@masahi I add ONNX for the experiments in the following and it seems using ONNX-runtime can get the best performance no matter the sequence length is (without tuning). I use ONNX-runtime with GraphOptimizationLevel.ORT_ENABLE_ALL showing in this link. Besides, I plot the IR graph for ONNX, which is quite complicated.
Experiment 1 - Different Target

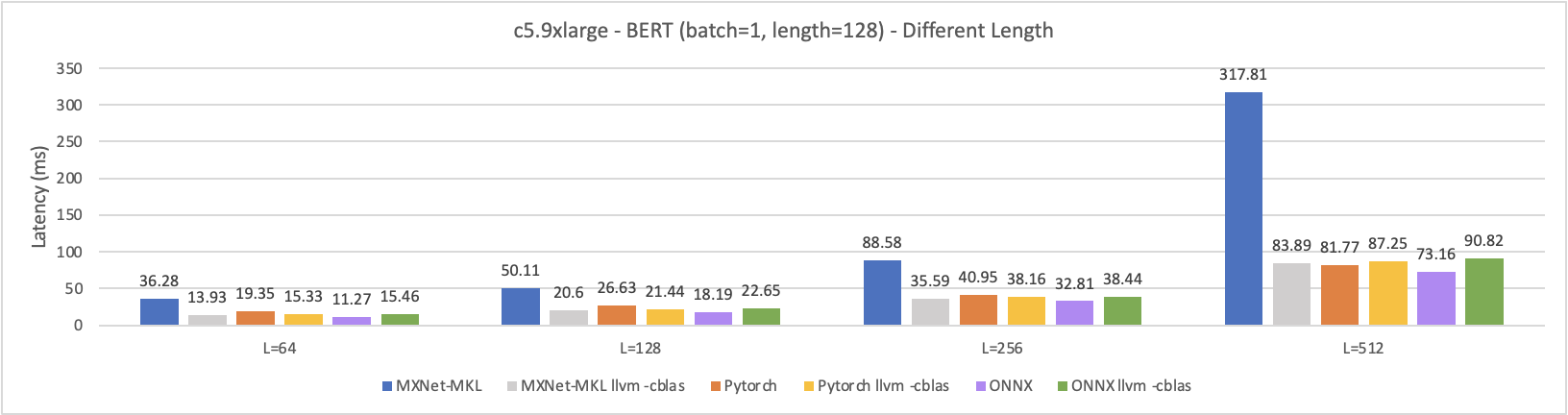
Experiment 3 - Different Length
- ONNX IR Graph: drive link
Also, I have some questions about AutoSchedule tuning.
-
Q1: @merrymercy I was confused that when I use AutoSchedule to tune TVM, can I use target like
llvm -libs=cblasor I should use onlyllvm. I found this will give different tasks to tune. -
Q2: @comaniac I think MXNet IR is more friendly than Pytorch IR for AutoSchedule tuning. I set the same parameters for tuning but Pytorch cannot get the results as MXNet (16ms for seq_len=128) The following are their tuning tasks and it seems quite different due to different IR graph. I still work on where the problem comes from, TVM front-end or original code implementation. But I think maybe TVM will have some transforms to generate similar IR graph even if from different framework.
- 1st difference: MXNet will use
nn.bias_add()and Pytorch will userelay.add(), which cause the tuning tasks not include this operation. (task 0,1,2,6) - 2nd difference: Their attention softmax operation have different shape, but I think this doesn’t cause too much latency difference (task 4)
- 1st difference: MXNet will use
# Tasks for Pytorch AutoSchedule Tuning (Target = llvm)
========== Task 0 (workload key: ["61f56dfd63fda28bc8bcf85739c8e9e3", 128, 3072, 768, 3072, 128, 768]) ==========
placeholder = PLACEHOLDER [128, 3072]
placeholder = PLACEHOLDER [768, 3072]
T_dense(i, j) += (placeholder[i, k]*placeholder[j, k])
========== Task 1 (workload key: ["61f56dfd63fda28bc8bcf85739c8e9e3", 128, 768, 3072, 768, 128, 3072]) ==========
placeholder = PLACEHOLDER [128, 768]
placeholder = PLACEHOLDER [3072, 768]
T_dense(i, j) += (placeholder[i, k]*placeholder[j, k])
========== Task 2 (workload key: ["61f56dfd63fda28bc8bcf85739c8e9e3", 128, 768, 768, 768, 128, 768]) ==========
placeholder = PLACEHOLDER [128, 768]
placeholder = PLACEHOLDER [768, 768]
T_dense(i, j) += (placeholder[i, k]*placeholder[j, k])
========== Task 3 (workload key: ["d2a28fdf41e83222456f5a6e5bf8a24a", 12, 128, 128, 12, 64, 128, 12, 128, 64]) ==========
placeholder = PLACEHOLDER [12, 128, 128]
placeholder = PLACEHOLDER [12, 64, 128]
compute(b, i, j) += (placeholder[b, i, k]*placeholder[b, j, k])
========== Task 4 (workload key: ["868c2771b1610bdac0ac73167691f4eb", 1, 12, 128, 128, 1, 12, 128, 128]) ==========
placeholder = PLACEHOLDER [1, 12, 128, 128]
T_softmax_maxelem(i0, i1, i2) max= placeholder[i0, i1, i2, k]
T_softmax_delta(i0, i1, i2, i3) = (placeholder[i0, i1, i2, i3] - T_softmax_maxelem[i0, i1, i2])
T_fast_exp(ax0, ax1, ax2, ax3) = max((tir.reinterpret(tir.shift_left(int32((tir.floor(((max(min(T_softmax_delta[ax0, ax1, ax2, a ..(OMITTED).. max_delta[ax0, ax1, ax2, ax3], 88.3763f), -88.3763f)*1.4427f) + 0.5f))*0.693147f))) + 1f)), T_softmax_delta[ax0, ax1, ax2, ax3])
T_softmax_expsum(i0, i1, i2) += T_fast_exp[i0, i1, i2, k]
T_softmax_norm(i0, i1, i2, i3) = (T_fast_exp[i0, i1, i2, i3]/T_softmax_expsum[i0, i1, i2])
========== Task 5 (workload key: ["d2a28fdf41e83222456f5a6e5bf8a24a", 12, 128, 64, 12, 128, 64, 12, 128, 128]) ==========
placeholder = PLACEHOLDER [12, 128, 64]
placeholder = PLACEHOLDER [12, 128, 64]
compute(b, i, j) += (placeholder[b, i, k]*placeholder[b, j, k])
========== Task 6 (workload key: ["61f56dfd63fda28bc8bcf85739c8e9e3", 128, 768, 2304, 768, 128, 2304]) ==========
placeholder = PLACEHOLDER [128, 768]
placeholder = PLACEHOLDER [2304, 768]
T_dense(i, j) += (placeholder[i, k]*placeholder[j, k])
========== Task 7 (workload key: ["2dde9ffcbf97381c0f0307643e09dac5", 1, 128, 768, 1, 128, 1]) ==========
placeholder = PLACEHOLDER [1, 128, 768]
placeholder_red(ax0, ax1, ax2) += placeholder[ax0, ax1, k2]
T_divide(ax0, ax1, ax2) = (placeholder_red[ax0, ax1, ax2]/768f)
========== Task 8 (workload key: ["dde89265d3f1a59075cee648386eac1e", 1, 128, 768, 1, 128, 1, 1, 128, 1]) ==========
placeholder = PLACEHOLDER [1, 128, 768]
placeholder = PLACEHOLDER [1, 128, 1]
T_subtract(ax0, ax1, ax2) = (placeholder[ax0, ax1, ax2] - placeholder[ax0, ax1, 0])
T_multiply(ax0, ax1, ax2) = (T_subtract[ax0, ax1, ax2]*T_subtract[ax0, ax1, ax2])
T_multiply_red(ax0, ax1, ax2) += T_multiply[ax0, ax1, k2]
T_divide(ax0, ax1, ax2) = (T_multiply_red[ax0, ax1, ax2]/768f)
========== Task 9 (workload key: ["9e3bd222d4f8d250aeadf2fef0b15f2b", 1, 768, 768, 768, 768, 1, 768]) ==========
placeholder = PLACEHOLDER [1, 768]
placeholder = PLACEHOLDER [768, 768]
T_dense(i, j) += (placeholder[i, k]*placeholder[j, k])
placeholder = PLACEHOLDER [768]
T_add(ax0, ax1) = (T_dense[ax0, ax1] + placeholder[ax1])
T_minimum(ax0, ax1) = min(T_add[ax0, ax1], 9f)
T_maximum(ax0, ax1) = max(T_minimum[ax0, ax1], -9f)
T_fast_tanh(ax0, ax1) = ((T_maximum[ax0, ax1]*(((T_maximum[ax0, ax1]*T_maximum[ax0, ax1])*(((T_maximum[ax0, ax1]*T_maximum[ax0, ..(OMITTED).. *T_maximum[ax0, ax1])*(((T_maximum[ax0, ax1]*T_maximum[ax0, ax1])*1.19826e-06f) + 0.000118535f)) + 0.00226843f)) + 0.00489353f))
# Tasks for MXNet AutoSchedule Tuning (Target = llvm)
========== Task 0 (workload key: ["9847f8cc0b305137f49f2c5c0c8ab25d", 128, 3072, 768, 3072, 768, 128, 768]) ==========
placeholder = PLACEHOLDER [128, 3072]
placeholder = PLACEHOLDER [768, 3072]
T_dense(i, j) += (placeholder[i, k]*placeholder[j, k])
placeholder = PLACEHOLDER [768]
T_add(ax0, ax1) = (T_dense[ax0, ax1] + placeholder[ax1])
========== Task 1 (workload key: ["9847f8cc0b305137f49f2c5c0c8ab25d", 128, 768, 3072, 768, 3072, 128, 3072]) ==========
placeholder = PLACEHOLDER [128, 768]
placeholder = PLACEHOLDER [3072, 768]
T_dense(i, j) += (placeholder[i, k]*placeholder[j, k])
placeholder = PLACEHOLDER [3072]
T_add(ax0, ax1) = (T_dense[ax0, ax1] + placeholder[ax1])
========== Task 2 (workload key: ["9847f8cc0b305137f49f2c5c0c8ab25d", 128, 768, 768, 768, 768, 128, 768]) ==========
placeholder = PLACEHOLDER [128, 768]
placeholder = PLACEHOLDER [768, 768]
T_dense(i, j) += (placeholder[i, k]*placeholder[j, k])
placeholder = PLACEHOLDER [768]
T_add(ax0, ax1) = (T_dense[ax0, ax1] + placeholder[ax1])
========== Task 3 (workload key: ["d2a28fdf41e83222456f5a6e5bf8a24a", 12, 128, 128, 12, 64, 128, 12, 128, 64]) ==========
placeholder = PLACEHOLDER [12, 128, 128]
placeholder = PLACEHOLDER [12, 64, 128]
compute(b, i, j) += (placeholder[b, i, k]*placeholder[b, j, k])
========== Task 4 (workload key: ["4b5e216f8244b4e8f7b6543c4a9087e5", 1536, 128, 1536, 128]) ==========
placeholder = PLACEHOLDER [1536, 128]
T_softmax_maxelem(i0) max= placeholder[i0, k]
T_softmax_delta(i0, i1) = (placeholder[i0, i1] - T_softmax_maxelem[i0])
T_fast_exp(ax0, ax1) = max((tir.reinterpret(tir.shift_left(int32((tir.floor(((max(min(T_softmax_delta[ax0, ax1], 88.3763f), -88. ..(OMITTED).. oor(((max(min(T_softmax_delta[ax0, ax1], 88.3763f), -88.3763f)*1.4427f) + 0.5f))*0.693147f))) + 1f)), T_softmax_delta[ax0, ax1])
T_softmax_expsum(i0) += T_fast_exp[i0, k]
T_softmax_norm(i0, i1) = (T_fast_exp[i0, i1]/T_softmax_expsum[i0])
========== Task 5 (workload key: ["d2a28fdf41e83222456f5a6e5bf8a24a", 12, 128, 64, 12, 128, 64, 12, 128, 128]) ==========
placeholder = PLACEHOLDER [12, 128, 64]
placeholder = PLACEHOLDER [12, 128, 64]
compute(b, i, j) += (placeholder[b, i, k]*placeholder[b, j, k])
========== Task 6 (workload key: ["9847f8cc0b305137f49f2c5c0c8ab25d", 128, 768, 2304, 768, 2304, 128, 2304]) ==========
placeholder = PLACEHOLDER [128, 768]
placeholder = PLACEHOLDER [2304, 768]
T_dense(i, j) += (placeholder[i, k]*placeholder[j, k])
placeholder = PLACEHOLDER [2304]
T_add(ax0, ax1) = (T_dense[ax0, ax1] + placeholder[ax1])
========== Task 7 (workload key: ["2dde9ffcbf97381c0f0307643e09dac5", 128, 1, 768, 128, 1, 1]) ==========
placeholder = PLACEHOLDER [128, 1, 768]
placeholder_red(ax0, ax1, ax2) += placeholder[ax0, ax1, k2]
T_divide(ax0, ax1, ax2) = (placeholder_red[ax0, ax1, ax2]/768f)
========== Task 8 (workload key: ["dde89265d3f1a59075cee648386eac1e", 128, 1, 768, 128, 1, 1, 128, 1, 1]) ==========
placeholder = PLACEHOLDER [128, 1, 768]
placeholder = PLACEHOLDER [128, 1, 1]
T_subtract(ax0, ax1, ax2) = (placeholder[ax0, ax1, ax2] - placeholder[ax0, ax1, 0])
T_multiply(ax0, ax1, ax2) = (T_subtract[ax0, ax1, ax2]*T_subtract[ax0, ax1, ax2])
T_multiply_red(ax0, ax1, ax2) += T_multiply[ax0, ax1, k2]
T_divide(ax0, ax1, ax2) = (T_multiply_red[ax0, ax1, ax2]/768f)
========== Task 9 (workload key: ["9e3bd222d4f8d250aeadf2fef0b15f2b", 1, 768, 768, 768, 768, 1, 768]) ==========
placeholder = PLACEHOLDER [1, 768]
placeholder = PLACEHOLDER [768, 768]
T_dense(i, j) += (placeholder[i, k]*placeholder[j, k])
placeholder = PLACEHOLDER [768]
T_add(ax0, ax1) = (T_dense[ax0, ax1] + placeholder[ax1])
T_minimum(ax0, ax1) = min(T_add[ax0, ax1], 9f)
T_maximum(ax0, ax1) = max(T_minimum[ax0, ax1], -9f)
T_fast_tanh(ax0, ax1) = ((T_maximum[ax0, ax1]*(((T_maximum[ax0, ax1]*T_maximum[ax0, ax1])*(((T_maximum[ax0, ax1]*T_maximum[ax0, ..(OMITTED).. *T_maximum[ax0, ax1])*(((T_maximum[ax0, ax1]*T_maximum[ax0, ax1])*1.19826e-06f) + 0.000118535f)) + 0.00226843f)) + 0.00489353f))
Sorry for my lots of questions. I’ll do my best to do more experiments and figure out the reasons why Pytorch AutoSchedule not working as MXNet and why TVM is not working as expected when sequence length increasing.