
Hey, guys. Suppose I have a subgraph with about at least 50+ ops. I want to fuse them into one op.
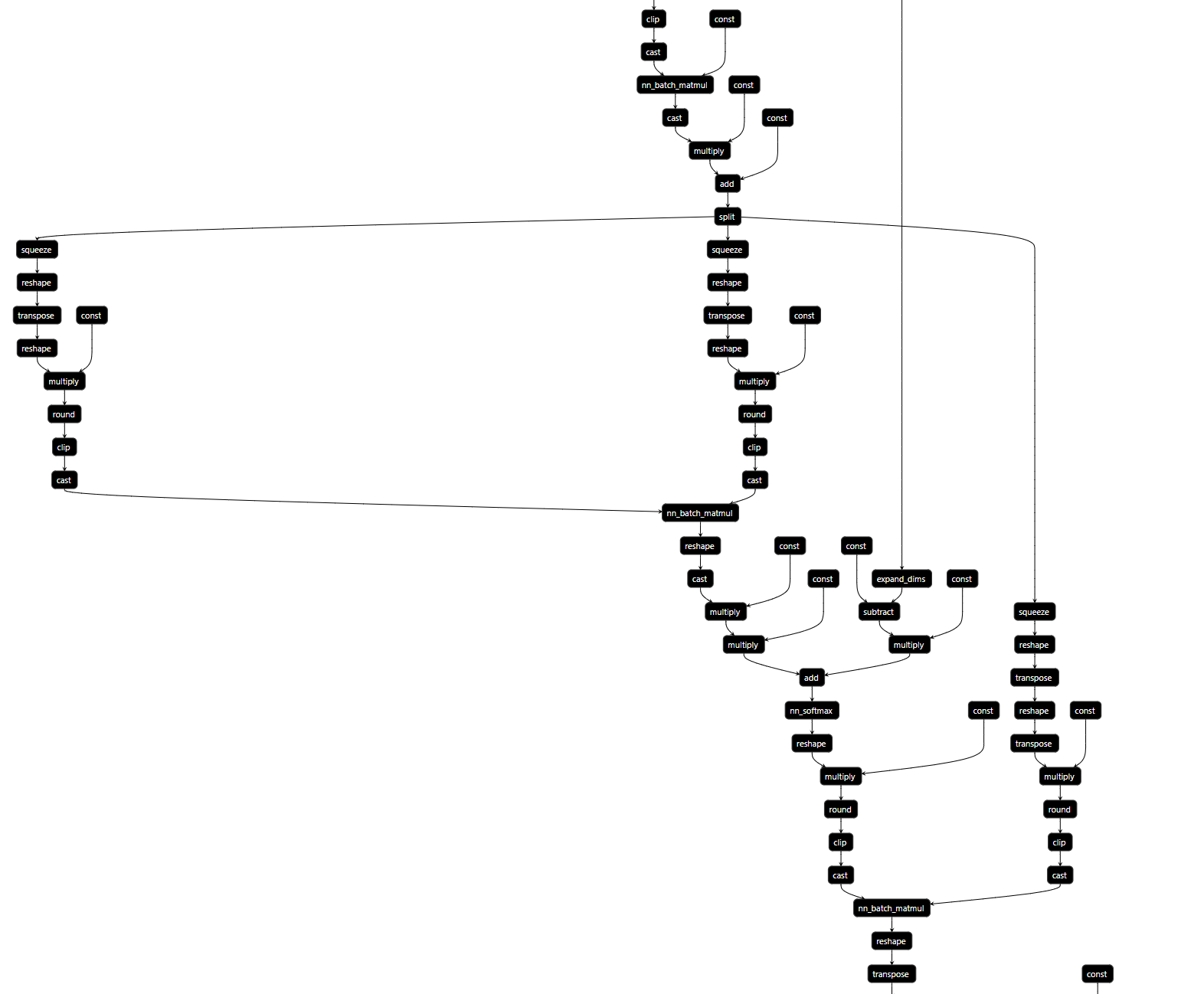
The fused op may be MultiHeadAttention, In origin graph, it may have few ops.
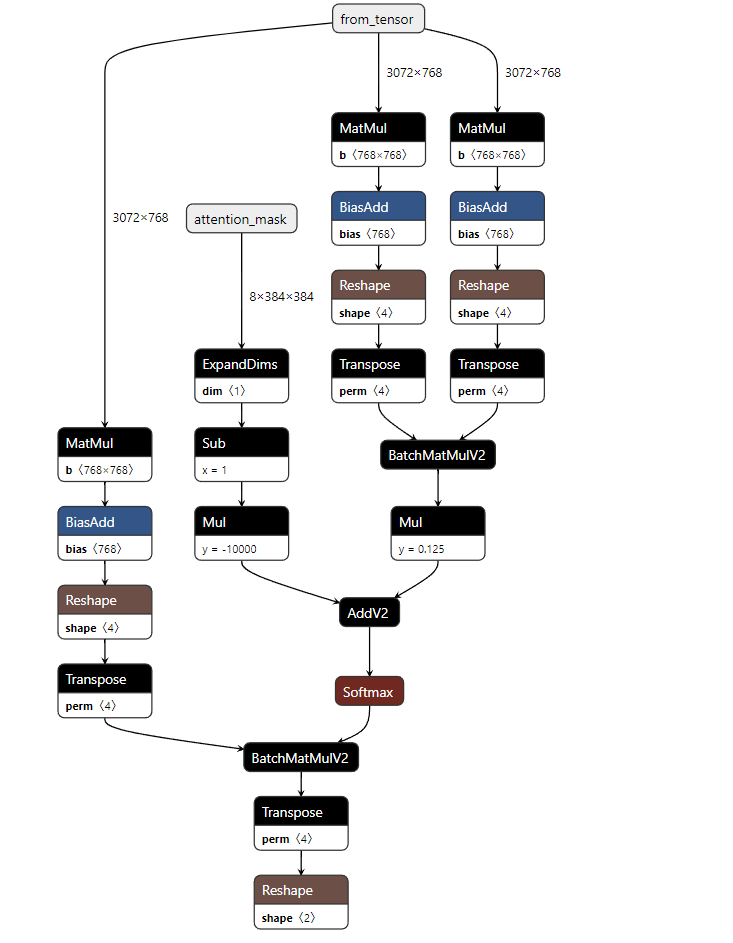
But if tvm quantize the model, as both we all know the dequantize and quantize are composed of trival ops, like multiply, cast and round etc.
I tried to use dominates to match pattern. dominates pattern needs begin node pattern, path node pattern, end node pattern.
So in this graph, I choose begin node pattern as is_op('split')(None), path node pattern wildcard()(None), end node pattern is_op('transpose')(None)
class FusedMutiHeadAttentionTmpRewriter(DFPatternCallback):
def __init__(self, require_type=False, rewrite_once=False):
super().__init__(require_type, rewrite_once)
'''
%20 = cast(%19, dtype="float32") /* ty=Tensor[(3, 3072, 768), float32] */;
%21 = multiply(%20, 0.000488281f /* ty=float32 */) /* ty=Tensor[(3, 3072, 768), float32] */;
%22 = add(%21, meta[relay.Constant][6] /* ty=Tensor[(3, 1, 768), float32] */) /* ty=Tensor[(3, 3072, 768), float32] */;
%23 = split(%22, indices_or_sections=3) /* ty=(Tensor[(1, 3072, 768), float32], Tensor[(1, 3072, 768), float32], Tensor[(1, 3072, 768), float32]) */;
%24 = %23.0;
%25 = squeeze(%24, axis=[0]) /* ty=Tensor[(3072, 768), float32] */;
%26 = reshape(%25, newshape=[8, 384, 12, 64]) /* bert/encoder/layer_0/attention/self/Reshape */ /* ty=Tensor[(8, 384, 12, 64), float32] */;
%27 = transpose(%26, axes=[0, 2, 1, 3]) /* bert/encoder/layer_0/attention/self/transpose */ /* ty=Tensor[(8, 12, 384, 64), float32] */;
%28 = reshape(%27, newshape=[96, 384, 64]) /* ty=Tensor[(96, 384, 64), float32] */;
%29 = multiply(%28, 16f /* ty=float32 */) /* ty=Tensor[(96, 384, 64), float32] */;
%30 = round(%29) /* ty=Tensor[(96, 384, 64), float32] */;
%31 = clip(%30, a_min=-127f, a_max=127f) /* ty=Tensor[(96, 384, 64), float32] */;
%32 = %23.1;
%33 = squeeze(%32, axis=[0]) /* ty=Tensor[(3072, 768), float32] */;
%34 = reshape(%33, newshape=[8, 384, 12, 64]) /* bert/encoder/layer_0/attention/self/Reshape_1 */ /* ty=Tensor[(8, 384, 12, 64), float32] */;
%35 = transpose(%34, axes=[0, 2, 1, 3]) /* bert/encoder/layer_0/attention/self/transpose_1 */ /* ty=Tensor[(8, 12, 384, 64), float32] */;
%36 = reshape(%35, newshape=[96, 384, 64]) /* ty=Tensor[(96, 384, 64), float32] */;
%37 = multiply(%36, 16f /* ty=float32 */) /* ty=Tensor[(96, 384, 64), float32] */;
%38 = round(%37) /* ty=Tensor[(96, 384, 64), float32] */;
%39 = clip(%38, a_min=-127f, a_max=127f) /* ty=Tensor[(96, 384, 64), float32] */;
%40 = cast(%31, dtype="int8") /* ty=Tensor[(96, 384, 64), int8] */;
%41 = cast(%39, dtype="int8") /* ty=Tensor[(96, 384, 64), int8] */;
%42 = nn.batch_matmul(%40, %41, out_dtype="int32", transpose_b=True) /* ty=Tensor[(96, 384, 384), int32] */;
%43 = reshape(%42, newshape=[8, 12, 384, 384]) /* ty=Tensor[(8, 12, 384, 384), int32] */;
%44 = cast(%43, dtype="float32") /* ty=Tensor[(8, 12, 384, 384), float32] */;
%45 = multiply(%44, 0.00390625f /* ty=float32 */) /* ty=Tensor[(8, 12, 384, 384), float32] */;
%46 = reshape(%input_mask, newshape=[8, 1, 384]) /* bert/encoder/Reshape */ /* ty=Tensor[(8, 1, 384), int32] */;
%47 = cast(%46, dtype="float32") /* bert/encoder/Cast */ /* ty=Tensor[(8, 1, 384), float32] */;
%48 = multiply(meta[relay.Constant][7] /* ty=Tensor[(8, 384, 1), float32] */, %47) /* bert/encoder/mul */ /* ty=Tensor[(8, 384, 384), float32] */;
%49 = expand_dims(%48, axis=1) /* bert/encoder/layer_0/attention/self/ExpandDims */ /* ty=Tensor[(8, 1, 384, 384), float32] */;
%50 = subtract(1f /* ty=float32 */, %49) /* bert/encoder/layer_0/attention/self/sub */ /* ty=Tensor[(8, 1, 384, 384), float32] */;
%51 = multiply(%45, 0.125f /* ty=float32 */) /* bert/encoder/layer_0/attention/self/Mul */ /* ty=Tensor[(8, 12, 384, 384), float32] */;
%52 = multiply(%50, -10000f /* ty=float32 */) /* bert/encoder/layer_0/attention/self/mul_1 */ /* ty=Tensor[(8, 1, 384, 384), float32] */;
%53 = add(%51, %52) /* bert/encoder/layer_0/attention/self/add */ /* ty=Tensor[(8, 12, 384, 384), float32] */;
%54 = nn.softmax(%53) /* bert/encoder/layer_0/attention/self/Softmax */ /* ty=Tensor[(8, 12, 384, 384), float32] */;
%55 = reshape(%54, newshape=[96, 384, 384]) /* ty=Tensor[(96, 384, 384), float32] */;
%56 = multiply(%55, 16f /* ty=float32 */) /* ty=Tensor[(96, 384, 384), float32] */;
%57 = round(%56) /* ty=Tensor[(96, 384, 384), float32] */;
%58 = clip(%57, a_min=-127f, a_max=127f) /* ty=Tensor[(96, 384, 384), float32] */;
%59 = %23.2;
%60 = squeeze(%59, axis=[0]) /* ty=Tensor[(3072, 768), float32] */;
%61 = reshape(%60, newshape=[8, 384, 12, 64]) /* bert/encoder/layer_0/attention/self/Reshape_2 */ /* ty=Tensor[(8, 384, 12, 64), float32] */;
%62 = transpose(%61, axes=[0, 2, 1, 3]) /* bert/encoder/layer_0/attention/self/transpose_2 */ /* ty=Tensor[(8, 12, 384, 64), float32] */;
%63 = reshape(%62, newshape=[96, 384, 64]) /* ty=Tensor[(96, 384, 64), float32] */;
%64 = transpose(%63, axes=[0, 2, 1]) /* ty=Tensor[(96, 64, 384), float32] */;
%65 = multiply(%64, 16f /* ty=float32 */) /* ty=Tensor[(96, 64, 384), float32] */;
%66 = round(%65) /* ty=Tensor[(96, 64, 384), float32] */;
%67 = clip(%66, a_min=-127f, a_max=127f) /* ty=Tensor[(96, 64, 384), float32] */;
%68 = cast(%58, dtype="int8") /* ty=Tensor[(96, 384, 384), int8] */;
%69 = cast(%67, dtype="int8") /* ty=Tensor[(96, 64, 384), int8] */;
%70 = nn.batch_matmul(%68, %69, out_dtype="int32", transpose_b=True) /* ty=Tensor[(96, 384, 64), int32] */;
%71 = reshape(%70, newshape=[8, 12, 384, 64]) /* ty=Tensor[(8, 12, 384, 64), int32] */;
%72 = transpose(%71, axes=[0, 2, 1, 3]) /* ty=Tensor[(8, 384, 12, 64), int32] */;
%73 = reshape(%72, newshape=[3072, 768]) /* ty=Tensor[(3072, 768), int32] */;
'''
self.is_split = is_op("split")(None)
self.is_anyop = (wildcard())(None)
self.is_transpose = is_op("transpose")(None)
diamond = dominates(self.is_split, self.is_anyop, self.is_transpose)
self.pattern = diamond
def callback(self, pre, post, node_map):
# import pdb
# pdb.set_trace()
return relay.nn.relu(node_map[self.is_split][0])
no hit the breakpoint. I thought dominates may help, but …
any one cound give some advise about how to fuse these op?
In our HW, tvm split op into many ops. as opposed to tensorrt, bert-base we got 450+ kernel but tensorrt 81. Allthough, out HW may faster than tensorrt, but kernel lauch costs too much.