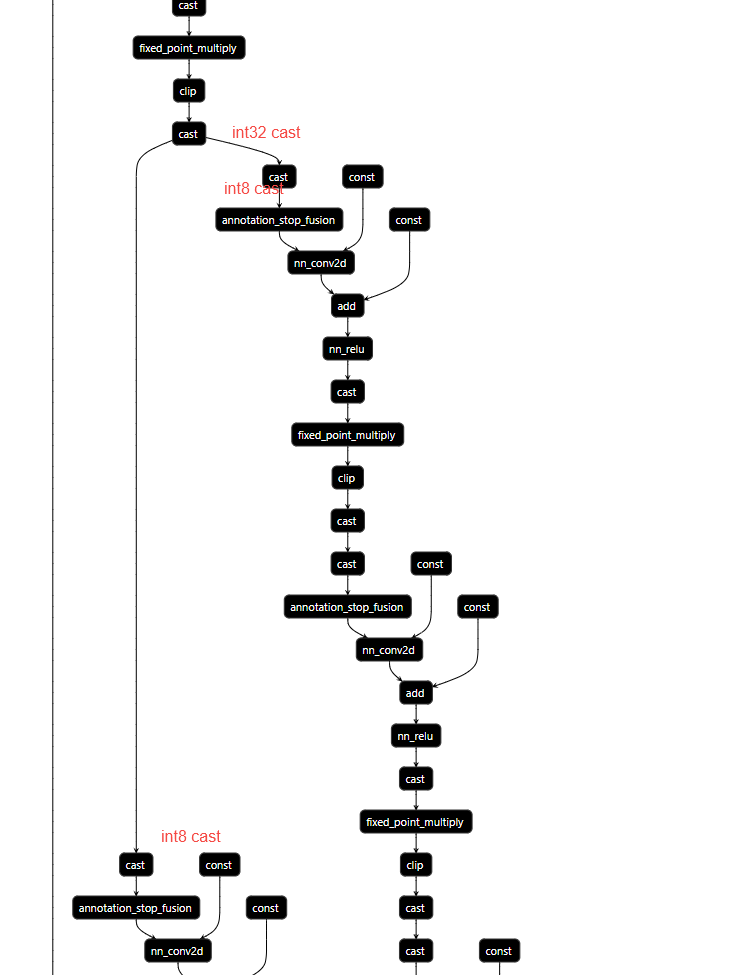
Below IR, %586 will produce int32 output, the output will be used in two branches. Each branch has a cast op, to cast the input to int8. I want make the two branch into one branch, so that the output could fuse the cast output to int8. make fewer op invocations.
As I know, pass like combine_paralle_dense helps to merge 3 branch conv to 1 conv. Could I reuse the pass to make paralle cast to one cast ? Or any other good choose pass ?
%586 = fn (%p098: Tensor[(16, 64, 112, 112), int8], %p179: Tensor[(64, 1, 1), int32], Primitive=1, hash="b07808ae4c39a75b", layout="NCHW", out_layout="") -> Tensor[(16, 64, 56, 56), int32] {
%562 = nn.max_pool2d(%p098, pool_size=[3, 3], strides=[2, 2], padding=[1, 1, 1, 1]) /* ty=Tensor[(16, 64, 56, 56), int8] */;
%563 = cast(%562, dtype="int32") /* ty=Tensor[(16, 64, 56, 56), int32] */;
%564 = fixed_point_multiply(%563, multiplier=0, shift=0) /* ty=Tensor[(16, 64, 56, 56), int32] */;
%565 = add(%564, %p179) /* ty=Tensor[(16, 64, 56, 56), int32] */;
%566 = nn.relu(%565) /* ty=Tensor[(16, 64, 56, 56), int32] */;
%567 = cast(%566, dtype="int64") /* ty=Tensor[(16, 64, 56, 56), int64] */;
%568 = fixed_point_multiply(%567, multiplier=0, shift=0) /* ty=Tensor[(16, 64, 56, 56), int64] */;
%569 = clip(%568, a_min=-127f, a_max=127f) /* ty=Tensor[(16, 64, 56, 56), int64] */;
cast(%569, dtype="int32") /* ty=Tensor[(16, 64, 56, 56), int32] */
};
%587 = %586(%585, meta[relay.Constant][2] /* ty=Tensor[(64, 1, 1), int32] */) /* ty=Tensor[(16, 64, 56, 56), int32] */;
%588 = fn (%p097: Tensor[(16, 64, 56, 56), int32], Primitive=1, hash="fa643999fd987de1") -> Tensor[(16, 64, 56, 56), int8] {
cast(%p097, dtype="int8") /* ty=Tensor[(16, 64, 56, 56), int8] */
};
%589 = %588(%587) /* ty=Tensor[(16, 64, 56, 56), int8] */;
%600 = fn (%p0102: Tensor[(16, 64, 56, 56), int32], Primitive=1, hash="fa643999fd987de1") -> Tensor[(16, 64, 56, 56), int8] {
cast(%p0102, dtype="int8") /* ty=Tensor[(16, 64, 56, 56), int8] */
};
%601 = %600(%587) /* ty=Tensor[(16, 64, 56, 56), int8] */;