exception description:
At present, there are two implementations of Canonicalization of quantized unary operations, namely: (default)DQ->func->Q: https://github.com/apache/tvm/blob/main/src/relay/qnn/op/op_common.h#L442 based on table lookup:https://github.com/apache/tvm/blob/main/python/tvm/relay/qnn/op/legalizations.py#L80
When I use Canonicalization of (default)DQ->func->Q method, after OptimizeImpl, Relay IR has done many useless copies in the middle.
Exception recurrence step
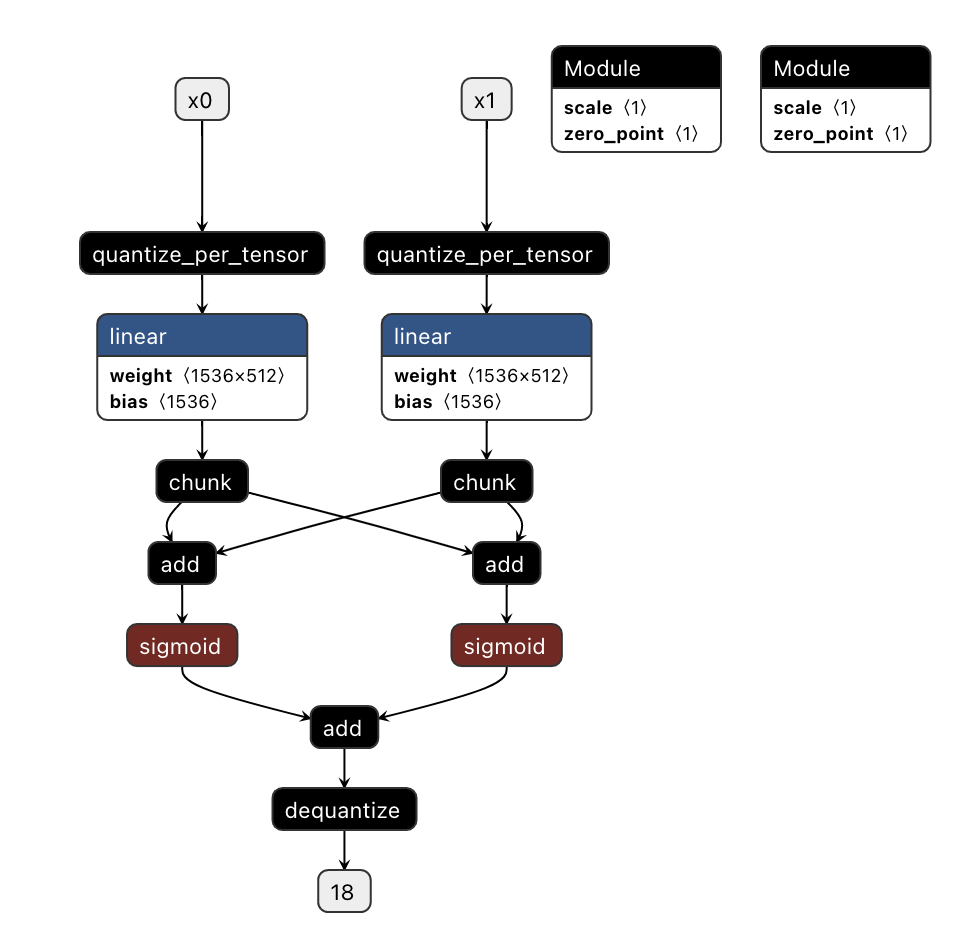
step1 create model:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.quant1 = QuantStub()
self.quant2 = QuantStub()
self.dequant = DeQuantStub()
self.op = torch.nn.quantized.FloatFunctional()
self.linear1 = nn.Linear(512, 3 * 512, bias=True)
self.linear2 = nn.Linear(512, 3 * 512, bias=True)
def forward(self, x0, x1):
x0 = self.quant1(x0)
x1 = self.quant2(x1)
y0 = self.linear1(x0)
y1 = self.linear2(x1)
y0_0, y0_1 = y0.chunk(2, 1)
y1_0, y1_1 = y1.chunk(2, 1)
s_out0 = torch.sigmoid(self.op.add(y0_0, y1_1))
s_out1 = torch.sigmoid(self.op.add(y1_0, y0_1))
out = self.op.add(s_out0, s_out1)
out = self.dequant(out)
return out
from torch.quantization import prepare_qat, get_default_qat_qconfig, convert
import numpy as np
fp32_input0 = np.random.randn(1, 512).astype(np.float32)
fp32_input0 = torch.from_numpy(fp32_input0)
fp32_input1 = np.random.randn(1, 512).astype(np.float32)
fp32_input1 = torch.from_numpy(fp32_input1)
model = Net()
BACKEND = "qnnpack"
model.qconfig = get_default_qat_qconfig(BACKEND)
prepare_qat(model, inplace=True)
model.eval()
y = model(fp32_input0, fp32_input1)
model_int8 = convert(model, inplace=True)
torch.jit.save(torch.jit.trace(model_int8, (fp32_input0, fp32_input1), strict=False), "q_sigmoid.pt")
Model structure:
step2 some necessary patches:
The main purpose of the following patch is to:
- When the input of sigmoid is quantized tensor, use qnn.sigmoid to express, and fix out_scale and out_zero_point of qnn.sigmoid, out_scale and out_zero_point should be fixed values, which are 1.0/256 and 0 respectively.
- Disable based on table lookup Canonicalization of implementation, use Canonicalization of (default)DQ->func->Q method.
- Print Relay IR after OptimizeImpl
This patch is necessary condition for the recurrence of this problem.
diff --git a/python/tvm/relay/frontend/pytorch.py b/python/tvm/relay/frontend/pytorch.py
index d7e1a5dd1..f0f444ee0 100644
--- a/python/tvm/relay/frontend/pytorch.py
+++ b/python/tvm/relay/frontend/pytorch.py
@@ -1560,16 +1560,17 @@ class PyTorchOpConverter:
def sigmoid(self, inputs, input_types):
data = inputs[0]
- def func(x):
- return _op.tensor.sigmoid(x)
-
if self.is_quantized_tensor(data):
- assert len(inputs) == 3, "Input quant param not found in op inputs"
- input_scale = _expr.const(inputs[1])
- input_zero_point = _expr.const(inputs[2])
- return qnn_torch.apply_with_fp32_fallback(data, input_scale, input_zero_point, func)
+ assert len(inputs) == 5, "Input quant param not found in op inputs"
- return func(data)
+ out_scale = _expr.const(inputs[1])
+ out_zp = _expr.const(inputs[2])
+ in_scale = _expr.const(inputs[3])
+ in_zp = _expr.const(inputs[4])
+
+ return qnn_torch.quantized_sigmoid(data, in_scale, in_zp, out_scale, out_zp)
+
+ return _op.tensor.sigmoid(data)
def softplus(self, inputs, input_types):
dtype = input_types[0]
diff --git a/python/tvm/relay/frontend/qnn_torch.py b/python/tvm/relay/frontend/qnn_torch.py
index 0485a993a..1bb7bf738 100644
--- a/python/tvm/relay/frontend/qnn_torch.py
+++ b/python/tvm/relay/frontend/qnn_torch.py
@@ -272,6 +272,7 @@ def _get_quant_param_for_input(input_value):
"quantized::hardswish": (1, 2),
"quantized::conv_transpose2d": qconv_indices,
"quantized::leaky_relu": (3, 4),
+ "aten::sigmoid": (1, 2),
}
def dfs(current_node):
@@ -321,6 +322,44 @@ def _get_add_scalar_output_quant_param(input_scale, input_zero_point, scalar):
return s_prime, z_prime
+def _add_output_quant_params(node, graph, out_scale, out_zero_point):
+ """
+ The output scale and zp of {sigmoid, relu6, tanh} are fixed value.
+ They are required for _get_quant_param_for_input above to work correctly
+ So calculate these params using the same way torch does, and make new
+ constant nodes in the input IR. Also add these params to the inputs of
+ scalar op.
+
+ For example,
+ %input : QUInt8(1, 10) = aten::sigmoid(%x)
+ becomes
+ %1 : float = prim::Constant[value=0.00390625]()
+ %2 : int = prim::Constant[value=0]()
+ %input : QUInt8(1, 10) = aten::sigmoid(%x, %1, %2)
+
+ %1 and %2 are newly created output scale and zp constant nodes
+ """
+ # pylint: disable=c-extension-no-member
+ import torch
+
+ operator = node.kind()
+
+ if operator != "aten::sigmoid":
+ raise NotImplementedError("unsupported op: %s" % operator)
+
+ # create new constant nodes and add them to graph
+ out_scale_node = graph.create("prim::Constant")
+ out_zero_point_node = graph.create("prim::Constant")
+ out_scale_node.insertBefore(node)
+ out_zero_point_node.insertBefore(node)
+ out_scale_node.f_("value", out_scale)
+ out_zero_point_node.i_("value", out_zero_point)
+ out_scale_node.output().setType(torch._C.FloatType.get())
+ out_zero_point_node.output().setType(torch._C.IntType.get())
+ node.addInput(out_scale_node.output())
+ node.addInput(out_zero_point_node.output())
+
+
def _get_mul_scalar_output_quant_param(input_scale, input_zero_point, scalar):
"""
Determine the output scale and zp of quantized::mul_scalar op
@@ -483,6 +522,12 @@ def add_input_quant_params_to_op_inputs(graph):
# see the comments in this function above
_add_output_quant_params_to_scalar_op(node, graph, inp_scale, inp_zero_point, scalar)
+ if operator == "aten::sigmoid":
+ # sigmoid has fixed output scale and zero_point
+ scale = 1.0 / 256
+ zp = 0
+ _add_output_quant_params(node, graph, scale, zp)
+
for scale, zp in zip(input_scales, input_zero_points):
node.addInput(scale)
node.addInput(zp)
@@ -564,6 +609,9 @@ def apply_with_fp32_fallback(data, input_scale, input_zero_point, func_fp32):
out = func_fp32(dequantized)
return relay.qnn.op.quantize(out, input_scale, input_zero_point, out_dtype="uint8", axis=1)
+def quantized_sigmoid(data, in_scale, in_zp, out_scale, out_zp):
+ return relay.qnn.op.sigmoid(data, in_scale, in_zp, out_scale, out_zp)
+
def quantized_relu(data, input_zero_point):
# refer to aten/src/ATen/native/quantized/cpu/qrelu.cpp
diff --git a/python/tvm/relay/qnn/op/legalizations.py b/python/tvm/relay/qnn/op/legalizations.py
index 266e43072..d3e21644b 100644
--- a/python/tvm/relay/qnn/op/legalizations.py
+++ b/python/tvm/relay/qnn/op/legalizations.py
@@ -73,14 +73,14 @@ def hardswish_func(x):
return x * x2 / 6.0
-register_qnn_unary_op_legalize("qnn.sqrt", np.sqrt)
-register_qnn_unary_op_legalize("qnn.rsqrt", lambda arr: 1 / np.sqrt(arr))
-register_qnn_unary_op_legalize("qnn.exp", np.exp)
-register_qnn_unary_op_legalize("qnn.erf", special.erf)
-register_qnn_unary_op_legalize("qnn.sigmoid", lambda arr: 1 / (1 + np.exp(-arr)))
-register_qnn_unary_op_legalize("qnn.hardswish", hardswish_func)
-register_qnn_unary_op_legalize("qnn.tanh", np.tanh)
-register_qnn_unary_op_legalize("qnn.log", np.log)
+#register_qnn_unary_op_legalize("qnn.sqrt", np.sqrt)
+#register_qnn_unary_op_legalize("qnn.rsqrt", lambda arr: 1 / np.sqrt(arr))
+#register_qnn_unary_op_legalize("qnn.exp", np.exp)
+#register_qnn_unary_op_legalize("qnn.erf", special.erf)
+#register_qnn_unary_op_legalize("qnn.sigmoid", lambda arr: 1 / (1 + np.exp(-arr)))
+#register_qnn_unary_op_legalize("qnn.hardswish", hardswish_func)
+#register_qnn_unary_op_legalize("qnn.tanh", np.tanh)
+#register_qnn_unary_op_legalize("qnn.log", np.log)
# Default to None. If overridden by target, this will not be run.
diff --git a/src/relay/backend/build_module.cc b/src/relay/backend/build_module.cc
index 39f2e7761..e52f0132b 100644
--- a/src/relay/backend/build_module.cc
+++ b/src/relay/backend/build_module.cc
@@ -413,7 +413,7 @@ class RelayBuildModule : public runtime::ModuleNode {
IRModule module = WithAttrs(
relay_module, {{tvm::attr::kExecutor, executor_}, {tvm::attr::kRuntime, runtime_}});
relay_module = OptimizeImpl(std::move(module));
-
+ std::cout << PrettyPrint(relay_module) << std::endl;
// Get the updated function and new IRModule to build.
// Instead of recreating the IRModule, we should look at the differences between this and the
// incoming IRModule to see if we can just pass (IRModule, Function) to the code generator.
step3 build model
import torch
import numpy as np
from tvm import relay
import tvm
img_input1 = np.random.randn(1, 512).astype(np.float32)
pt_input1 = torch.from_numpy(img_input1)
img_input2 = np.random.randn(1, 512).astype(np.float32)
pt_input2 = torch.from_numpy(img_input2)
model = torch.jit.load("q_sigmoid.pt")
script_module = torch.jit.trace(model, (pt_input1, pt_input2)).eval()
input_infos = [("x0", ((1, 512), 'float32')), ("x1", ((1, 512), 'float32'))]
mod, params = relay.frontend.from_pytorch(script_module, input_infos, default_dtype='float32', keep_quantized_weight=True)
target = "llvm"
with tvm.transform.PassContext(opt_level=3):
lib = relay.build(mod, target=target, params=params)
after OptimizeImpl, Relay IR:
def @main(%x0 {virtual_device=VirtualDevice(device_type=1, virtual_device_id=0, target=Target(kind='llvm', keys={'cpu'}, attrs={'link-params': (bool)0}, host=Target(kind='llvm', keys={'cpu'}, attrs={'link-params': (bool)0})))}: Tensor[(1, 512), float32] /* ty=Tensor[(1, 512), float32] */, %x1 {virtual_device=VirtualDevice(device_type=1, virtual_device_id=0, target=Target(kind='llvm', keys={'cpu'}, attrs={'link-params': (bool)0}, host=Target(kind='llvm', keys={'cpu'}, attrs={'link-params': (bool)0})))}: Tensor[(1, 512), float32] /* ty=Tensor[(1, 512), float32] */, executor=meta[Executor][0], runtime=meta[Runtime][0], hash="ae06004cb5f54d90", weight_layout="NC8n", virtual_device=VirtualDevice(device_type=1, virtual_device_id=0, target=Target(kind='llvm', keys={'cpu'}, attrs={'link-params': (bool)0}, host=Target(kind='llvm', keys={'cpu'}, attrs={'link-params': (bool)0})))) -> Tensor[(1, 768), float32] {
%68 = fn (%p01: Tensor[(1, 512), float32] /* ty=Tensor[(1, 512), float32] */, %p11: int16 /* ty=int16 */, Primitive=1, hash="7078c44c5f2bac5d") -> Tensor[(1, 512), int16] {
%62 = divide(%p01, 0.0212024f /* ty=float32 */) /* ty=Tensor[(1, 512), float32] */;
%63 = round(%62) /* ty=Tensor[(1, 512), float32] */;
%64 = add(%63, 133f /* ty=float32 */) /* ty=Tensor[(1, 512), float32] */;
%65 = clip(%64, a_min=0f, a_max=255f) /* ty=Tensor[(1, 512), float32] */;
%66 = cast(%65, dtype="uint8") /* ty=Tensor[(1, 512), uint8] */;
%67 = cast(%66, dtype="int16") /* ty=Tensor[(1, 512), int16] */;
subtract(%67, %p11) /* ty=Tensor[(1, 512), int16] */
} /* ty=fn (Tensor[(1, 512), float32], int16) -> Tensor[(1, 512), int16] */;
%81 = fn (%p04: Tensor[(1, 512), float32] /* ty=Tensor[(1, 512), float32] */, %p13: int16 /* ty=int16 */, Primitive=1, hash="70dbbfd714e3db59") -> Tensor[(1, 512), int16] {
%75 = divide(%p04, 0.0256501f /* ty=float32 */) /* ty=Tensor[(1, 512), float32] */;
%76 = round(%75) /* ty=Tensor[(1, 512), float32] */;
%77 = add(%76, 120f /* ty=float32 */) /* ty=Tensor[(1, 512), float32] */;
%78 = clip(%77, a_min=0f, a_max=255f) /* ty=Tensor[(1, 512), float32] */;
%79 = cast(%78, dtype="uint8") /* ty=Tensor[(1, 512), uint8] */;
%80 = cast(%79, dtype="int16") /* ty=Tensor[(1, 512), int16] */;
subtract(%80, %p13) /* ty=Tensor[(1, 512), int16] */
} /* ty=fn (Tensor[(1, 512), float32], int16) -> Tensor[(1, 512), int16] */;
%82 = %81(%x1, 120i16 /* ty=int16 */) /* ty=Tensor[(1, 512), int16] */;
%83 = fn (%p03: Tensor[(1, 512), int16] /* ty=Tensor[(1, 512), int16] */, %p12: Tensor[(192, 512, 8), int16] /* ty=Tensor[(192, 512, 8), int16] */, %p21: Tensor[(1, 1536), int32] /* ty=Tensor[(1, 1536), int32] */, %p31: int32 /* ty=int32 */, Primitive=1, hash="da809a10a146d5b4", weight_layout="NC8n") -> Tensor[(1, 1536), uint8] {
%70 = nn.contrib_dense_pack(%p03, %p12, units=None, out_dtype="int32", weight_layout="NC8n") /* ty=Tensor[(1, 1536), int32] */;
%71 = add(%70, %p21) /* ty=Tensor[(1, 1536), int32] */;
%72 = fixed_point_multiply(%71, multiplier=1351627502, shift=-10) /* ty=Tensor[(1, 1536), int32] */;
%73 = add(%p31, %72) /* ty=Tensor[(1, 1536), int32] */;
%74 = clip(%73, a_min=0f, a_max=255f) /* ty=Tensor[(1, 1536), int32] */;
cast(%74, dtype="uint8") /* ty=Tensor[(1, 1536), uint8] */
} /* ty=fn (Tensor[(1, 512), int16], Tensor[(192, 512, 8), int16], Tensor[(1, 1536), int32], int32) -> Tensor[(1, 1536), uint8] */;
%84 = %83(%82, meta[relay.Constant][3] /* ty=Tensor[(192, 512, 8), int16] */, meta[relay.Constant][4] /* ty=Tensor[(1, 1536), int32] */, 131 /* ty=int32 */) /* ty=Tensor[(1, 1536), uint8] */;
%85 = fn (%p02: Tensor[(1, 1536), uint8] /* ty=Tensor[(1, 1536), uint8] */, Primitive=1, hash="d91b4d6cad56132a") -> Tensor[(1, 768), uint8] {
%69 = split(%p02, indices_or_sections=[768], axis=1) /* ty=(Tensor[(1, 768), uint8], Tensor[(1, 768), uint8]) */;
%69.1 /* ty=Tensor[(1, 768), uint8] */
} /* ty=fn (Tensor[(1, 1536), uint8]) -> Tensor[(1, 768), uint8] */;
%92 = fn (%p06: Tensor[(1, 512), int16] /* ty=Tensor[(1, 512), int16] */, %p14: Tensor[(192, 512, 8), int16] /* ty=Tensor[(192, 512, 8), int16] */, %p22: Tensor[(1, 1536), int32] /* ty=Tensor[(1, 1536), int32] */, %p32: int32 /* ty=int32 */, Primitive=1, hash="da809a10a146d5b4", weight_layout="NC8n") -> Tensor[(1, 1536), uint8] {
%87 = nn.contrib_dense_pack(%p06, %p14, units=None, out_dtype="int32", weight_layout="NC8n") /* ty=Tensor[(1, 1536), int32] */;
%88 = add(%87, %p22) /* ty=Tensor[(1, 1536), int32] */;
%89 = fixed_point_multiply(%88, multiplier=1351627502, shift=-10) /* ty=Tensor[(1, 1536), int32] */;
%90 = add(%p32, %89) /* ty=Tensor[(1, 1536), int32] */;
%91 = clip(%90, a_min=0f, a_max=255f) /* ty=Tensor[(1, 1536), int32] */;
cast(%91, dtype="uint8") /* ty=Tensor[(1, 1536), uint8] */
} /* ty=fn (Tensor[(1, 512), int16], Tensor[(192, 512, 8), int16], Tensor[(1, 1536), int32], int32) -> Tensor[(1, 1536), uint8] */;
%93 = %92(%82, meta[relay.Constant][6] /* ty=Tensor[(192, 512, 8), int16] */, meta[relay.Constant][7] /* ty=Tensor[(1, 1536), int32] */, 131 /* ty=int32 */) /* ty=Tensor[(1, 1536), uint8] */;
%94 = fn (%p05: Tensor[(1, 1536), uint8] /* ty=Tensor[(1, 1536), uint8] */, Primitive=1, hash="d91b4df917c21c7b") -> Tensor[(1, 768), uint8] {
%86 = split(%p05, indices_or_sections=[768], axis=1) /* ty=(Tensor[(1, 768), uint8], Tensor[(1, 768), uint8]) */;
%86.0 /* ty=Tensor[(1, 768), uint8] */
} /* ty=fn (Tensor[(1, 1536), uint8]) -> Tensor[(1, 768), uint8] */;
%97 = %68(%x0, 133i16 /* ty=int16 */) /* ty=Tensor[(1, 512), int16] */;
%98 = fn (%p07: Tensor[(1, 512), int16] /* ty=Tensor[(1, 512), int16] */, %p15: Tensor[(192, 512, 8), int16] /* ty=Tensor[(192, 512, 8), int16] */, %p23: Tensor[(1, 1536), int32] /* ty=Tensor[(1, 1536), int32] */, Primitive=1, hash="82c52dab0ae3cb2d", weight_layout="NC8n") -> Tensor[(1, 1536), int32] {
%95 = nn.contrib_dense_pack(%p07, %p15, units=None, out_dtype="int32", weight_layout="NC8n") /* ty=Tensor[(1, 1536), int32] */;
%96 = add(%95, %p23) /* ty=Tensor[(1, 1536), int32] */;
fixed_point_multiply(%96, multiplier=1305209844, shift=-10) /* ty=Tensor[(1, 1536), int32] */
} /* ty=fn (Tensor[(1, 512), int16], Tensor[(192, 512, 8), int16], Tensor[(1, 1536), int32]) -> Tensor[(1, 1536), int32] */;
%99 = %85(%84) /* ty=Tensor[(1, 768), uint8] */;
%100 = %94(%93) /* ty=Tensor[(1, 768), uint8] */;
%101 = %98(%97, meta[relay.Constant][8] /* ty=Tensor[(192, 512, 8), int16] */, meta[relay.Constant][9] /* ty=Tensor[(1, 1536), int32] */) /* ty=Tensor[(1, 1536), int32] */;
%102 = fn (%p0: Tensor[(1, 512), int16] /* ty=Tensor[(1, 512), int16] */, %p1: Tensor[(192, 512, 8), int16] /* ty=Tensor[(192, 512, 8), int16] */, %p2: Tensor[(1, 1536), int32] /* ty=Tensor[(1, 1536), int32] */, %p3: Tensor[(1), int32] /* ty=Tensor[(1), int32] */, %p4: Tensor[(1, 768), uint8] /* ty=Tensor[(1, 768), uint8] */, %p5: Tensor[(1), int32] /* ty=Tensor[(1), int32] */, %p6: Tensor[(1, 768), uint8] /* ty=Tensor[(1, 768), uint8] */, %p7: Tensor[(1, 1536), int32] /* ty=Tensor[(1, 1536), int32] */, Primitive=1, hash="5d4a5b69dd0ab195", weight_layout="NC8n") -> Tensor[(1, 768), float32] {
%0 = nn.contrib_dense_pack(%p0, %p1, units=None, out_dtype="int32", weight_layout="NC8n") /* ty=Tensor[(1, 1536), int32] */;
%1 = add(%0, %p2) /* ty=Tensor[(1, 1536), int32] */;
%2 = fixed_point_multiply(%1, multiplier=1305209844, shift=-10) /* ty=Tensor[(1, 1536), int32] */;
%3 = add(134 /* ty=int32 */, %2) /* ty=Tensor[(1, 1536), int32] */;
%4 = clip(%3, a_min=0f, a_max=255f) /* ty=Tensor[(1, 1536), int32] */;
%5 = cast(%4, dtype="uint8") /* ty=Tensor[(1, 1536), uint8] */;
%6 = split(%5, indices_or_sections=[768], axis=1) /* ty=(Tensor[(1, 768), uint8], Tensor[(1, 768), uint8]) */;
%7 = %6.0 /* ty=Tensor[(1, 768), uint8] */;
%8 = cast(%7, dtype="int32") /* ty=Tensor[(1, 768), int32] */;
%9 = subtract(%8, %p3) /* ty=Tensor[(1, 768), int32] */;
%10 = fixed_point_multiply(%9, multiplier=1376585808, shift=0) /* ty=Tensor[(1, 768), int32] */;
%11 = cast(%p4, dtype="int32") /* ty=Tensor[(1, 768), int32] */;
%12 = subtract(%11, %p5) /* ty=Tensor[(1, 768), int32] */;
%13 = fixed_point_multiply(%12, multiplier=1608165527, shift=0) /* ty=Tensor[(1, 768), int32] */;
%14 = add(130 /* ty=int32 */, %10) /* ty=Tensor[(1, 768), int32] */;
%15 = add(130 /* ty=int32 */, %13) /* ty=Tensor[(1, 768), int32] */;
%16 = add(%14, %15) /* ty=Tensor[(1, 768), int32] */;
%17 = subtract(%16, 130 /* ty=int32 */) /* ty=Tensor[(1, 768), int32] */;
%18 = clip(%17, a_min=0f, a_max=255f) /* ty=Tensor[(1, 768), int32] */;
%19 = subtract(%18, 130 /* ty=int32 */) /* ty=Tensor[(1, 768), int32] */;
%20 = cast(%19, dtype="float32") /* ty=Tensor[(1, 768), float32] */;
%21 = multiply(%20, 0.0193159f /* ty=float32 */) /* ty=Tensor[(1, 768), float32] */;
%22 = sigmoid(%21) /* ty=Tensor[(1, 768), float32] */;
%23 = divide(%22, 0.00390625f /* ty=float32 */) /* ty=Tensor[(1, 768), float32] */;
%24 = round(%23) /* ty=Tensor[(1, 768), float32] */;
%25 = clip(%24, a_min=0f, a_max=255f) /* ty=Tensor[(1, 768), float32] */;
%26 = cast(%25, dtype="uint8") /* ty=Tensor[(1, 768), uint8] */;
%27 = cast(%26, dtype="int32") /* ty=Tensor[(1, 768), int32] */;
%28 = fixed_point_multiply(%27, multiplier=1737142308, shift=-2) /* ty=Tensor[(1, 768), int32] */;
%29 = cast(%p6, dtype="int32") /* ty=Tensor[(1, 768), int32] */;
%30 = subtract(%29, %p5) /* ty=Tensor[(1, 768), int32] */;
%31 = fixed_point_multiply(%30, multiplier=1608165527, shift=0) /* ty=Tensor[(1, 768), int32] */;
%32 = add(134 /* ty=int32 */, %p7) /* ty=Tensor[(1, 1536), int32] */;
%33 = clip(%32, a_min=0f, a_max=255f) /* ty=Tensor[(1, 1536), int32] */;
%34 = cast(%33, dtype="uint8") /* ty=Tensor[(1, 1536), uint8] */;
%35 = split(%34, indices_or_sections=[768], axis=1) /* ty=(Tensor[(1, 768), uint8], Tensor[(1, 768), uint8]) */;
%36 = %35.1 /* ty=Tensor[(1, 768), uint8] */;
%37 = cast(%36, dtype="int32") /* ty=Tensor[(1, 768), int32] */;
%38 = subtract(%37, %p3) /* ty=Tensor[(1, 768), int32] */;
%39 = fixed_point_multiply(%38, multiplier=1376585808, shift=0) /* ty=Tensor[(1, 768), int32] */;
%40 = add(130 /* ty=int32 */, %31) /* ty=Tensor[(1, 768), int32] */;
%41 = add(130 /* ty=int32 */, %39) /* ty=Tensor[(1, 768), int32] */;
%42 = add(%40, %41) /* ty=Tensor[(1, 768), int32] */;
%43 = subtract(%42, 130 /* ty=int32 */) /* ty=Tensor[(1, 768), int32] */;
%44 = clip(%43, a_min=0f, a_max=255f) /* ty=Tensor[(1, 768), int32] */;
%45 = subtract(%44, 130 /* ty=int32 */) /* ty=Tensor[(1, 768), int32] */;
%46 = cast(%45, dtype="float32") /* ty=Tensor[(1, 768), float32] */;
%47 = multiply(%46, 0.0193159f /* ty=float32 */) /* ty=Tensor[(1, 768), float32] */;
%48 = sigmoid(%47) /* ty=Tensor[(1, 768), float32] */;
%49 = divide(%48, 0.00390625f /* ty=float32 */) /* ty=Tensor[(1, 768), float32] */;
%50 = round(%49) /* ty=Tensor[(1, 768), float32] */;
%51 = clip(%50, a_min=0f, a_max=255f) /* ty=Tensor[(1, 768), float32] */;
%52 = cast(%51, dtype="uint8") /* ty=Tensor[(1, 768), uint8] */;
%53 = cast(%52, dtype="int32") /* ty=Tensor[(1, 768), int32] */;
%54 = fixed_point_multiply(%53, multiplier=1737142308, shift=-2) /* ty=Tensor[(1, 768), int32] */;
%55 = add(130 /* ty=int32 */, %28) /* ty=Tensor[(1, 768), int32] */;
%56 = add(130 /* ty=int32 */, %54) /* ty=Tensor[(1, 768), int32] */;
%57 = add(%55, %56) /* ty=Tensor[(1, 768), int32] */;
%58 = subtract(%57, 130 /* ty=int32 */) /* ty=Tensor[(1, 768), int32] */;
%59 = clip(%58, a_min=0f, a_max=255f) /* ty=Tensor[(1, 768), int32] */;
%60 = subtract(%59, 130 /* ty=int32 */) /* ty=Tensor[(1, 768), int32] */;
%61 = cast(%60, dtype="float32") /* ty=Tensor[(1, 768), float32] */;
multiply(%61, 0.0193159f /* ty=float32 */) /* ty=Tensor[(1, 768), float32] */
} /* ty=fn (Tensor[(1, 512), int16], Tensor[(192, 512, 8), int16], Tensor[(1, 1536), int32], Tensor[(1), int32], Tensor[(1, 768), uint8], Tensor[(1), int32], Tensor[(1, 768), uint8], Tensor[(1, 1536), int32]) -> Tensor[(1, 768), float32] */;
%102(%97, meta[relay.Constant][0] /* ty=Tensor[(192, 512, 8), int16] */, meta[relay.Constant][1] /* ty=Tensor[(1, 1536), int32] */, meta[relay.Constant][2] /* ty=Tensor[(1), int32] */, %99, meta[relay.Constant][5] /* ty=Tensor[(1), int32] */, %100, %101) /* ty=Tensor[(1, 768), float32] */
}
%83 and %92 operations are the same, repeated %98 and part of %102 operations are the same, repeated