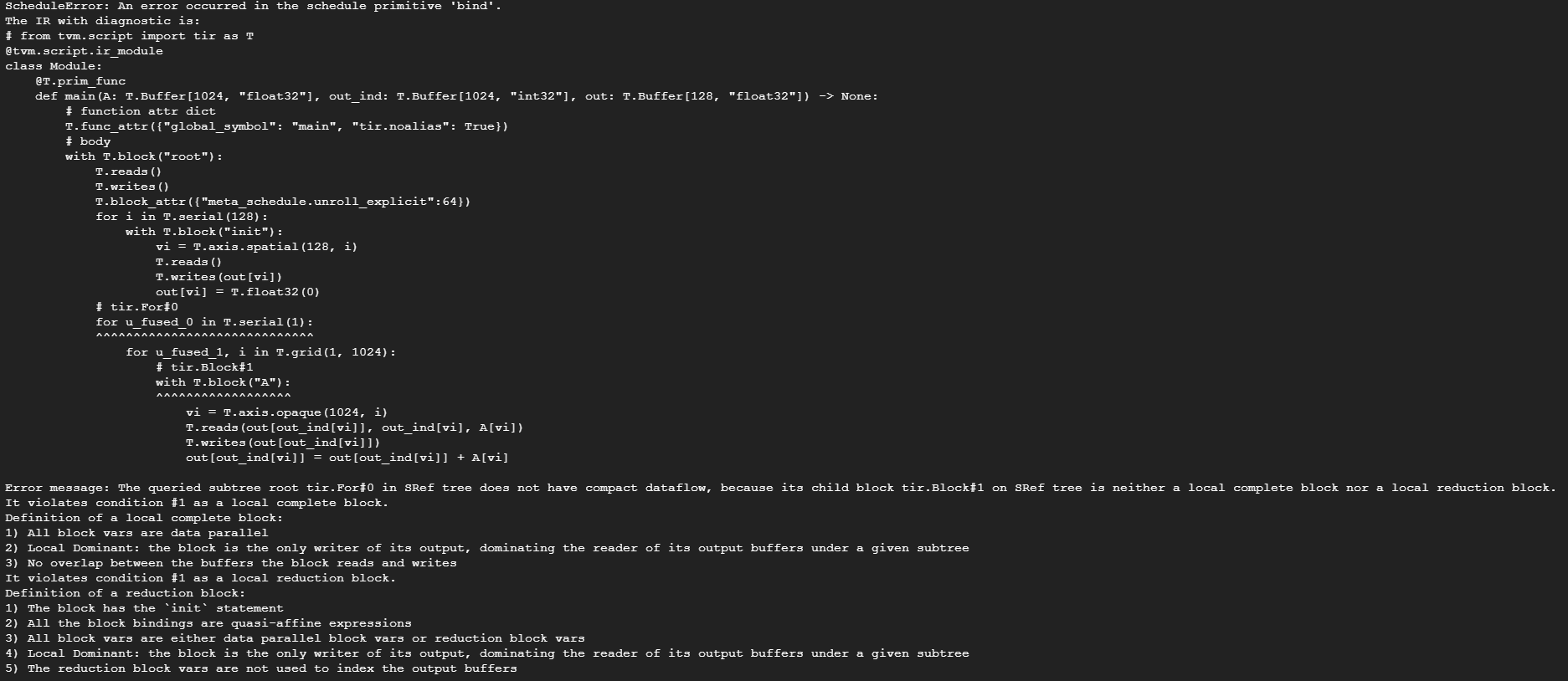
I want to create a new reduction operation. However, the window size is decided by user input. For example, we want to reduce a 1-dimensional vector A to a smaller size. Instead of summing up every fixed number of element, users input another vector out_ind, which indicates the output indices. Here is a pesudo-code:
for i in range(M):
out[out_ind[i]] += A[i]
I create an IRModule and try to compile it on Nvidia GPU, but it turns out a wrong result.
@tvm.script.ir_module
class MyModule:
@T.prim_func
def main(A: T.Buffer[(1024,), "float32"],
out_ind: T.Buffer[(1024,), "int32"],
out: T.Buffer[(128,), "float32"]) -> None:
T.func_attr({"global_symbol": "main", "tir.noalias": True})
for i in T.grid(1024):
with T.block("A"):
vi = T.axis.remap("S", [i])
with T.init():
out[out_ind[vi]] = 0.0
out[out_ind[vi]] += A[vi]
Does any have any idea about this? Thanks.