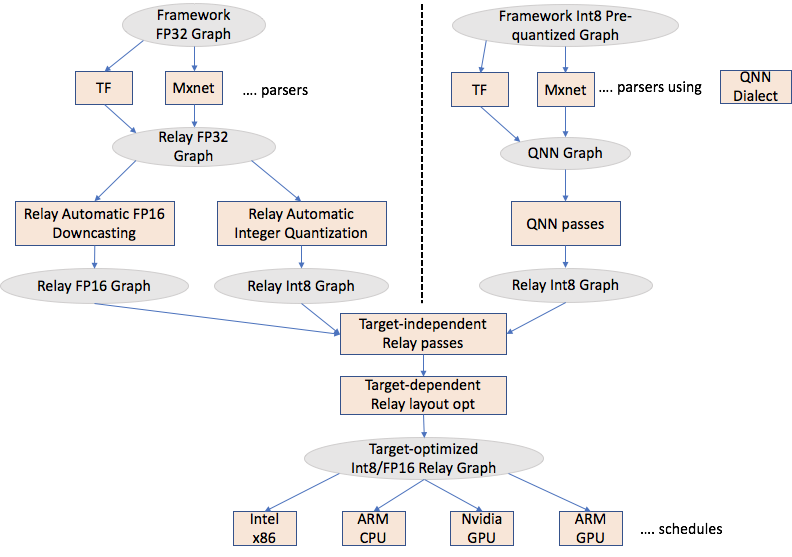
I think it is worthwhile to have a high-level quantization post explaining the flow and mentioning developers who are involved in different steps. This should improve collaboration, while also putting a high-level story to anybody who wants to explore TVM for quantization.
As shown in the above figure, there are two different parallel efforts ongoing
Automatic Integer Quantization (@ziheng, @vinx13) - It takes a FP32 framework graph and automatically converts it to Int8 within Relay.
Accepting Pre-quantized Integer models (@janimesh, @shoubhik) - This approach accepts a pre-quantized model, introduces a Relay dialect called QNN and generates an Int8 Relay graph.
There are few discussions around Relay Automatic FP16 Downcasting. There has not been any RFC yet. @xyzhou and @janimesh are exploring/prototyping this and plan to put up a RFC in next couple of weeks.
Relay Optimizations
Target-independent Relay passes - TVM community is continuously adding these passes. Examples are fuse constant, common subexpression elimination etc.
Target-dependent Relay passes - These passes transform the Relay graph to optimize it for the target. An example is Legalize or AlterOpLayout transform, where depending on the target, we change the layouts of convolution/dense layer. TVM community is working on improving on both infrastructure to enable such transformation, and adding target-specific layout transformations. Some of this infrastructure work is pre-requisite for a good overall design ([RFC] AlterOpLayout Pass Refactoring · Issue #3670 · apache/tvm · GitHub).
Relay to Hardware
Once we have an optimized Relay graph, we need to write optimized schedules. Like FP32, we have to focus our efforts only on expensive ops like conv2d, dense etc. There are scattered efforts and TVM community is working on unifying them. Some of the developers that have worked on different backends (not necessarily Int8)
Intel x86 - Near future Int8 exploration is restricted to Skylake and Cascade lake (@janimesh, @yzhliu, @kevinthesun)
ARM - Some NHWC work going on currently for FP32. The plan is to extend this work to Int8 after FP32 work is finished (@jackwish, @FrozenGene, @thierry)
Great to see this post @janimesh, great visual! I think that layout optimization is highly tied to getting good target-specific performance results, and it wouldn’t hurt to include in the picture where these layout optimizations come into place. Especially since different frameworks will dictate certain layours (NCHW vs. NHWC), and backends will impose layouts (NCHWc, NCHWnc).
One more thing - for x86 target we are currently only supporting int8 operator on 1x1 convolutions. Is there a reason why we don’t support it on non point-wise convolutions?
Somehow missed this. We do support int8 operator on non-point wise computations as well. The int8 support only works for Skylake. Older Intel generations don’t have any instructions to speedup int8 as far as I know.
We can now ingest all the Pre-quantized TFLite hosted models via TVM. If we see the figure in the first post, it takes the QNN approach of supporting TFLite models and optimizes inference on Intel devices (specifically cascade lake).
Accuracy
Following is the end-to-end accuracy comparison of TFLite pre-quantized graphs executed via TVM compared to TFLite online reported accuracy.
Quantized models
TFLite graph via TVM
Reported TFLite accuracy
Inception V1
69.6%/89.5%
70.1%/89.8%
Inception V2
73.3%/91.3%
73.5%/91.4%
Inception V3
77.3%/93.6%
77.5%/93.7%
Inception V4
79.6%/94.2%
79.5%/93.90%
Mobilenet V1
70.1%/89.0%
70.0%/89.0%
Mobilenet V2
70.9%/90.1%
70.8%/89.9%
Performance
The performance is evaluated on C5.12xlarge Cascade lake machine, supported Intel VNNI instructions. All the graphs here are executed via TVM.
Wherever applicable, I compared the quantized model performance with its FP32 TFLite hosted counterpart. Latency is in ms.
Float32
Quantized
Speedup
Inception V1
NA
2.143
NA
Inception V2
NA
8.919
NA
Inception V3
10.373
6.115
1.7
Inception V4
21.233
12.315
1.72
Mobilenet V1
5.578
7.328
0.76
Mobilenet V2
6.424
8.798
0.73
Key points to notice
TFlite quantized models are asymmetric. AFAIK, this is the first effort to execute asymmetric models on Intel machines using VNNI instructions.
MobileNet models have slowdown because they use Depthwise convolution that has not been configured to use VNNI instructions.
One might be interested in knowing what would the performance look like if the network was symmetric. So, for this experiment, I forced all the quantized params in the network to make it look like symmetric. Note, this is just an experiment, as the model accuracy suffers badly.
I did not include mobilenet, as it does utilize VNNI for now.
Very nice analysis and also nice to see that TVM matches the end-to-end accuracy reported online by TFLite . This results might be also interesting to @FrozenGene as we were discussing about the TFLite accuracy yesterday.
Just a question: For the performance evaluation did you autotuned the models?
Execuse me, can TVM support non-framework pre-quantized models which we trained and quantized by ourselves, no relationship with frameworks’ quantization toolchain?