Hi everyone,
I am trying to develop a python-based script that transforms relay ir to Caffe model accepted by our fixed point accelerator.
However, I encounter some problem when trying to visit the relay graph with merged composition.
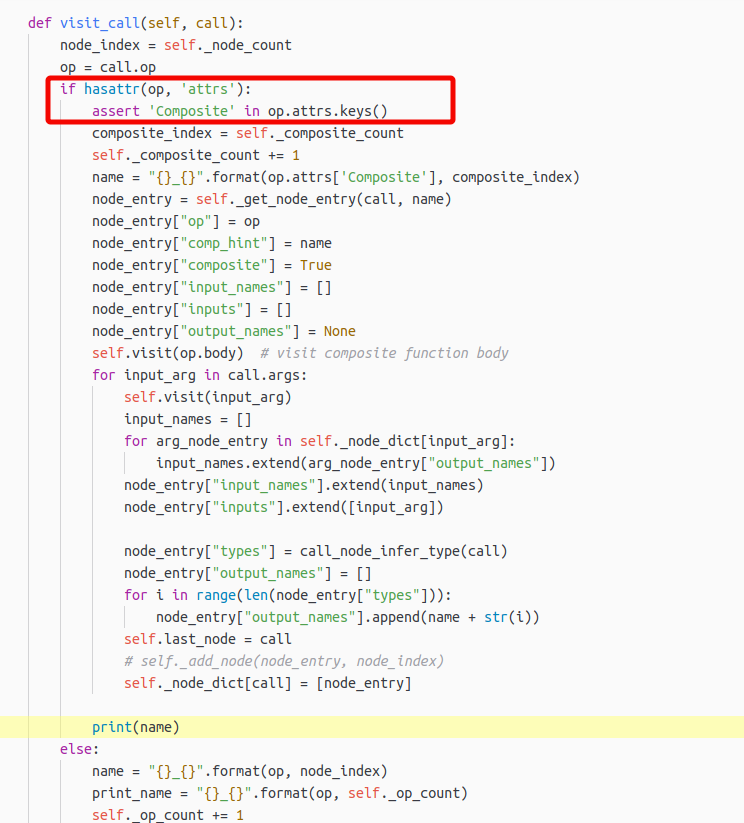
Below is a similar code piece that I modified based on the contrib/target/onnx.py:
It indeed visited the composite function and the “component” ops as well (after visit(op.body)), but my question is how to record the connection, i.e., how do I know the specific operators that a composite function contains?
Both relay to ONNX and CoreML work follow the flow that transform op one-by-one.
However, merged composite pattern is one important step in BYOC. So I think there must be a solution here.
I tried ExactFusedFunctions as well, but that method is looing for “main” symbol in the function, won’t work.
Since the subgraph I got is the accelerated part, it does not have a “main” symbol in the relay, instead a global symbol like the hardware annotation, e.g., “acc_xx”.
Thank you, Cody.
I think I will go the second way, becasue I need to extract the necessary information to build a caffe layer based on a composite function.
I noticed that there is some codegen snippet from ARM contributed, doing similar process in C++, but nothing in Python found yet. I guess I have to do it on my own.
I would like to ask how to deal with the bias of Caffe convolution layer when transform Relay IR to Caffe. If possible, can you share the Python script for Relay IR to Caffe?
By pattern annotation:
qnn.op.conv2d+nn.bias_add+qnn.op.requantize, it corresponds to a complete INT8 CONV with bias layer in Caffe.
The code is too specific to the target hardware and I don’t think it’s more valuable than a generalized float32 conversion one.
However, for fixed point accelerator, it should be always a requantize op followed at the end.