0))
x_shape = x.struct_info.shape.values
emb_size = self.weight.struct_info.shape.values[-1]
x = nn.emit(reshape(x, shape=[-1]))
embedding = nn.emit(take(self.weight, x, axis=0))
return nn.emit(reshape(embedding, [*x_shape, emb_size]))
class CLIPVisionEmbeddings(nn.Module):
def __init__(self, config:LlavaConfig):
super().__init__(self)
self.config = config
self.embed_dim = config.vision_hidden_size
self.vision_image_size = config.vision_image_size
self.vision_patch_size = config.vision_patch_size
self.num_patches = (self.vision_image_size // self.vision_patch_size) ** 2
self.num_positions = self.num_patches + 1
self.class_embedding = nn.Parameter((self.embed_dim,),dtype=config.dtype, name="clas_embedding")
self.position_ids = nn.Parameter(shape=(1, self.num_positions), dtype="int64", name="pos_embedding")
self.patch_embedding = Conv2D(
config.vision_num_channels,
self.embed_dim,
self.vision_patch_size,
strides=self.vision_patch_size,
bias=False,
dtype=config.dtype
)
self.position_embedding = Embedding(self.num_positions, self.embed_dim, dtype=config.dtype)
def forward(self, image):
batch_size = image.struct_info.shape.values[0]
patch_embeds = self.patch_embedding(image)
patch_embeds = nn.emit(reshape(patch_embeds, shape=(batch_size, self.embed_dim, -1)))
patch_embeds = nn.emit(permute_dims(patch_embeds, axes=(0,2,1)))
class_embeds = nn.emit(broadcast_to(self.class_embedding,shape=(batch_size,1,self.embed_dim)))
embeddings = nn.emit(concat([class_embeds, patch_embeds],axis=1))
import numpy as np
posi_ids = nn.emit(reshape(nn.emit(relax.const(np.arange(self.num_positions)), shape=(1, -1))))
batch_position_embedding = nn.emit(broadcast_to(self.position_embedding(posi_ids),shape=(batch_size,self.num_positions,self.embed_dim)))
embeddings = nn.emit(embeddings + batch_position_embedding)
return embeddings
and i create a func in llama.py
def create_vitembed_func(
bb: relax.BlockBuilder,
param_manager: ParamManager,
config: LlavaConfig,
quant_scheme: QuantizationScheme,
):
func_name = "vit_embed"
with bb.function(func_name):
model = CLIPVisionEmbeddings(config)
param_manager.register_params(model, func_name, quant_scheme, get_param_quant_kind)
image = nn.Placeholder((1, 3, 336, 336), dtype="float16", name="image")
with bb.dataflow():
features = model(image)
params = [features] + model.parameters()
gv = bb.emit_output(features)
bb.emit_func_output(gv, params)
mod = bb.get()
gv = mod.get_global_var(func_name)
bb.update_func(gv, mod[gv].with_attr("num_input", 1))
param_manager = ParamManager()
bb = relax.BlockBuilder()
llava_config = LlavaConfig()
create_vitembed_func(bb, param_manager, llava_config, args.quantization)
mod = bb.get()
for gv in mod.functions:
func = mod[gv]
report Duplicated object: lv28, but I unable to locate where it was wrong, In addition to this module, there are also many modules reporting the same error. I want to know how to locate or avoid this error.
e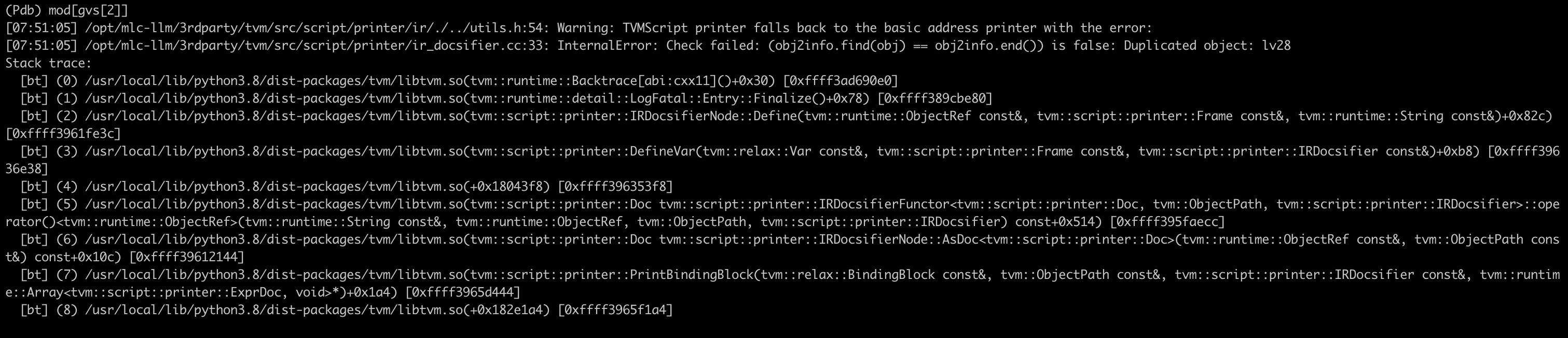
Thnaks for help!!!