Hello all!
During the past months I have been working on integrating the Gemmini accelerator into the TVM framework. The main goal of the work was to use microTVM to generate C code together with the specific instructions and function calls for the Gemmini accelerator. I open this thread in order to explain to the community what the integration brings and how it works. This is the code that was used to generate the results of the paper “Integration of a systolic array based hardware accelerator into a DNN operator auto-tuning framework” (url). My plan is to upload it to GitHub and generate a pull request in the very near future, so I will update this post when this is ready.
Introduction
The Gemmini project is a tightly coupled tensor operation accelerator and part of the Chipyard ecosystem. It communicates with the Rocket core using RoCC commands, which can be generated using custom RISC-V instructions.
The main computation unit is a square systolic array of dimensions DIM x DIM built from individual tiles, each tile conformed of one or more processing elements (multiply and accumulate units). It also consists of 2 internal SRAMs, the scratchpad and the accumulator, and a DMA engine to transfer data between these memories and the external DRAM.
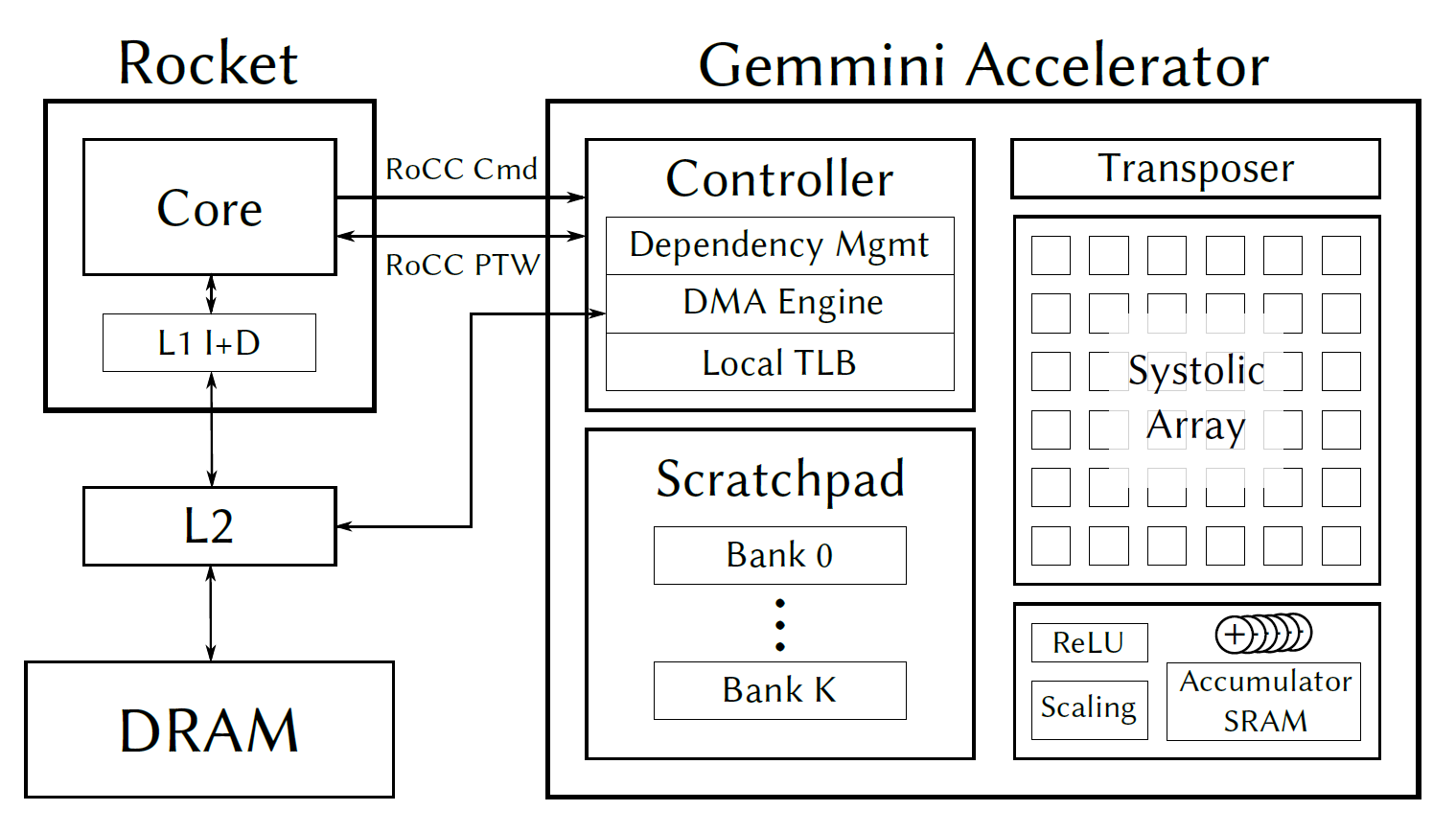
The project is highly configurable, in order to tackle a variety of platforms and use cases. As such, the software that generates the code for this accelerator must also be able to generate C code based on the parameters of the implemented hardware. This is why I think that the TVM project, using its BYOC workflow, is the ideal framework to generate the necessary code.
About Gemmini’s RoCC instructions
Gemmini presents a series of instructions to the CPU in order to give the programmer the possibility of implementing the DNN operators in a variety of different forms. 2 different kind of instructions can be used:
- Intrinsic instructions: These are the basic, more simple instructions provided by Gemmini. They provide fine-grained control of the accelerator, and consist of:
- Configuration and maintenance instructions: they are used to flush Gemminis internal TLB and configure the move pipeline and the execution pipeline of the accelerator.
- Move instructions: these instructions move patches of specific numbers of rows and columns between the external DRAM and the internal SRAM.
- Execute instructions: these instructions execute the actual matrix multiplication using data available in the scratchpad and/or the accumulator.
- Loop instructions: this are complex instructions that execute a complete operation using hardcoded finite state machines. Two different types of loop instructions exist:
- Matrix multiplication: performs a tiled matrix multiplication. Allows for bigger matrixes than the DIM x DIM systolic array. All matrix sizes are configurable during runtime.
- Convolution: performs a tiled 2D convolution. All matrix sizes are configurable during runtime.
Integration details
Once a prequantized model is imported into TVM using the standard TensorFlow Lite frontend, a relay preprocess pass must be executed to modify the IRModule, by grouping supported operations into a custom Gemmini operator. This pass uses the standard pattern-matching language of TVM in order to group different relay operators and replace them with the appropriate Gemmini operator.
Supported operators
Some operators have 2 implementation strategies available, in order to generate code using only the intrinsic instructions or the functions provided by the Gemmini developers (which internally use the “CISC type” loop instructions). Having these 2 strategies available is useful because one can use AutoTVM to generate code using the intrinsic instructions and compare its throughput against the functions provided by the Gemmini developers.
Support for the following operators will be provided:
- 2D convolution (pattern matching around qnn.conv2d)
- Depthwise 2D convolution (pattern matching around qnn.conv2d)
- Fully connected layer (pattern matching around qnn.dense)
- Max pooling layer (pattern matching around nn.max_pool2d)
- Adding layer (pattern matching around qnn.add)
The pattern matching also supports merging operators into other operators. For example, Gemmini provides the support to accelerate a convolution followed by a max pooling operator directly in hardware. This is supported by the integration, replacing the sequence of qnn.conv2d + nn.max_pool2d with only one operator, which will offload the convolution and the max pooling to the hardware.
A note about quantization
Defining our custom operators for the 5 previously mentioned operators allows us to implement some algebraic transformations in order to merge the quantization parameters into the bias of each of these layers. This is similar to how the qnn.conv2d manages the output requantization, but this goes one step further. This is because Gemmini only allows scaling the output when reading data from the SRAM into the DRAM, but does not provide a way to offset this data. So, the output offset of the requantization operator that is merged into the custom operator is also integrated into the bias of the layer.
Provided examples
This integration also provides for each of the supported layers a tutorial that can be used as an example of how to use this integration. This integration also provides a tutorial compiling an entire MobileNet for the Gemmini accelerator. The tests are executed on the Spike RISC-V ISA Simulator, which already has a functional simulator of the Gemmini accelerator.
Open questions and pending work
- Is it possible to run the Spike simulator on the CI? We should run actually a particular patched version of the Spike simulator, which provides the extension for the functional simulator for Gemmini.
- Where would be the correct place to copy the tutorial files? There is no “contrib” folder for tutorials, right? I have place them under tvm/contrib/gemmini, together with most of the rest of the code, but if there is another place to put them, please let me know!
Edit: pull request can be found here