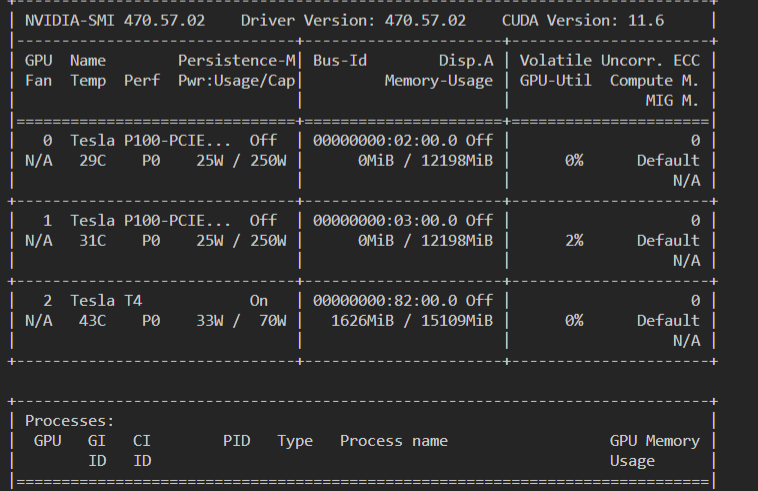
docker images: nvcr.io/nvidia/tensorrt:22.02-py3 device: Tesla T4
def @main(%data: Tensor[(32, 224, 224, 3), float32] /* ty=Tensor[(32, 224, 224, 3), float32] */, output_tensor_names=["resnet_v1_50_logits_BiasAdd"]) -> Tensor[(32, 1, 1, 1000), float32] {
%0 = qnn.quantize(%data, 1.07741f /* ty=float32 */, -13 /* ty=int32 */, out_dtype="int8") /* ty=Tensor[(32, 224, 224, 3), int8] */;
%1 = nn.pad(%0, -13f /* ty=float32 */, pad_width=[[0, 0], [3, 3], [3, 3], [0, 0]]) /* ty=Tensor[(32, 230, 230, 3), int8] */;
%2 = qnn.conv2d(%1, meta[relay.Constant][0] /* ty=Tensor[(7, 7, 3, 64), int8] */, -13 /* ty=int32 */, 0 /* ty=int32 */, 1.07741f /* ty=float32 */, meta[relay.Constant][1] /* ty=Tensor[(64), float32] */, strides=[2, 2], padding=[0, 0, 0, 0], channels=64, kernel_size=[7, 7], data_layout="NHWC", kernel_layout="HWIO", out_dtype="int32") /* ty=Tensor[(32, 112, 112, 64), int32] */;
%3 = nn.bias_add(%2, meta[relay.Constant][2] /* ty=Tensor[(64), int32] */, axis=3) /* ty=Tensor[(32, 112, 112, 64), int32] */;
%4 = qnn.requantize(%3, meta[relay.Constant][3] /* ty=Tensor[(64), float32] */, 0 /* ty=int32 */, 0.145316f /* ty=float32 */, -128 /* ty=int32 */, axis=3, out_dtype="int8") /* ty=Tensor[(32, 112, 112, 64), int8] */;
%5 = clip(%4, a_min=-128f, a_max=127f) /* ty=Tensor[(32, 112, 112, 64), int8] */;
%6 = nn.max_pool2d(%5, pool_size=[3, 3], strides=[2, 2], padding=[0, 0, 1, 1], layout="NHWC") /* ty=Tensor[(32, 56, 56, 64), int8] */;
%7 = qnn.conv2d(%6, meta[relay.Constant][4] /* ty=Tensor[(1, 1, 64, 256), int8] */, -128 /* ty=int32 */, 0 /* ty=int32 */, 0.145316f /* ty=float32 */, meta[relay.Constant][5] /* ty=Tensor[(256), float32] */, padding=[0, 0, 0, 0], channels=256, kernel_size=[1, 1], data_layout="NHWC", kernel_layout="HWIO", out_dtype="int32") /* ty=Tensor[(32, 56, 56, 256), int32] */;
%8 = nn.bias_add(%7, meta[relay.Constant][6] /* ty=Tensor[(256), int32] */, axis=3) /* ty=Tensor[(32, 56, 56, 256), int32] */;
%9 = qnn.conv2d(%6, meta[relay.Constant][8] /* ty=Tensor[(1, 1, 64, 64), int8] */, -128 /* ty=int32 */, 0 /* ty=int32 */, 0.145316f /* ty=float32 */, meta[relay.Constant][9] /* ty=Tensor[(64), float32] */, padding=[0, 0, 0, 0], channels=64, kernel_size=[1, 1], data_layout="NHWC", kernel_layout="HWIO", out_dtype="int32") /* ty=Tensor[(32, 56, 56, 64), int32] */;
%10 = nn.bias_add(%9, meta[relay.Constant][10] /* ty=Tensor[(64), int32] */, axis=3) /* ty=Tensor[(32, 56, 56, 64), int32] */;
%11 = qnn.requantize(%10, meta[relay.Constant][11] /* ty=Tensor[(64), float32] */, 0 /* ty=int32 */, 0.0539386f /* ty=float32 */, -128 /* ty=int32 */, axis=3, out_dtype="int8") /* ty=Tensor[(32, 56, 56, 64), int8] */;
%12 = clip(%11, a_min=-128f, a_max=127f) /* ty=Tensor[(32, 56, 56, 64), int8] */;
%13 = qnn.conv2d(%12, meta[relay.Constant][12] /* ty=Tensor[(3, 3, 64, 64), int8] */, -128 /* ty=int32 */, 0 /* ty=int32 */, 0.0539386f /* ty=float32 */, meta[relay.Constant][13] /* ty=Tensor[(64), float32] */, padding=[1, 1, 1, 1], channels=64, kernel_size=[3, 3], data_layout="NHWC", kernel_layout="HWIO", out_dtype="int32") /* ty=Tensor[(32, 56, 56, 64), int32] */;
%14 = nn.bias_add(%13, meta[relay.Constant][14] /* ty=Tensor[(64), int32] */, axis=3) /* ty=Tensor[(32, 56, 56, 64), int32] */;
%15 = qnn.requantize(%14, meta[relay.Constant][15] /* ty=Tensor[(64), float32] */, 0 /* ty=int32 */, 0.0495912f /* ty=float32 */, -128 /* ty=int32 */, axis=3, out_dtype="int8") /* ty=Tensor[(32, 56, 56, 64), int8] */;
%16 = clip(%15, a_min=-128f, a_max=127f) /* ty=Tensor[(32, 56, 56, 64), int8] */;
%17 = qnn.conv2d(%16, meta[relay.Constant][16] /* ty=Tensor[(1, 1, 64, 256), int8] */, -128 /* ty=int32 */, 0 /* ty=int32 */, 0.0495912f /* ty=float32 */, meta[relay.Constant][17] /* ty=Tensor[(256), float32] */, padding=[0, 0, 0, 0], channels=256, kernel_size=[1, 1], data_layout="NHWC", kernel_layout="HWIO", out_dtype="int32") /* ty=Tensor[(32, 56, 56, 256), int32] */;
%18 = nn.bias_add(%17, meta[relay.Constant][18] /* ty=Tensor[(256), int32] */, axis=3) /* ty=Tensor[(32, 56, 56, 256), int32] */;
when i compiled resnet50 model, the error may look like below:
extern "C" __global__ void __launch_bounds__(32) tvmgen_default_fused_cast_subtract_fixed_point_multiply_add_nn_conv2d_subtract_add_cast_multipl_91396e8651e5f5__4_kernel0(signed char* __restrict__ placeholder, signed char* __restrict__ placeholder1, signed char* __restrict__ compute, int* __restrict__ placeholder2, signed char* __restrict__ placeholder3, int* __restrict__ placeholder4, int* __restrict__ placeholder5, int* __restrict__ placeholder6, int64_t* __restrict__ placeholder7, int64_t* __restrict__ placeholder8, int64_t* __restrict__ placeholder9, int* __restrict__ placeholder10) {
nvcuda::wmma::fragment<nvcuda::wmma::accumulator, 16, 16, 16, int> Conv2dOutput_wmma_accumulator[1];
__shared__ half compute_shared[256];
__shared__ half compute_d_shared[256];
nvcuda::wmma::fragment<nvcuda::wmma::matrix_a, 16, 16, 16, half, nvcuda::wmma::row_major> compute_shared_wmma_matrix_a[1];
nvcuda::wmma::fragment<nvcuda::wmma::matrix_b, 16, 16, 16, half, nvcuda::wmma::row_major> compute_d_shared_wmma_matrix_b[1];
__shared__ int Conv2dOutput[256];
nvcuda::wmma::fill_fragment(Conv2dOutput_wmma_accumulator[0], 0.000000e+00f);
for (int rc_outer_outer = 0; rc_outer_outer < 16; ++rc_outer_outer) {
__syncthreads();
for (int ax0_ax3_fused_outer_outer_outer_outer = 0; ax0_ax3_fused_outer_outer_outer_outer < 8; ++ax0_ax3_fused_outer_outer_outer_outer) {
compute_shared[((ax0_ax3_fused_outer_outer_outer_outer * 32) + ((int)threadIdx.x))] = ((half)placeholder[((((((((int)blockIdx.x) * 802816) + (ax0_ax3_fused_outer_outer_outer_outer * 100352)) + ((((int)threadIdx.x) >> 4) * 50176)) + (((int)blockIdx.z) * 256)) + (rc_outer_outer * 16)) + (((int)threadIdx.x) & 15))]);
}
for (int ax2_ax3_fused_outer_outer_outer_outer = 0; ax2_ax3_fused_outer_outer_outer_outer < 8; ++ax2_ax3_fused_outer_outer_outer_outer) {
compute_d_shared[((ax2_ax3_fused_outer_outer_outer_outer * 32) + ((int)threadIdx.x))] = ((half)placeholder1[(((((rc_outer_outer * 16384) + (ax2_ax3_fused_outer_outer_outer_outer * 2048)) + ((((int)threadIdx.x) >> 4) * 1024)) + (((int)blockIdx.y) * 16)) + (((int)threadIdx.x) & 15))]);
}
__syncthreads();
nvcuda::wmma::load_matrix_sync(compute_shared_wmma_matrix_a[0], (&(compute_shared[0])), 16);
nvcuda::wmma::load_matrix_sync(compute_d_shared_wmma_matrix_b[0], (&(compute_d_shared[0])), 16);
nvcuda::wmma::mma_sync(Conv2dOutput_wmma_accumulator[0], compute_shared_wmma_matrix_a[0], compute_d_shared_wmma_matrix_b[0], Conv2dOutput_wmma_accumulator[0]);
}
nvcuda::wmma::store_matrix_sync((&(Conv2dOutput[0])), Conv2dOutput_wmma_accumulator[0], 16, nvcuda::wmma::mem_row_major);
__syncthreads();
for (int i0_inner_i3_inner_fused_outer_outer_outer_outer = 0; i0_inner_i3_inner_fused_outer_outer_outer_outer < 8; ++i0_inner_i3_inner_fused_outer_outer_outer_outer) {
compute[((((((((int)blockIdx.x) * 3211264) + (i0_inner_i3_inner_fused_outer_outer_outer_outer * 401408)) + ((((int)threadIdx.x) >> 4) * 200704)) + (((int)blockIdx.z) * 1024)) + (((int)blockIdx.y) * 16)) + (((int)threadIdx.x) & 15))] = max(min(((signed char)max(min(((((placeholder2[0] * 2) + ((int)(((((0 != 0) ? (((int64_t)(((int)placeholder3[((((((((int)blockIdx.x) * 3211264) + (i0_inner_i3_inner_fused_outer_outer_outer_outer * 401408)) + ((((int)threadIdx.x) >> 4) * 200704)) + (((int)blockIdx.z) * 1024)) + (((int)blockIdx.y) * 16)) + (((int)threadIdx.x) & 15))]) - placeholder4[0])) << ((int64_t)0)) : ((int64_t)(((int)placeholder3[((((((((int)blockIdx.x) * 3211264) + (i0_inner_i3_inner_fused_outer_outer_outer_outer * 401408)) + ((((int)threadIdx.x) >> 4) * 200704)) + (((int)blockIdx.z) * 1024)) + (((int)blockIdx.y) * 16)) + (((int)threadIdx.x) & 15))]) - placeholder4[0]))) * (int64_t)2146528297) + ((int64_t)1 << ((int64_t)((0 + 31) - 1)))) >> ((int64_t)(0 + 31))))) + ((int)(((((1 != 0) ? (((int64_t)(((int)((signed char)max(min((((int)(((((((int64_t)Conv2dOutput[((i0_inner_i3_inner_fused_outer_outer_outer_outer * 32) + ((int)threadIdx.x))]) + ((int64_t)placeholder5[((((int)blockIdx.y) * 16) + (((int)threadIdx.x) & 15))])) - ((int64_t)placeholder6[((((int)blockIdx.y) * 16) + (((int)threadIdx.x) & 15))])) * placeholder7[((((int)blockIdx.y) * 16) + (((int)threadIdx.x) & 15))]) + placeholder8[((((int)blockIdx.y) * 16) + (((int)threadIdx.x) & 15))]) >> placeholder9[((((int)blockIdx.y) * 16) + (((int)threadIdx.x) & 15))])) - 31), 127), -128))) - placeholder10[0])) << ((int64_t)1)) : ((int64_t)(((int)((signed char)max(min((((int)(((((((int64_t)Conv2dOutput[((i0_inner_i3_inner_fused_outer_outer_outer_outer * 32) + ((int)threadIdx.x))]) + ((int64_t)placeholder5[((((int)blockIdx.y) * 16) + (((int)threadIdx.x) & 15))])) - ((int64_t)placeholder6[((((int)blockIdx.y) * 16) + (((int)threadIdx.x) & 15))])) * placeholder7[((((int)blockIdx.y) * 16) + (((int)threadIdx.x) & 15))]) + placeholder8[((((int)blockIdx.y) * 16) + (((int)threadIdx.x) & 15))]) >> placeholder9[((((int)blockIdx.y) * 16) + (((int)threadIdx.x) & 15))])) - 31), 127), -128))) - placeholder10[0]))) * (int64_t)1535227812) + ((int64_t)1 << ((int64_t)((0 + 31) - 1)))) >> ((int64_t)(0 + 31))))) + 128), 127), -128)), (signed char)127), (signed char)-128);
}
}
Compilation error:
/tmp/tmp3r39a6ad/my_kernel.cu(357): error: no instance of overloaded function "nvcuda::wmma::mma_sync" matches the argument list
argument types are: (nvcuda::wmma::fragment<nvcuda::wmma::accumulator, 16, 16, 16, int, void>, nvcuda::wmma::fragment<nvcuda::wmma::matrix_a, 16, 16, 16, __half, nvcuda::wmma::row_major>, nvcuda::wmma::fragment<nvcuda::wmma::matrix_b, 16, 16, 16, __half, nvcuda::wmma::row_major>, nvcuda::wmma::fragment<nvcuda::wmma::accumulator, 16, 16, 16, int, void>)