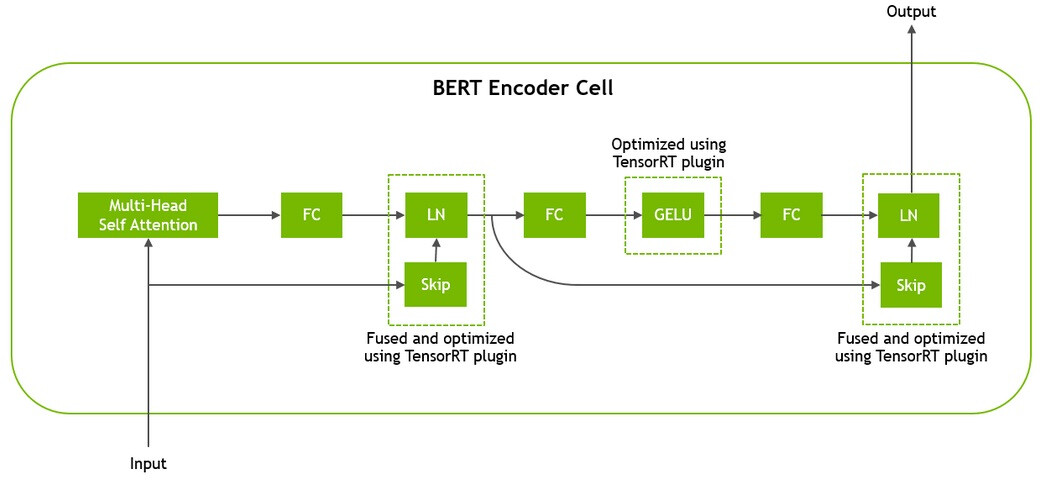
I do some experiments to test whether TVM can help accelerate BERT inference. I use Huggingface to load bert_base_uncased as my model and try to follow your tutorials. The following are my environment settings and the results. Can anyone have any ideas why TVM is not working with a great improvement?
Environment Settings
- CPU: m5.2 instance on Amazon EC2
- Host CPU: skylake-avx512
- Requirements:
conda env create --file conda/build-environment.yaml (default in TVM)
conda install --no-update-deps -y -c conda-forge openblas==0.3.12
conda install --no-update-deps -y -c intel mkl-include==2021.2.0
conda install --no-update-deps -y -c intel mkl==2021.2.0
pip install transformers==4.6.1 torch==1.7.1 decorator==5.0.9 attrs==20.2.0 tornado==6.1 xgboost==1.4.2 cloudpickle==1.6.0 psutil==5.8.0
- config.cmake:
set(USE_LLVM ON)
set(USE_BLAS openblas)
set(USE_MKL ON)
set(USE_MKLDNN /home/chengpi/projects/dnnl_lnx_2.2.0_cpu_iomp)
set(USE_OPENMP intel)
set(USE_NNPACK ON)
set(NNPACK_PATH /home/chengpi/projects/NNPACK)
# other parameters are default
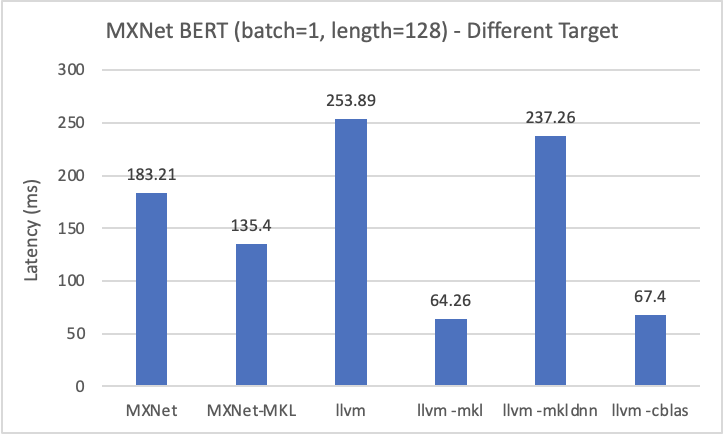
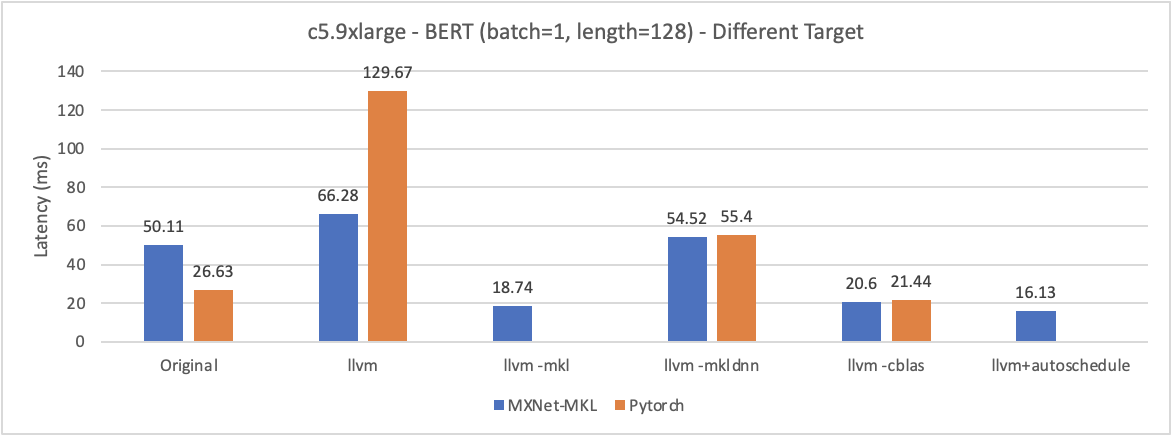
Experiment1 - Different Target

- Q1: why
-libs=cblascan have the best results rather than usingmklormkl-dnn? - Q2: why
-libs=mklI will get the following error; however, when using MXnet instead of Pytorch the error is disappear.
AttributeError: Traceback (most recent call last):
25: TVMFuncCall
24: std::_Function_handler<void (tvm::runtime::TVMArgs, tvm::runtime::TVMRetValue*), tvm::relay::backend::RelayBuildModule::GetFunction(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, tvm::runtime::ObjectPtr<tvm::runtime::Object> const&)::{lambda(tvm::runtime::TVMArgs, tvm::runtime::TVMRetValue*)#3}>::_M_invoke(std::_Any_data const&, tvm::runtime::TVMArgs&&, tvm::runtime::TVMRetValue*&&)
23: tvm::relay::backend::RelayBuildModule::BuildRelay(tvm::IRModule, std::unordered_map<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, tvm::runtime::NDArray, std::hash<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::equal_to<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, tvm::runtime::NDArray> > > const&)
22: std::_Function_handler<void (tvm::runtime::TVMArgs, tvm::runtime::TVMRetValue*), tvm::relay::backend::GraphExecutorCodegenModule::GetFunction(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, tvm::runtime::ObjectPtr<tvm::runtime::Object> const&)::{lambda(tvm::runtime::TVMArgs, tvm::runtime::TVMRetValue*)#2}>::_M_invoke(std::_Any_data const&, tvm::runtime::TVMArgs&&, tvm::runtime::TVMRetValue*&&)
21: tvm::relay::backend::GraphExecutorCodegen::Codegen(tvm::relay::Function)
20: tvm::relay::backend::MemoizedExprTranslator<std::vector<tvm::relay::backend::GraphNodeRef, std::allocator<tvm::relay::backend::GraphNodeRef> > >::VisitExpr(tvm::RelayExpr const&)
19: _ZZN3tvm5relay11ExprFunc
18: tvm::relay::backend::GraphExecutorCodegen::VisitExpr_(tvm::relay::TupleNode const*)
17: tvm::relay::backend::MemoizedExprTranslator<std::vector<tvm::relay::backend::GraphNodeRef, std::allocator<tvm::relay::backend::GraphNodeRef> > >::VisitExpr(tvm::RelayExpr const&)
16: _ZZN3tvm5relay11ExprFunc
15: tvm::relay::backend::GraphExecutorCodegen::VisitExpr_(tvm::relay::CallNode const*)
14: tvm::relay::backend::GraphExecutorCodegen::GraphAddCallNode(tvm::relay::CallNode const*, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::unordered_map<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, dmlc::any, std::hash<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::equal_to<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, dmlc::any> > >)
13: tvm::relay::backend::MemoizedExprTranslator<std::vector<tvm::relay::backend::GraphNodeRef, std::allocator<tvm::relay::backend::GraphNodeRef> > >::VisitExpr(tvm::RelayExpr const&)
12: _ZZN3tvm5relay11ExprFunc
11: tvm::relay::backend::GraphExecutorCodegen::VisitExpr_(tvm::relay::CallNode const*)
10: tvm::relay::backend::GraphExecutorCodegen::GraphAddCallNode(tvm::relay::CallNode const*, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::unordered_map<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, dmlc::any, std::hash<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::equal_to<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, dmlc::any> > >)
9: tvm::relay::backend::MemoizedExprTranslator<std::vector<tvm::relay::backend::GraphNodeRef, std::allocator<tvm::relay::backend::GraphNodeRef> > >::VisitExpr(tvm::RelayExpr const&)
8: _ZZN3tvm5relay11ExprFunc
7: tvm::relay::backend::GraphExecutorCodegen::VisitExpr_(tvm::relay::CallNode const*)
6: tvm::runtime::TVMRetValue tvm::runtime::PackedFunc::operator()<tvm::relay::CompileEngine&, tvm::relay::CCacheKey&>(tvm::relay::CompileEngine&, tvm::relay::CCacheKey&) const
5: std::_Function_handler<void (tvm::runtime::TVMArgs, tvm::runtime::TVMRetValue*), void tvm::runtime::TypedPackedFunc<tvm::relay::CachedFunc (tvm::relay::CompileEngine, tvm::relay::CCacheKey)>::AssignTypedLambda<tvm::relay::{lambda(tvm::relay::CompileEngine, tvm::relay::CCacheKey)#9}>(tvm::relay::{lambda(tvm::relay::CompileEngine, tvm::relay::CCacheKey)#9}, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >)::{lambda(tvm::runtime::TVMArgs const&, tvm::runtime::TVMRetValue*)#1}>::_M_invoke(std::_Any_data const&, tvm::runtime::TVMArgs&&, tvm::runtime::TVMRetValue*&&)
4: tvm::relay::CompileEngineImpl::LowerInternal(tvm::relay::CCacheKey const&)
3: tvm::relay::CreateSchedule(tvm::relay::Function const&, tvm::Target const&)
2: tvm::relay::ScheduleGetter::Create(tvm::relay::Function const&)
1: tvm::relay::OpImplementation::Schedule(tvm::Attrs const&, tvm::runtime::Array<tvm::te::Tensor, void> const&, tvm::Target const&)
0: std::_Function_handler<void (tvm::runtime::TVMArgs, tvm::runtime::TVMRetValue*), TVMFuncCreateFromCFunc::{lambda(tvm::runtime::TVMArgs, tvm::runtime::TVMRetValue*)#2}>::_M_invoke(std::_Any_data const&, tvm::runtime::TVMArgs&&, tvm::runtime::TVMRetValue*&&)
File "/home/chengpi/projects/tvm/python/tvm/runtime/object.py", line 63, in __getattr__
return _ffi_node_api.NodeGetAttr(self, name)
File "/home/chengpi/projects/tvm/python/tvm/_ffi/_ctypes/packed_func.py", line 237, in __call__
raise get_last_ffi_error()
3: TVMFuncCall
2: _ZNSt17_Function_handlerI
1: tvm::NodeGetAttr(tvm::runtime::TVMArgs, tvm::runtime::TVMRetValue*)
0: tvm::ReflectionVTable::GetAttr(tvm::runtime::Object*, tvm::runtime::String const&) const
File "../src/node/reflection.cc", line 110
File "/home/chengpi/projects/tvm/python/tvm/_ffi/_ctypes/packed_func.py", line 81, in cfun
rv = local_pyfunc(*pyargs)
File "/home/chengpi/projects/tvm/python/tvm/relay/op/strategy/generic.py", line 51, in wrapper
return topi_schedule(outs)
File "/home/chengpi/projects/tvm/python/tvm/autotvm/task/topi_integration.py", line 235, in wrapper
return topi_schedule(cfg, outs, *args, **kwargs)
File "/home/chengpi/projects/tvm/python/tvm/topi/x86/dense.py", line 338, in schedule_dense_mkl
schedule_injective_from_existing(s, out)
File "/home/chengpi/projects/tvm/python/tvm/topi/x86/injective.py", line 39, in schedule_injective_from_existing
if len(sch[out].op.axis) >= 5:
File "/home/chengpi/projects/tvm/python/tvm/runtime/object.py", line 65, in __getattr__
raise AttributeError("%s has no attribute %s" % (str(type(self)), name))
AttributeError: ExternOp object has no attributed axis
During handling of the above exception, another exception occurred:
Experiment2 - Different Tune
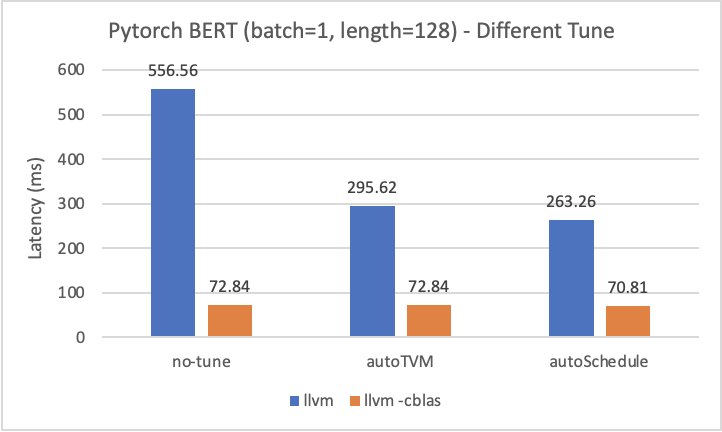
- Q1: why using target
llvm -libs=cblastuning seems to not working? And using targetllvmwe can see autoSchedule have the best performance.
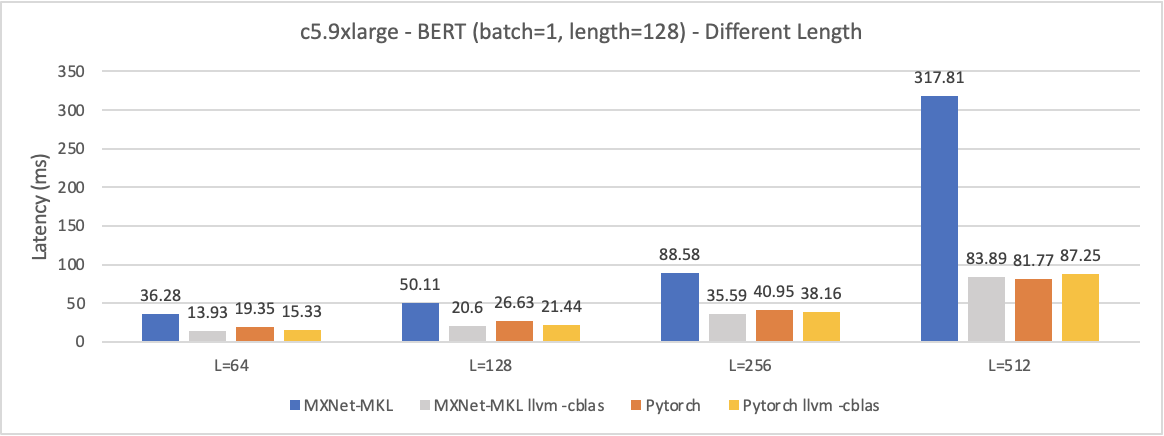
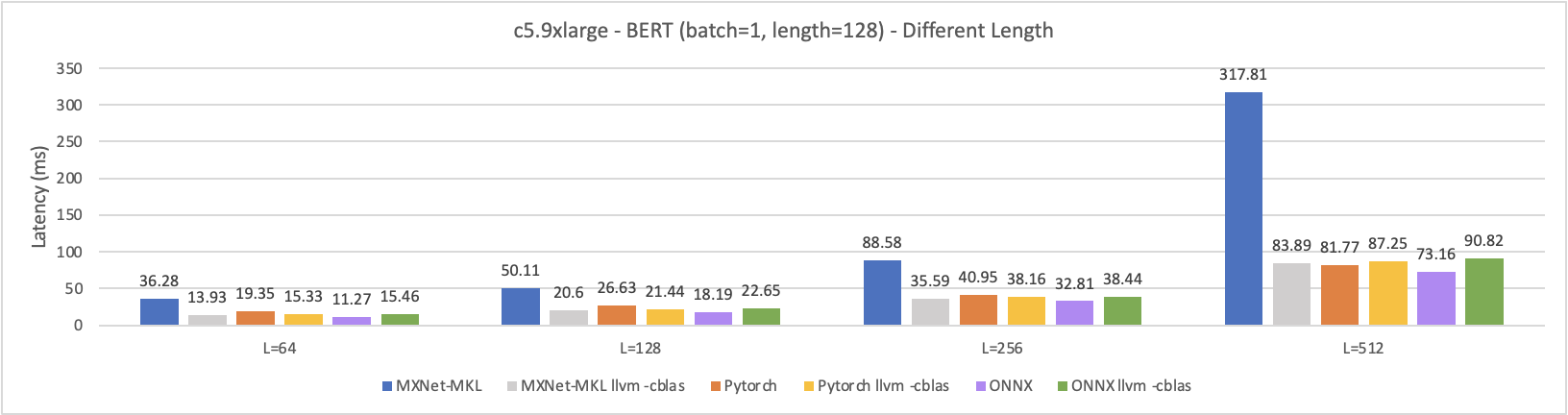
Experiment3 - Different Length
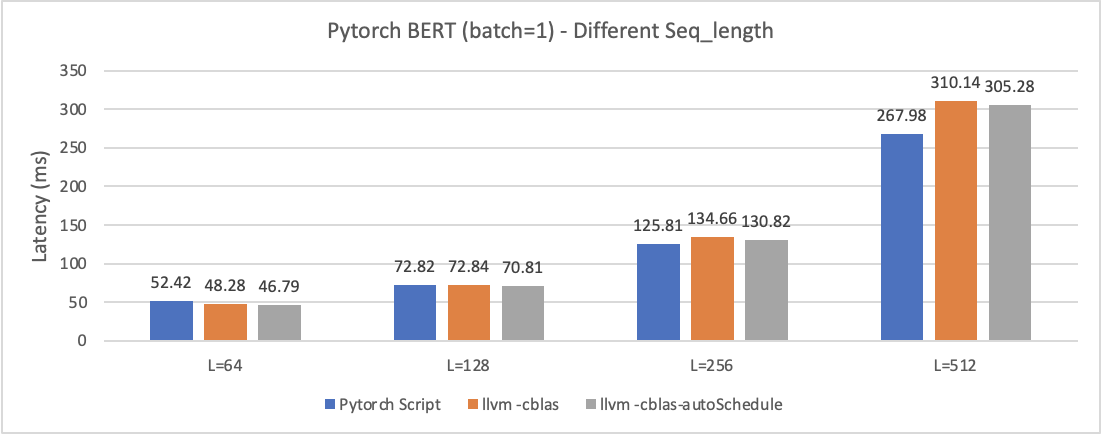
- Q1: When the sequence length is short, we can find tuning have a little improvement even beat the original pytorch results. However, when the length is long, we have worse performance than original pytorch. Can anyone explain what is going on?
I was wondering whether I forget something to setup for the best performance. I look forward to anyone’s help. Thanks a lot!!