When I use ‘relay.frontend.from_tensorflow’ to load a .pb model, which is a QAT model with FakeQuantWithMinMaxVars. And the error occurs: NotImplementedError: The following operators are not implemented: {‘FakeQuantWithMinMaxVars’}. I have read thishttps://discuss.tvm.apache.org/t/tensorflow-operator-fakequantwithminmaxvars-not-implemented/706 post, and my question is that how can we support .pb model with fakeQuantNode in TVM directly?
I faced a similar issue with a QAT model as well recently, and stumbled on the same post you mentioned there. After searching around a bit, I understood that the problem with supporting FakeQuantWithMinMaxVars directly is that it doesn’t directly correspond to any combination of relay operators.
Ideally this should have been as easy as introducing a sequence of qnn.quantize → qnn.dequantize. But According to the tensorflow docs for FakeQuantWithMinMaxVars, the computation is not the same as quantize and dequantize in a traditional sense, which I believe is to make it differentiable for training (I’m not an expert in quantization, so don’t take my word for this).
Anyway, I think the easiest solution to this, and what I did as well was to convert to tflite and then import the model. If you would really like to support FakeQuantWithMinMaxVars, I guess you could try to understand exactly how that op gets translated to Quantize → Dequantize structure, and recreate that in the tensorflow importer.
@sanirudh Thanks for your reply. I would want ask when you convert the pb model(floating point)to tflite model, you just remove the FakeQuantWithMinMaxVars nodes(tflite model still floating point)? Or you will convert the floating point model to fixed point model at the same time?As we know, when we deploy a QAT model, we may quantitate it to get better performance.
Hi @RussellRao, happy to help :).
When you export a model as tflite (with tflite converter perhaps) it automatically changes the FakeQuantWithMinMaxVars nodes into a pairs of Quantize -> Dequantize nodes. This can be directly imported into TVM where they get imported as qnn.quantize -> qnn.dequantize nodes.
Then we can run the FakeQuantizationToInteger pass. This pass will replace the floating point ops with fixed_point variants using the quantization params from the surrounding qnn.dequantize and qnn.quantize.
For example, if you have a subgraph of qnn.dequantize -> nn.conv2d -> qnn.quantize, this gets replaced into a qnn.conv2d op. Here the original nn.conv2d was working with floating point operations and the new qnn.conv2d works with fixed point using the quant params taken from the surrounding qnn.dequantize and qnn.quantize.
1 Like
Hi @sanirudh Thanks a lot, I will have a try 
1 Like
Hi @sanirudh ,A part of my origin pb model is:
, and then I use toco to convert this pb model to tflite model: . From above result, we see the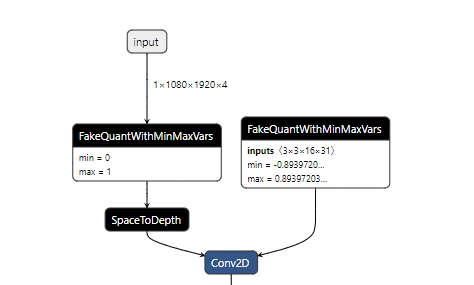
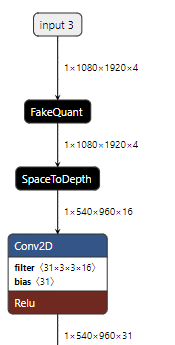
FakeQuantWithMinMaxVars node is converted to FakeQuant node, and I print the relay ir before optimized: ,
it seems that the 
FakeQuant node was divided into many basic ops which I think equal to quantize + dequantize. My question is that: in this process, I didnt see the pairs of Quantize → Dequantize` nodes, is there any wrong? Looking forward to your reply, thanks~
I’m not familiar with the TOCO converter, so don’t know why it generates another FakeQuant Node in tflite.
In this case, after we import the model, it does seem like a quantize and dequantize is implemented using a bunch of ops, but that is a problem as we need the actual qnn.quantize and qnn.dequantize nodes. I took a look at the tflite frontend and for FakeQuant, it does seem to be converted to a bunch of ops as seen here
I used the TFLiteConverter as my model was a v1 frozen graph.
When we use the TFLite converter, we get an actual Quantize and Dequantize nodes, and that gets imported into relay as the qnn.quantize and qnn.dequantize nodes. This is needed as TVM can then identify the quantize and dequantize ops directly and use them to do pattern matching (when running the FQ2I pass) for replacing the original nn.conv2d that works in floating point to qnn.conv2d that works on fixed points.
Is it possible for you to use the TFLite converter, as that might make things easier. If not, you might have to write some pattern matching pass to identify the group of ops that correspond to quantize/dequantize and replace it with an actual qnn.quantize/qnn.dequantize in Relay, before applying the FQ2I pass.