Over the past year, the community has worked hard to bring in and transition to a more flexible and productive flow for ML compilers. One lesson we learned is that it is hard to build a silver bullet for everything. Additionally, given the amount of time and energy contributed by community volunteers, it is hard to build and maintain a single compiler pipeline that aims to fit all purposes, in our case, all backends and use cases. The engineering complexity inevitably grows as we try to grow the combination of models and backends and aim to fit everything into a single pipeline.
However, this does not render ML compilers useless. In fact, ML compilers are becoming increasingly important as new workloads, hardware primitives, and vertical use cases arise. Instead, the development and continuous improvement of vertical ML compilers should be part of the ML engineering process. Additionally, by enable such productive ML compiler development, we can afford to bring up vertical-specific compiler optimizations, for key use-cases like LLM and image detection models.
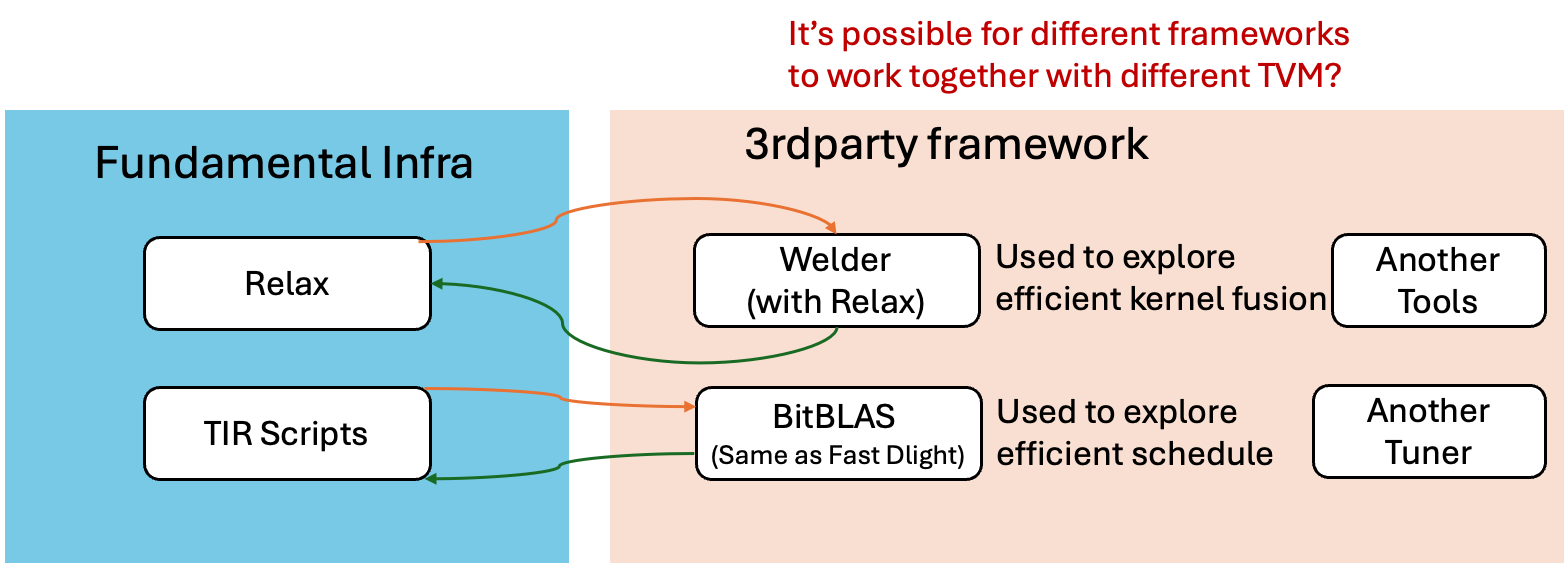
With that goal in mind, we still need to answer a question about “what should be the common infrastructure we provide can be shared across vertical flows”. The answer to such question has evolved since the project started. Over the past year, the community has converged toward the pattern:
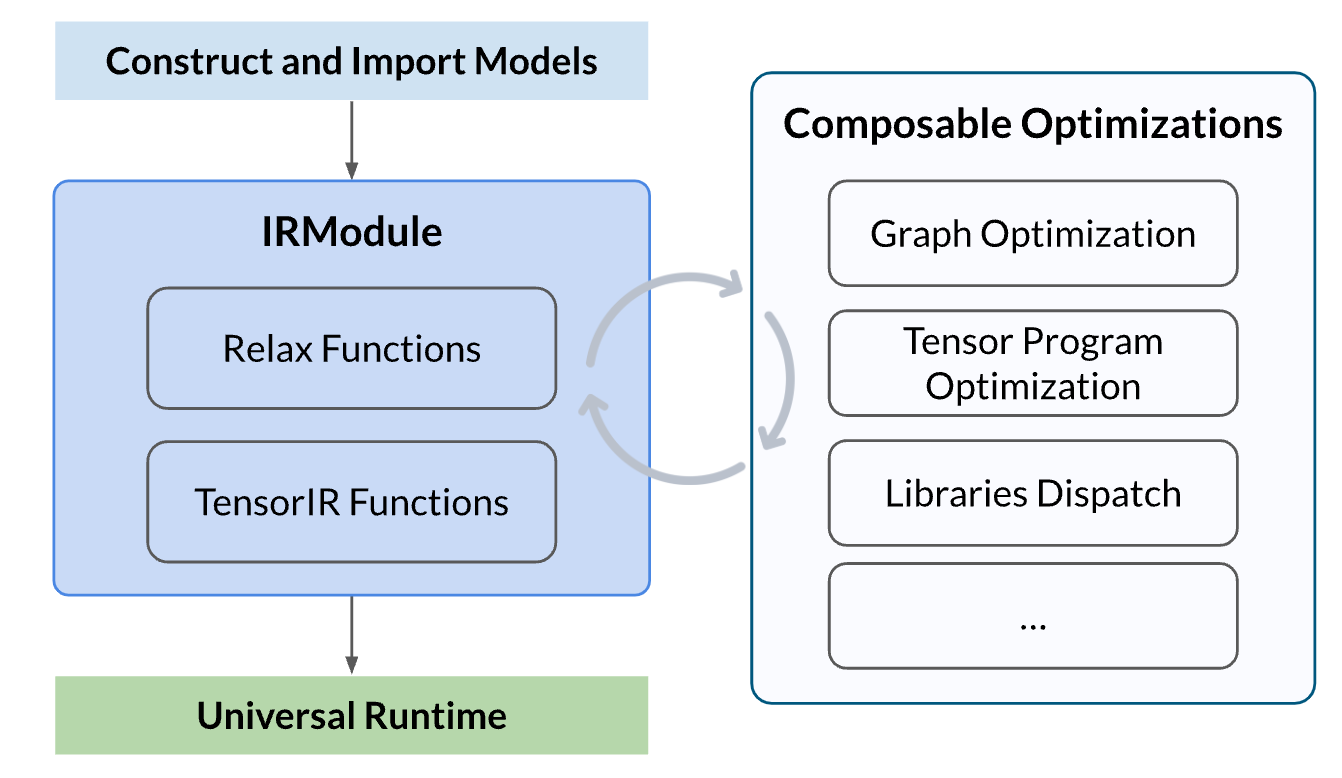
- Every program is encapsulated by an IRModule, with python-first printing/parsing support via TVMScript
- Optimizations and lowering are implemented as composable transformations on the IRModule
- A universal runtime mechanism(through tvm ffi) that naturally maps an IRModule to runnable component across different environments.
Throughout all these flows, TVMScript serves as a common tool to inspect and communicate the intermediate steps. By adopting this common flow, different optimizations and vertical compiler building can happen more organically. Importantly, it also allows us to strengthen the core while allowing downstream projects to add necessary customizations while making use of the existing pipelines when needed. Moving towards the lightweight flow also brings extra benefits in terms of testing. Because most of the optimizations and importing are tested via structural equality, we benefit from reduce test time and more unit-level correctness checkings.
Most of the new development as now centers around the new modular flow. In the meantime, we have been keeping the legacy components around for one year. We started to see challenges as some components get out of maintenance due to a lack of development. Additionally, because of the way some of the legacy components are structured, many tests require integration(instead of structural equality), taking much CI time and resources.
This post calls for us to move away from legacy components towards the new flow, specifically:
- Move away from relay toward relax as the graph IR
- Use TensorIR for tensor program schedule over te/schedule
- te remains as a useful tool to construct
tir.PrimFunc, but not necessarily the scheduling part. - Use dlight-style IRModule⇒IRModule transform for rule based scheduling that is compatible with the modular flow.
- te remains as a useful tool to construct
- Use MetaSchedule for autotuning, over autotvm and autoschedule
We encourage community contributions that centralizes the new flow, including improving frontends and modular optimizations based on the new approach. Importantly, these latest improvements will have less overhead for testing and technical coupling in general, as we can structure most of them via structural equality tests via TVMScript and IRModule⇒IRModule mechanism without introducing new mechanisms. Feel free to share thoughts.
As we gradually phase out the legacy components, they will remain available through release branches and taking maintainace patches. Coming back to the context, field of ML/AI is moving even faster, and we have gone several major changes in the recent wave of GenAI. These challenges are unique, and calls for a need for ML projects to reinvent themselves to stay relevant, or becoming irrelevant. After one year more development and learnings of the new flow, it is a right time for us to start the move.