Dear community,
lately i’ve played around with QAT on the PyTorch level. My model was a custom CNN/MLP model for image classification, containing only the following layers:
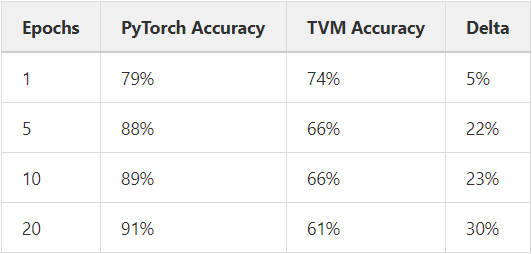
In the first column you see the amount of epochs that i trained the model. The next two columns represent the measured accuracy of the QAT-trained model on the PyTorch and TVM level.
The last column represents the %-delta between the two accuracy values.
Apparently the accuracy on the TVM level decreases the longer i train my model (while accuracy on the PyTorch level obviously increases).
Another interesting thing i observed was the accuracy differences when freezing quantization parameters earlier in the training process: the earlier i freeze the quantization parameters, the higher the accuracy is in TVM (freezing after 1 epoch: 77% accuracy, freezing after 8 epochs (from 20): 60%).
Im sorry if i missed any necessary information, its my first blog post on this forum! I will happily add any requested information or even scripts to reproduce.
Do you have any idea how…
The drop-off from around 90% (in PyTorch) to 60% (in TVM) can be explained?
The decreasing TVM accuracy together with the later freezing of the quantization parameters can be explained?
When you convert quantized pytorch models to TVM, you should do quantization in exactly the same way as the PyTorch tutorial shows. If you are comparing the accuracy of models quantized with PyTorch-tutorial way vs TVM-tutorial way, you are not comparing the same models. The dummy quantization procedure in the TVM tutorial is not relevant for you.
If you are correctly doing what I said above, then I don’t know why accuracy would drop after conversion to TVM. It’s better to make sure post-training quantization works before QAT.
Thank you masahi for your reply.
In the TVM tutorial they just use dummy PTQ on a pretrained mobilenet, i didnt use that. I literally just imported the QAT trained model as a traced Torchscript in TVM and tried to convert it to Relay.
In my case i used QAT the way PyTorch describes it in their Quant tutorial.
I will do PTQ tests today and give you feedback on my results
So the results are similiar (while not being as bad as with QAT).
If you have no immediate suggestion i could put together the scripts to enable you to reproduce.
Possibly i did an error thats independent of TVM…
I see, you are serializing and loading quantized model. As I reported in https://github.com/pytorch/pytorch/issues/39690, there is an typing problem when Torchscript module is serialized and loaded back.
So it seems that the deserialization in TVM causes problems, right?
Sadly this workflow is probably not applicable for my usecase, because of the serialization restriction.
No this is not a TVM’s problem. As soon as you torch.jit.save, typing information is lost. All we can do is either wait for PyTorch people to fix this problem, or do workaround ourselves.
Below is the workaround that I thought would fixed this problem for us. Can you check if your TVM install has this commit?
Your fix works for me. Didn’t had this fix earlier, just pulled and rebuilt TVM. Now i get the desired accuracy from serialized models. Thanks for your help.