Summary
We noticed that users can only benefit from Intel OneDNN kernel in relay nn.dense op which implemented through OneDNN matmul by assigning “-libs=mkldnn” in target. And it still lacks of several commonly used kernel such as Conv2D and Pooling. Here we proposed this RFC to enrich the OP Strategy for X86 Conv2D kernels which implemented by Intel OneDNN.
Motivation
TVM performs as an E2E ML compiler stack for CPUs, GPUs and accelerators, people can benefit from its performance and convenience on ML models development. AutoShcheduler helps searching for a satisfactory states for different workloads, but it usually takes longer time. Users sometimes can achieve better performance when utilize a third party kernel library. Assigning a target flag like “-libs=mkldnn” seems to be the most easy way to guide Relay Op strategy to map to those 3rd party kernels, and it’s also a flexible way for silicon vendor to integrate their high performance kernels.
Intel OneDNN is an open-source cross-platform performance library of basic building blocks for deep learning applications. Using target flag could guide TVM to use external library with fully leverage the capability of Relay graph optimization. Additionally, using plain date format (NHWC) could naturally eliminating the overhead of layout transformation, that’s why we can see that plain data format(NHWC) already been integrated in TF and Pytorch.
In order to demonstrate the performance, we have some trials in different models. BTW. we’ve also observed that OneDNN Conv2d kernel achieves better performance when the layout format in NHWC, so we add it in TVM and enabled in Relay Op Strategy which only contains nn.dense kernel now. We’ve compared it with AutoScheduler on Resnet and Unet models in Intel Xeon Platinum 8352Y, both of them were run in NHWC format, seems it outperforms AutoSchedule in varying cores.
OneDNN version : V2.4.0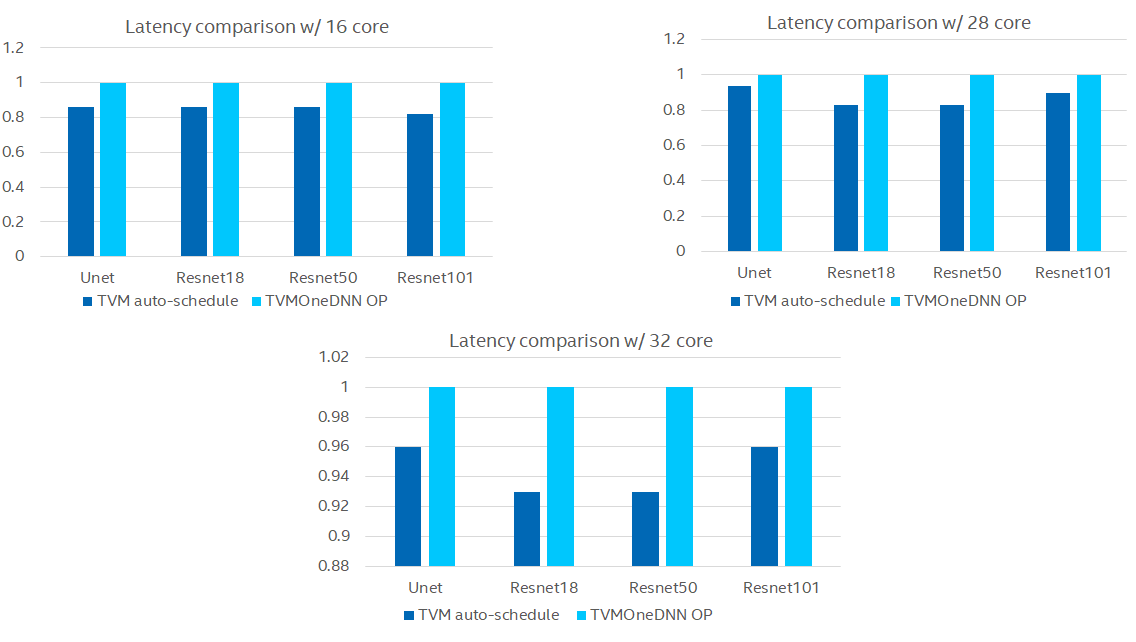
Proposal
This proposal mainly focused on integrating oneDNN OP implementation and mapping it in Relay Op Strategy. we’ve benched Conv2D kernel in NHWC format. and we are going to bench more oneDNN kernels including different format and datatypes in future.
- Add OneDNN conv2d kernel in NHWC format.
- Add ‘target.libs=mkldnn’ branch in Relay X86 OP strategy for NHWC Conv2D kernel.
- Add OneDNN primitive cache to improve the performance. and let OneDNN adaptively chose best format for weights. (Cause current OneDNN version still only support persistent primitive cache for GPU/FPGA engine).