Co-Authors: Ziheng Jiang (@ZihengJiang), Yuchen Jin (@YuchenJin), Denise Kutnick (@denise-k)
We wrote this post on behalf of many(names/ids in this post are listed alphabetically) who are participating in this effort.
- Relax is under open development, and we have many on-going active contributions from @hypercubestart, @Hzfengsy, @jinhongyii, @junrushao1994, @LeshengJin, @MasterJH5574, @psrivas2, @sunggg, @tqchen, @yongwww, @YuchenJin, @ZihengJiang. We also expect and welcome more people joining us this year.
- This post is based on the Relax Architecture Overview (co-authored by the following members of the TVM community: @altanh, @electriclilies, @hypercubestart, @jroesch, @junrushao1994, mbs-octoml, @mikepapadim, @tkonolige, @tqchen, @YuchenJin, @ZihengJiang). We will also update the design doc author list as people contribute to the project.
Introduction
In 2018, several members of the TVM community designed Relay around the key principles of expressibility, performance, and portability. Ever since then, Relay has been the core graph-level intermediate representation within TVM, and has been used in a diverse range of production use cases throughout the TVM community.
Over the years, machine learning workloads have evolved significantly, and newer architectures like transformers are pushing the limits of what Relay was originally designed to achieve. This led Relay’s creators and the rest of the TVM community to collectively ask: how can we evolve Relay to adapt to today’s workloads, while maintaining the key principles of expressibility, performance, and portability?
These ongoing community discussions resulted in several community-backed initiatives collectively known as TVM Unity. One key aspect of TVM Unity’s vision is to create a virtuous circle of innovation across TVM’s community of ML Researchers/Scientists, ML Systems Engineers, and Hardware Vendors, by unifying TVM across four categories of abstractions (computational graph, tensor program, libraries/runtimes, and hardware primitives) and enabling organic interactions between these layers.
This post describes Relax (Relay Next), an exploratory effort within TVM Unity which aims to evolve Relay to maximize expressibility, performance, and portability across today and tomorrow’s workloads. Relax is currently in an early prototype phase, is under open development, and has a growing community with 5+ organizations participating in weekly development meetings. The Relax community wants to bring added awareness and collect additional feedback from the wider TVM community on their technical vision, which involves the concept of first-class symbolic shape support across the four categories of abstractions mentioned above.
Key goals of Relax
Relax has three key goals motivated by the TVM community’s needs, and lessons the community has learned in ML acceleration through years of using and developing TVM.
G0: Build a unified interface that transcends the boundaries of TVM’s abstractions
TVM Unity describes multiple different community personas who contribute heavily to TVM’s overall success:
- ML Researchers/ML Scientists, whose goal is to greatly expand model coverage in TVM.
- ML Systems Engineers, whose goal is to radically simplify the optimization of emerging models and operators in TVM.
- Hardware Vendors, whose goal is to enable the best performance for their hardware while maintaining competitive and speedy time-to-market.
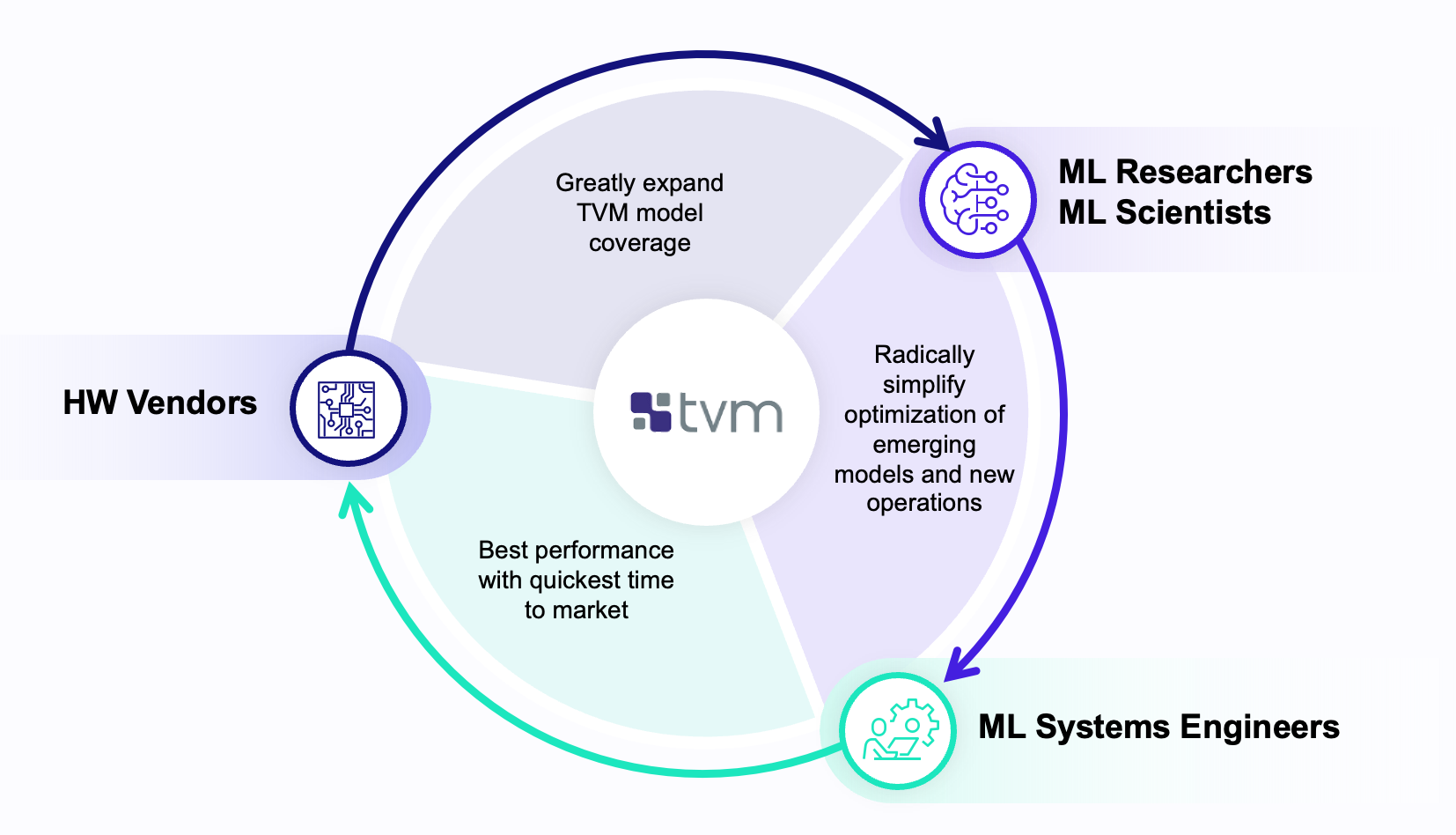
Historically, TVM has contained a clear boundary between abstractions, and operator lowering was performed in a single pass. However, this limits each of the TVM Unity personas in their ability to cross-reference multiple abstractions in the same workload, or use feedback from a different abstraction to inform optimization decisions. The TVM community has started to voice a strong need of these features. For example, multiple members of the community have suggested that the automation decisions in TensorIR should inform fusion and layout decisions at the high level. This feature is applicable towards TensorCore auto-scheduling as well as NPU related workloads. Relax aims to provide a holistic solution that allow us to represent and optimize the high-level and low-level IRs.
G1: Support and optimize dynamic shape workloads
Dynamic shape workloads contain at least one unknown dimension in at least one node of the computational graph at compile time. These workloads are ubiquitous across the ML ecosystem.
In Relay, the TVM community has observed many challenges in the development and deployment of dynamic shape workloads. Relay can only represent an unknown dimension of a tensor shape, which limits the ability to express certain types of dynamic shapes, and hinders the performance by pushing memory allocation and computations to the runtime. For instance, in transformer workloads, text inputs such as documents may have an arbitrary length, causing the sequence_length of the transformer to be a dynamic shape.
Relax brings substantial improvements on expressibility and portability of dynamic shape workloads with the addition of symbolic shape support. The Relax community believes that symbolic shape support is the first step towards unlocking performance in dynamic shape workloads as well.
Case0: fixed rank, symbolic shape case
In Relax, we want to have first-class support for symbolic integer shape to enable advanced optimizations.
For example, in the code snippets below, the input tensor a to a model has a dynamic batch size. The flatten operation takes all the dimensions of the input tensor a and reshapes them into a single-dimensional output tensor, b.
In Relay, the input tensor a’s batch size is represented as an unknown dimension, and since the computation of flatten requires knowledge of all dimensions, b is also an unknown shape. This causes loss of expressibility across large graphs, since known dimensions (such as the 224, 224, 3 in tensor a) are abstracted away once they are combined with unknown dimensions.
In Relax, the addition of symbolic shapes vastly improves the expressibility of dynamic shape loads. In the input tensor a, the dynamic batch size can be represented as a symbolic integer m, and the input tensor shape can be represented as (m, 224, 224, 3). After applying the flatten operation to a, the shape of the output tensor b can be represented as (m * 224 * 224 * 3, ).
# Relay vs. Relax: dynamic batch size on flatten operator
# Relay IR - no symbolic shapes
a: Tensor[(?, 224, 224, 3)]
b: Tensor[(?, )] = flatten(a)
# Relax IR - with symbolic shape
a: Tensor[(m, 224, 224, 3)]
b: Tensor[(m * 224 * 224 * 3, )] = flatten(a)
The knowledge of the shape relation between tensors provides more optimization opportunities (for more details, please refer to the Highlights section).
Case1: general cases
While fixed rank, dynamic symbolic shape covers most of the use cases, inevitably we also need to be able to cover all the general and fully dynamic cases, for example, when the rank of a tensor is unknown or when some operation (e.g., unique used to select the unique elements of a tensor) introduces data-dependent shape. It is important to have a “safety net” solution so that we cover the general cases.
G2: Support “computational graph” style optimizations with advanced dataflow semantics
Traditionally, machine learning workloads have been represented mathematically as sequential computational graphs of operations. Relay is currently modeled after computational graphs, which enables TVM’s developers to assume that computational graphs have no side effects on other parts of memory.
However, new machine learning workloads (such as transformers, RNNs, and training workloads) are more complex than a computational graph can represent. For instance, the backpropagation (backwards pass) step of training a transformer model results in updates to the model’s weights as training progresses. In a computational graph, the model’s weights would need to be copied in memory with each backwards pass, which is unnecessarily throughput-intensive. Relax provides flexibility over computational graphs, so that certain data (like model weights) can be updated in-place.
The in-place update example above is just one of many different advanced dataflow semantics that users may encounter as machine learning evolves. As machine learning engineers begin to use random number generation, state machines, and weight updates, TVM needs to be able to represent programs that contain control flow, in-place updates, and side effects. Relax aims to enable maximum expressibility for its users, whether they are using traditional computational graph semantics or advanced dataflow semantics.
Key Design Principles
Relax has three major design principles, which map directly to the three aforementioned goals of Relax.
For some additional context, the design of Relax follows the TVM Script vision outlined in the TVMCon 2021 keynote. The keynote interactively walks through the same code snippet that’s introduced in this section.
Below is a code snippet that motivates and demonstrates the key design principles of Relax. Note that TVM Script syntax is still evolving and is subject to change.
# This is TVM Script, a way to utilize the full power of TVM via Python.
import tvm.script
from tvm.script import relax as R, tir as T
@tvm.script.ir_module
class MyIRModule:
# This is a TIR PrimFunc which calls the TIR intrinsic T.exp.
@T.prim_func
def tir_exp_func(x: T.handle, y: T.handle): ## <= D2
X = T.match_buffer(x, (n,), "float32")
Y = T.match_buffer(y, (n,), "float32")
with T.grid(n) as i:
Y[i] = T.exp(X[i])
# This is a Relax function which contains a dataflow block
# representing a computational graph, as well as a call to an
# opaque packed function which performs an in-place update to the
# data in the variable gv0.
@R.function
def relax_func(x: R.Tensor[(n, k), "float32"], w: R.Tensor[_, "float32"]):
# n, k above are implicitly defined within the function signature
# so we will be able to refer to n, k within all of relax_func
with R.dataflow(): ## <= D2
lv0 = R.match_shape(w, (k, m)) ## <= D1
lv1: R.Tensor[(n, m), "float32"] = R.dot(x, lv0)
lv2: R.Tensor[(n * m,), "float32"] = R.flatten(lv1) ## <= D1
lv3: R.Shape = (n * m,) ## <= D1
gv0 = R.call_tir(tir_exp_func, [lv2], lv3, dtype="float32") ## <= D0
R.outputs(gv0)
R.call_packed("custom_inplace_update", gv0) ## <= D0, D2
return gv0
D0: Unified abstractions and optimizations across layers
The first key design decision we made is to allow the high-level IR to be able to directly interact and call into lower-level TensorIR and PackedFunc. We bring two intrinsics to bridge the gap.
The TensorIR functions and many external libraries adopt a destination passing convention(we need to explicitly allocate the output and pass it in as an argument to the function), so we introduce call_tir, which is an intrinsic that allows user to call a TIR function or a packed function in an immutable way. The second intrinsic we introduced is call_packed which indicates a call to a packed function.
from tvm.script import relax as R
@tvm.script.ir_module
class MyIRModule:
@T.prim_func
def tir_func(x: T.handle, y: T.handle):
n = T.var("n")
X = T.match_buffer(x, (n,), "float32")
Y = T.match_buffer(y, (n,), "float32")
with T.grid(n) as i:
Y[i] = T.exp(X[i])
@R.func
def relax_func(x: R.Tensor[(n, k), "float32"]):
with R.dataflow():
gv0 = R.call_tir(tir_func, [x], (n, k), dtype="float32")
R.outputs(gv0)
R.call_packed("custom_inplace_update", gv0)
return gv0
As you can see in the above program, with call_tir and call_packed, now we can embed a TIR function or packed function in the high-level relax program directly. This unlocks a lot of opportunities, including, but not limited to:
- Incrementally lower different parts of a program using different strategies.
- Allow automation(MetaSchedule) to take a call_tir node, perform optimizations and rewrite into multiple call_tir nodes that inform layout rewriting decisions to the high-level.
- Bring BYOC flow as natural part of transformation(by transforming parts of the graph into calls into opaque packed functions).
This also means the ML researchers, system engineers and hardware vendors can collaborate better, since we can optimize and lower a specific part of the whole program. The TIR & PackedFunc section of the Relax design doc provides additional context and implementation details for this design principle.
D1: Shape deduction as first-class computation
Shape deduction is essential to dynamic workloads. Under a dynamic shape setting, we usually need to compute the shapes of the intermediate tensors before running the computation. Additionally, we also need to handle cases where the shape itself is data-dependent (e.g. unique). Finally, most dynamic shape workloads still contain a lot of (partially) static shapes, ideally we want to take benefit of this static shape information for optimization.
from tvm.script import relax as R
@R.function
def shape_example(x: R.Tensor[(n, 2, 2), "float32"]):
with R.dataflow():
# symbolic and static shape deduction
lv0: R.Tensor[(n, 4), "float32"] = R.reshape(x, (n, 4))
lv1: R.Tensor[(n * 4,), "float32"] = R.flatten(lv0)
lv2: R.Shape = (n * 4,)
# external opaque shape function
lv3: R.Shape = R.call_packed("myshape_func", lv2)
lv4 = R.call_tir(lv3, "custom_func", [lv1], dtype="float32")
# data dependent case
lv5: R.Tensor[_, "float32"] = R.unique(lv4)
# re-match shape
lv6: R.Tensor[(m,), "float32"] = R.match_shape(lv5, (m,))
gv0: R.Tensor[(m,), "float32"] = R.exp(lv6)
R.outputs(gv0)
return gv0
The above program covers typical scenarios in shape deduction(marked in comments). Importantly, shape is now part of the computation along with Tensor values. This reflects the fact that the computation of shapes can happen at runtime.
While the text format type annotation lv0: R.Tensor[(n, 4), "float32"] shows the shape of each value, this is only syntactic sugar. From the IR’s point of view, the shape field (n, 4) is not included in the type signature of lv0. The type signature of lv0 is DynTensor(rank=2, dtype="float32"), the shape is a special value field that is attached to each Expr. We made this explicit choice to simplify the type inference so that we do not need to get into the full dependent type land.
Please refer to the Relax Shape Computation design doc for additional details.
D2: Dataflow block as a first-class construct
The majority of the relax_func code is encapsulated in a with R.dataflow() construct. All the operations under the dataflow block are side-effect-free and do not contain advanced control flows(such as if-then-else) or nested scopes.
A dataflow block can effectively be viewed as a computational graph embedded in the program. Note that most of the binding variables(lv0, lv1, lv2, lv3) within the dataflow block are “local”, which means they are only visible within the block. These variables can be viewed as “internal nodes” of the computational graph. We can mark a variable as output(gv0), in which case the variable will be visible in the latter part of the program. These output variables can be viewed as output nodes in the computational graph.
Note that R.call_packed("custom_inplace_update", gv0) is outside of the dataflow block. Anything that is outside of a dataflow block may have side effects. So we cannot perform optimizations such as reordering these bindings according to topological order unless we do more careful analysis. We expect most of the optimizations are graph rewriting, which happen at the dataflow block level, and most existing optimization passes in TVM could also be converted to the dataflow block level too. These optimizations can be done by ML engineers who are familiar with the computational graph concept. The ability to isolate and represent effectful components also provides opportunities for more advanced optimizations for the places that need them.
Highlights
The development of Relax is highly focused on verticals: connect the relevant key components across the stack together and unlock interesting capabilities. In this section, we summarize some highlights:
Incremental Development
Relax development follows the TVM Unity principles: cross-layer interactions and iterate rapidly. We first enable minimum build in which every transformation is IRModule ⇒ IRModule, and then leverage symbolic TE to construct workloads. For new features, we don’t need to hack through the entire stack, instead, we can quickly establish end-to-end cases with some parts manually, and then improve different components in parallel.
First-class Symbolic Shape Support
For example we have a “flatten” function to flatten a tensor, here is the symbolic shape representation in Relax:
a: Tensor[(m, 224, 224, 3)]
b: Tensor[(m * 2, 224, 224, 3)]
c: Tensor[(m * 3, 224, 224, 3)] = concatenate([a, b], axis=0)
In today’s Relay, we have ? to denote an unknown dimension. So the above program represented in Relay would be:
a: Tensor[(?, 224, 224, 3)]
b: Tensor[(?, 224, 224, 3)]
c: Tensor[(?, 224, 224, 3)] = concatenate([a, b], axis=0)
By having first-class symbolic shape support in Relax, we know m in the shapes of tensor a and tensor b are the same m, so we can deduce at compile time that a and b have the same memory size. This knowledge of shape relation between tensors gives us good optimization opportunities.
EmitTE: direct integration with TE/TOPI
In Relay, adding a custom operator is an 8-step process which requires developers to change code in both C++ and Python.
In Relax, we can reuse libraries such as TOPI for quick workload creation and operator lowering. The Relax-TE integration is very unique to Relax because the TE language in TVM is also based on symbolic shape, and Relax has symbolic shape as the first class, so Relax can directly integrate with TE and TOPI library.

As shown in the code above, the Relax block builder has a member function emit_te as highlighted in the program on the left, it can take a TE function and directly convert Relax variables for example the input and weight variables here to TE tensors, and emit a call_tir node which calls into a generated TIR PrimFunc according to the TE function. Bridging Relax and TIR is simple and clean given that Relax has symbolic shape as first class and the support for call_tir for cross-layer interactions. The EmitTE Staging Integration design doc provides additional context and implementation details on emit_te.
Development Plan and Success Criteria
Relax is in the early stages of development, and by following the vertical development approach, the Relax community plans to showcase end-to-end results on key dynamic and training workloads while building and scaling core infrastructure components. Below are some key development principles that the community plans to follow.
- Relax plans to reuse existing Relay infrastructure as much as possible, while building new capabilities into the IR. As a result, the community has created a parallel code path to accelerate the development process. In the coming weeks and months, the Relax community will start to have discussions with the broader TVM community about how we can more closely integrate Relax with TVM and Apache’s processes around development, CI, and testing.
- The Relax community is committed to following the high bar of quality set by the TVM community.
- Relax plans to have full functional compatibility with Relay: this means that workloads which are functional on Relay will also be functional on Relax, even though the infrastructure underneath may change.
- Relax plans to improve the expressibility and performance of Relay while maintaining the high level of portability that remains one of Relay’s strengths.
- Relax is under open development, and everyone is welcome to participate! Please check out the Relax repo and the Relax design docs. The Relax community actively monitors the issue page in the repo for discussions and issue/task tracking. All Relax related discussions happen in the Relax discord channel. We host a weekly open development meeting, please check out the agenda and add the meeting to your calendar if you are interested.
We are looking forward to hearing your comments! ![]()