
Does TVM has the pass to fuse pad + conv2d in to one op.
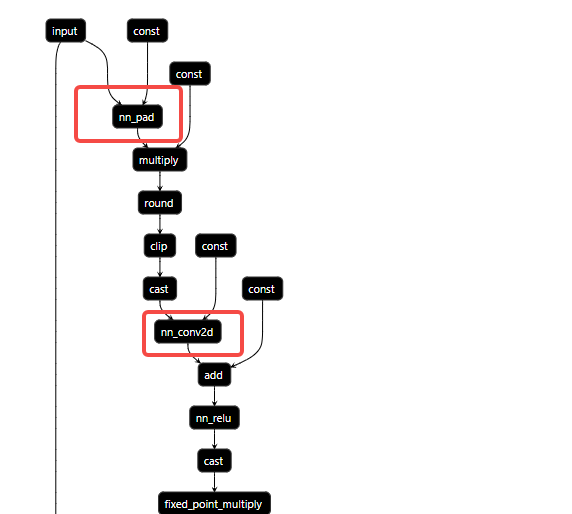
in my graph, the pad can be the conv2d attrs.
%177 = fn (%p045: Tensor[(32, 224, 224, 3), float32], Primitive=1, hash="661737db15eb7f47") -> Tensor[(32, 230, 230, 4), int8] {
%172 = nn.pad(%p045, 0 /* ty=int32 */, pad_width=[[0, 0], [3, 3], [3, 3], [0, 0]]) /* ty=Tensor[(32, 230, 230, 3), float32] */;
%173 = multiply(%172, 128f /* ty=float32 */) /* ty=Tensor[(32, 230, 230, 3), float32] */;
%174 = round(%173) /* ty=Tensor[(32, 230, 230, 3), float32] */;
%175 = clip(%174, a_min=-127f, a_max=127f) /* ty=Tensor[(32, 230, 230, 3), float32] */;
%176 = cast(%175, dtype="int8") /* ty=Tensor[(32, 230, 230, 3), int8] */;
nn.pad(%176, 0 /* ty=int32 */, pad_width=[[0, 0], [0, 0], [0, 0], [0, 1]]) /* ty=Tensor[(32, 230, 230, 4), int8] */
};
%178 = %177(%data) /* ty=Tensor[(32, 230, 230, 4), int8] */;
%179 = fn (%p044: Tensor[(32, 230, 230, 4), int8], %p122: Tensor[(7, 7, 4, 64), int8], %p24: Tensor[(64), int32], hash="4eda88146e49bcc8", data_layout="NHWC", kernel_layout="HWIO", Primitive=1, out_layout="") -> Tensor[(32, 112, 112, 64), int8] {
%165 = nn.conv2d(%p044, %p122, strides=[2, 2], padding=[0, 0, 0, 0], channels=64, kernel_size=[7, 7], data_layout="NHWC", kernel_layout="HWIO", out_dtype="int32") /* ty=Tensor[(32, 112, 112, 64), int32] */;
%166 = add(%165, %p24) /* ty=Tensor[(32, 112, 112, 64), int32] */;
%167 = nn.relu(%166) /* ty=Tensor[(32, 112, 112, 64), int32] */;
%168 = cast(%167, dtype="int64") /* ty=Tensor[(32, 112, 112, 64), int64] */;
%169 = fixed_point_multiply(%168, multiplier=1164561664, shift=-14) /* ty=Tensor[(32, 112, 112, 64), int64] */;
%170 = clip(%169, a_min=-127f, a_max=127f) /* ty=Tensor[(32, 112, 112, 64), int64] */;
%171 = cast(%170, dtype="int32") /* ty=Tensor[(32, 112, 112, 64), int32] */;
cast(%171, dtype="int8") /* ty=Tensor[(32, 112, 112, 64), int8] */
};