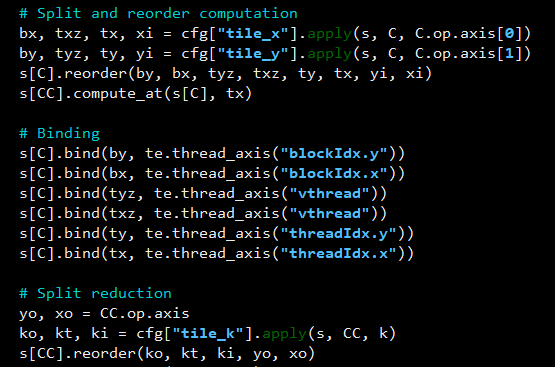
Hi, I am trying to figure out the reason that Ansor performs better than Autotvm on GEMM cases. After comparing Ansor’s generated schedule and the ‘dense_large_batch’ template in topi for CUDA code generation, I find the main difference is the tiling strategy on the output stage. Ansor tries to apply a more complicated tiling pattern and also tile the output’s cache stage (‘out.local’) in the same way. I wonder why Ansor performs the same pattern of tiling on the cache stage (seems generated by the ‘FollowTiling’ function)? I have never found this pattern of scheduling in TVM’s templates. Thanks a lot for any explanation! ![]()
tiling generated by Ansor
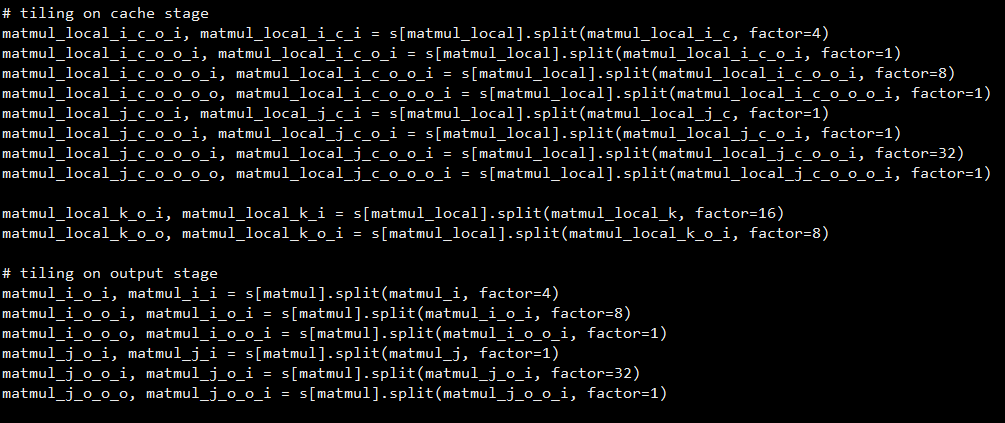
tiling in TVM’s dense_large_batch: