
split op in relax after lowering to tir with DefaultGPUSchedule or dlight schedule
@T.prim_func(private=True)
def split(var_A: T.handle, var_T_split_sections: T.handle, var_T_split_sections_1: T.handle, var_T_split_sections_2: T.handle):
T.func_attr({"tir.is_scheduled": 1, "tir.noalias": T.bool(True)})
n = T.int32()
A = T.match_buffer(var_A, (1, n, 32, 240), "float16")
T_split_sections = T.match_buffer(var_T_split_sections, (1, n, 32, 80), "float16")
T_split_sections_1 = T.match_buffer(var_T_split_sections_1, (1, n, 32, 80), "float16")
T_split_sections_2 = T.match_buffer(var_T_split_sections_2, (1, n, 32, 80), "float16")
# with T.block("root"):
for ax0_ax1_ax2_fused_0 in T.thread_binding((n * 2560 + 1023) // 1024, thread="blockIdx.x"):
for ax0_ax1_ax2_fused_1 in T.thread_binding(1024, thread="threadIdx.x"):
with T.block("T_split_sections"):
v0 = T.axis.spatial(n, (ax0_ax1_ax2_fused_0 * 1024 + ax0_ax1_ax2_fused_1) // 2560)
v1 = T.axis.spatial(32, (ax0_ax1_ax2_fused_0 * 1024 + ax0_ax1_ax2_fused_1) % 2560 // 80)
v2 = T.axis.spatial(80, (ax0_ax1_ax2_fused_0 * 1024 + ax0_ax1_ax2_fused_1) % 80)
T.where(ax0_ax1_ax2_fused_0 * 1024 + ax0_ax1_ax2_fused_1 < n * 2560)
T.reads(A[0, v0, v1, v2])
T.writes(T_split_sections[0, v0, v1, v2])
T_split_sections[0, v0, v1, v2] = A[0, v0, v1, v2]
for ax0_ax1_ax2_fused_0 in T.thread_binding((n * 2560 + 1023) // 1024, thread="blockIdx.x"):
for ax0_ax1_ax2_fused_1 in T.thread_binding(1024, thread="threadIdx.x"):
with T.block("T_split_sections_1"):
v0 = T.axis.spatial(n, (ax0_ax1_ax2_fused_0 * 1024 + ax0_ax1_ax2_fused_1) // 2560)
v1 = T.axis.spatial(32, (ax0_ax1_ax2_fused_0 * 1024 + ax0_ax1_ax2_fused_1) % 2560 // 80)
v2 = T.axis.spatial(80, (ax0_ax1_ax2_fused_0 * 1024 + ax0_ax1_ax2_fused_1) % 80)
T.where(ax0_ax1_ax2_fused_0 * 1024 + ax0_ax1_ax2_fused_1 < n * 2560)
T.reads(A[0, v0, v1, v2 + 80])
T.writes(T_split_sections_1[0, v0, v1, v2])
T_split_sections_1[0, v0, v1, v2] = A[0, v0, v1, v2 + 80]
for ax0_ax1_ax2_fused_0 in T.thread_binding((n * 2560 + 1023) // 1024, thread="blockIdx.x"):
for ax0_ax1_ax2_fused_1 in T.thread_binding(1024, thread="threadIdx.x"):
with T.block("T_split_sections_2"):
v0 = T.axis.spatial(n, (ax0_ax1_ax2_fused_0 * 1024 + ax0_ax1_ax2_fused_1) // 2560)
v1 = T.axis.spatial(32, (ax0_ax1_ax2_fused_0 * 1024 + ax0_ax1_ax2_fused_1) % 2560 // 80)
v2 = T.axis.spatial(80, (ax0_ax1_ax2_fused_0 * 1024 + ax0_ax1_ax2_fused_1) % 80)
T.where(ax0_ax1_ax2_fused_0 * 1024 + ax0_ax1_ax2_fused_1 < n * 2560)
T.reads(A[0, v0, v1, v2 + 160])
T.writes(T_split_sections_2[0, v0, v1, v2])
T_split_sections_2[0, v0, v1, v2] = A[0, v0, v1, v2 + 160]
It will generate three seperate cuda kernels, it will introduce unnecessary kernel launch overhead
extern "C" __global__ void __launch_bounds__(1024) split_kernel(half* __restrict__ A, half* __restrict__ T_split_sections, int n) {
if (((((int)blockIdx.x) * 1024) + ((int)threadIdx.x)) < (n * 2560)) {
T_split_sections[((((int)blockIdx.x) * 1024) + ((int)threadIdx.x))] = A[(((((((int)blockIdx.x) * 64) + (((int)threadIdx.x) >> 4)) / 5) * 240) + (((((int)blockIdx.x) * 64) + ((int)threadIdx.x)) % 80))];
}
}
extern "C" __global__ void __launch_bounds__(1024) split_kernel_1(half* __restrict__ A, half* __restrict__ T_split_sections, int n) {
if (((((int)blockIdx.x) * 1024) + ((int)threadIdx.x)) < (n * 2560)) {
T_split_sections[((((int)blockIdx.x) * 1024) + ((int)threadIdx.x))] = A[((((((((int)blockIdx.x) * 64) + (((int)threadIdx.x) >> 4)) / 5) * 240) + (((((int)blockIdx.x) * 64) + ((int)threadIdx.x)) % 80)) + 80)];
}
}
extern "C" __global__ void __launch_bounds__(1024) split_kernel_2(half* __restrict__ A, half* __restrict__ T_split_sections, int n) {
if (((((int)blockIdx.x) * 1024) + ((int)threadIdx.x)) < (n * 2560)) {
T_split_sections[((((int)blockIdx.x) * 1024) + ((int)threadIdx.x))] = A[((((((((int)blockIdx.x) * 64) + (((int)threadIdx.x) >> 4)) / 5) * 240) + (((((int)blockIdx.x) * 64) + ((int)threadIdx.x)) % 80)) + 160)];
}
}
if i modify the lowerd TIR like this
@T.prim_func(private=True)
def WT_split(var_A: T.handle, var_T_split_sections: T.handle, var_T_split_sections_1: T.handle, var_T_split_sections_2: T.handle):
T.func_attr({"op_pattern": 2, "tir.noalias": T.bool(True)})
m = T.int64()
A = T.match_buffer(var_A, (T.int64(1), m, T.int64(32), T.int64(240)), "float16")
T_split_sections = T.match_buffer(var_T_split_sections, (T.int64(1), m, T.int64(32), T.int64(80)), "float16")
T_split_sections_1 = T.match_buffer(var_T_split_sections_1, (T.int64(1), m, T.int64(32), T.int64(80)), "float16")
T_split_sections_2 = T.match_buffer(var_T_split_sections_2, (T.int64(1), m, T.int64(32), T.int64(80)), "float16")
# with T.block("root"):
for ax0, ax1, ax2, ax3 in T.grid(T.int64(1), m, T.int64(32), T.int64(80)):
with T.block("T_split_sections"):
v_ax0, v_ax1, v_ax2, v_ax3 = T.axis.remap("SSSS", [ax0, ax1, ax2, ax3])
T.reads(A[v_ax0, v_ax1, v_ax2, v_ax3])
T.writes(T_split_sections[v_ax0, v_ax1, v_ax2, v_ax3],T_split_sections_1[v_ax0, v_ax1, v_ax2, v_ax3],T_split_sections_2[v_ax0, v_ax1, v_ax2, v_ax3])
T_split_sections[v_ax0, v_ax1, v_ax2, v_ax3] = A[v_ax0, v_ax1, v_ax2, v_ax3]
T_split_sections_1[v_ax0, v_ax1, v_ax2, v_ax3] = A[v_ax0, v_ax1, v_ax2, v_ax3 + T.int64(80)]
T_split_sections_2[v_ax0, v_ax1, v_ax2, v_ax3] = A[v_ax0, v_ax1, v_ax2, v_ax3 + T.int64(160)]
it will generate one cuda kernel
extern "C" __global__ void __launch_bounds__(1024) WT_split_kernel(half* __restrict__ A, half* __restrict__ T_split_sections, half* __restrict__ T_split_sections_1, half* __restrict__ T_split_sections_2, int64_t m) {
for (int64_t ax0_ax1_ax2_ax3_fused_0 = 0; ax0_ax1_ax2_ax3_fused_0 < (((m * (int64_t)5) + (int64_t)511) >> (int64_t)9); ++ax0_ax1_ax2_ax3_fused_0) {
if ((((ax0_ax1_ax2_ax3_fused_0 * (int64_t)262144) + (((int64_t)blockIdx.x) * (int64_t)1024)) + ((int64_t)threadIdx.x)) < (m * (int64_t)2560)) {
T_split_sections[(((ax0_ax1_ax2_ax3_fused_0 * (int64_t)262144) + (((int64_t)blockIdx.x) * (int64_t)1024)) + ((int64_t)threadIdx.x))] = A[((((((ax0_ax1_ax2_ax3_fused_0 * (int64_t)16384) + (((int64_t)blockIdx.x) * (int64_t)64)) + (((int64_t)threadIdx.x) >> (int64_t)4)) / (int64_t)5) * (int64_t)240) + ((((ax0_ax1_ax2_ax3_fused_0 * (int64_t)262144) + (((int64_t)blockIdx.x) * (int64_t)1024)) + ((int64_t)threadIdx.x)) % (int64_t)80))];
T_split_sections_1[(((ax0_ax1_ax2_ax3_fused_0 * (int64_t)262144) + (((int64_t)blockIdx.x) * (int64_t)1024)) + ((int64_t)threadIdx.x))] = A[(((((((ax0_ax1_ax2_ax3_fused_0 * (int64_t)16384) + (((int64_t)blockIdx.x) * (int64_t)64)) + (((int64_t)threadIdx.x) >> (int64_t)4)) / (int64_t)5) * (int64_t)240) + ((((ax0_ax1_ax2_ax3_fused_0 * (int64_t)262144) + (((int64_t)blockIdx.x) * (int64_t)1024)) + ((int64_t)threadIdx.x)) % (int64_t)80)) + (int64_t)80)];
T_split_sections_2[(((ax0_ax1_ax2_ax3_fused_0 * (int64_t)262144) + (((int64_t)blockIdx.x) * (int64_t)1024)) + ((int64_t)threadIdx.x))] = A[(((((((ax0_ax1_ax2_ax3_fused_0 * (int64_t)16384) + (((int64_t)blockIdx.x) * (int64_t)64)) + (((int64_t)threadIdx.x) >> (int64_t)4)) / (int64_t)5) * (int64_t)240) + ((((ax0_ax1_ax2_ax3_fused_0 * (int64_t)262144) + (((int64_t)blockIdx.x) * (int64_t)1024)) + ((int64_t)threadIdx.x)) % (int64_t)80)) + (int64_t)160)];
}
}
}
the conpared result on RTX3090, BigKernel-Split means the modified version, naive-Split means the default version
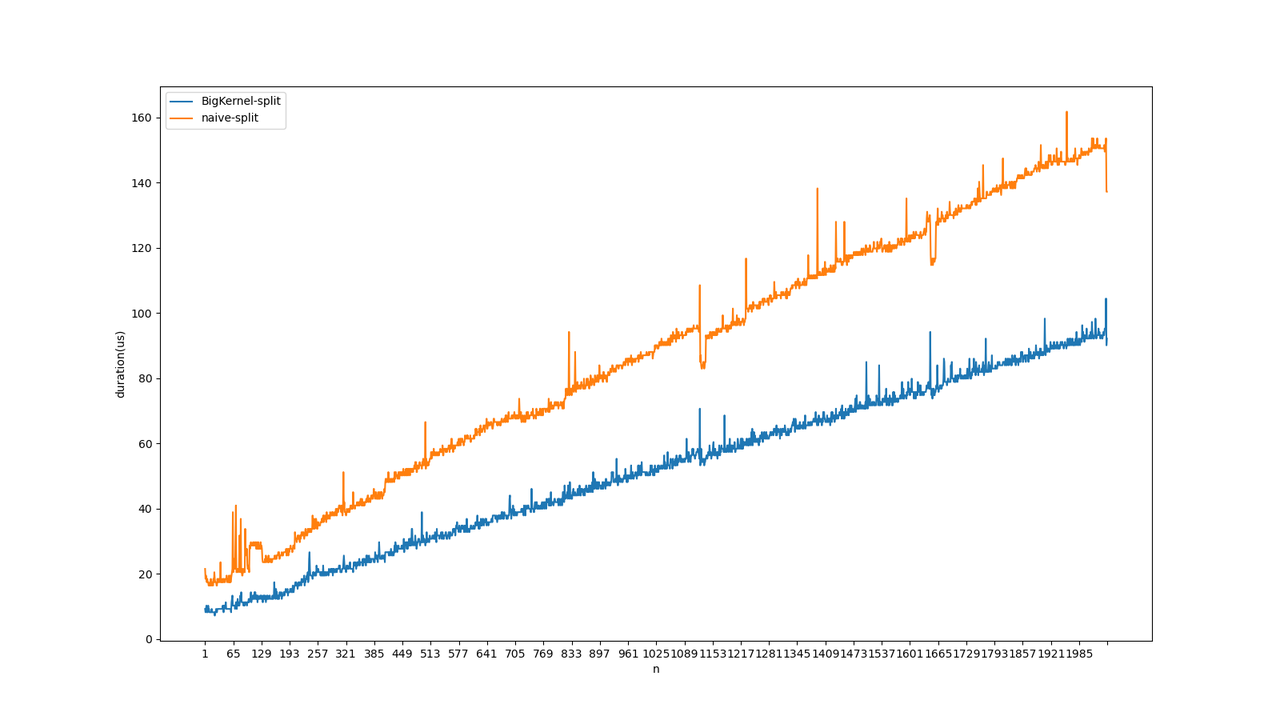
same pattern would occur in llms decoding part, usually split would be fused with reshape.
Is there a way to improve? Any idea?