Hi, it seems that Ansor only uses ‘shared’ when applying cache_read. Take matrix multiplication for example, the resulting schedules generated by Ansor never use ‘local’ for cache_read. But AutoTvm’s default schedule templates adopt both ‘shared’ and ‘local’ for cache reading. I wonder why they use different strategies if one of the strategies is better.
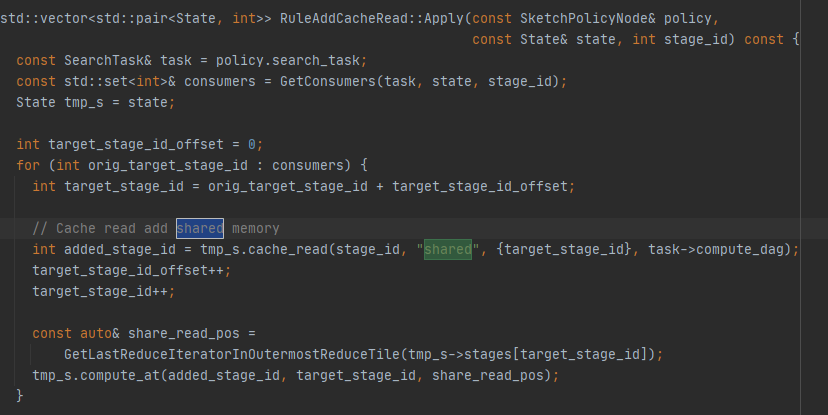
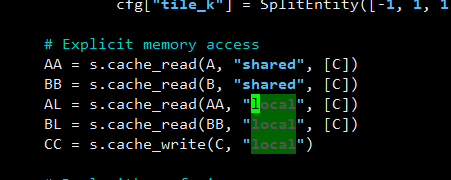
Actually Ansor has “local” memory in some special case.
The two level cache read structure has been tried at the beginning when we built the Ansor system. And It’s still easy for Ansor to add such sketches in the current main branch.
Ansor is a tuning based schedule search system, which means the more options, the larger the search space, and result on more time to get a good scheduler. Ansor needs to try different compute_at locations for the new added cache read stage. So this is more like a trade off. If we have an approach to find the best schedule in an infinite search space with little time, I’m glad to add anything I konw to the sketch policy.
The “shared” memory scope is important for a CUDA schedule, which means to put the data to the shared memory. While the “local” memory scopy is not so necessary, without it, the lower level compiler will still try to put data in the register for better performance.
We would use “local” scope in some schedule like TensorCore, it requires a explicit specification to the wmma buffer.
2 Likes
Thanks a lot for your explanation! 