Hi all, I want to do vectorize on local registers, but I found some redundant condition check that make it impossible to vectorize:
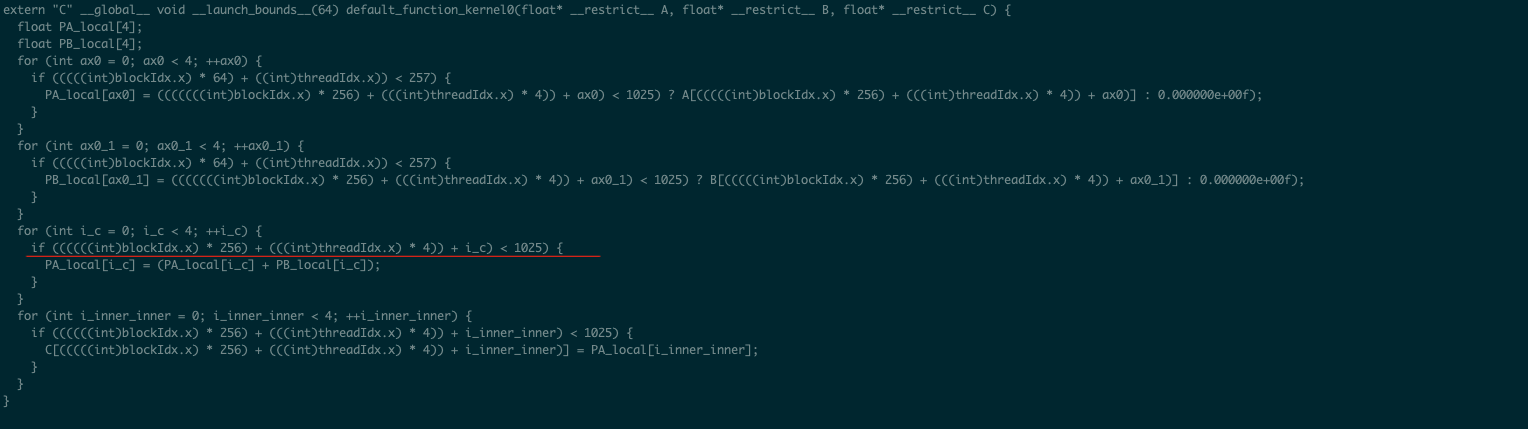
The highlighted condition check it obviously unnecessary. Can anyone help me to remove this condition check? Here is my code:
import tvm
from tvm import te
block_x = te.thread_axis("blockIdx.x")
thread_x = te.thread_axis("threadIdx.x")
def vectorize(M, target, dtype = 'float32'):
PM = (M + 4 - 1) // 4 * 4
A = te.placeholder((M, ), name = "A", dtype = dtype)
B = te.placeholder((M, ), name = "B", dtype = dtype)
PA = te.compute((PM, ), lambda i : tvm.tir.if_then_else(tvm.tir.all(i < M), A[i], tvm.tir.const(0.0, 'float32')), name = "PA")
PB = te.compute((PM, ), lambda i : tvm.tir.if_then_else(tvm.tir.all(i < M), B[i], tvm.tir.const(0.0, 'float32')), name = "PB")
C = te.compute((M, ), lambda i : PA[i] + PB[i], name = "C")
s = te.create_schedule(C.op)
s[PA].compute_inline()
s[PB].compute_inline()
lC = s.cache_write(C, "local")
lA = s.cache_read(PA, "local", [lC])
lB = s.cache_read(PB, "local", [lC])
m = C.op.axis[0]
mo, mi = s[C].split(m, 256)
mio, mii = s[C].split(mi, 4)
s[C].bind(mo, block_x)
s[C].bind(mio, thread_x)
s[lC].compute_at(s[C], mio)
s[lA].compute_at(s[C], mio)
s[lB].compute_at(s[C], mio)
func = tvm.build(s, [A, B, C], 'cuda')
print(func.imported_modules[0].get_source())
if __name__ == '__main__':
target = tvm.target.Target("cuda", host="c")
size = 1025
vectorize(size, target)