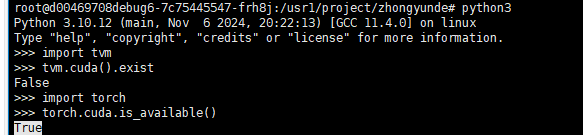
base on https://github.com/microsoft/nnfusion/blob/osdi22_artifact/artifacts/get_started_tutorial/README_GET_STARTED.md, there is a code developed for cuda, but I don’t care the performance, so I want it can be run on cpu, Is there a way to quickly migrate the GPU code to the CPU?
When I execute python test_op_mp.py --code_dir tmp_dir/ --smem_tiling --reg_tiling --op matmul_expr --shape 4096 4096 4096 on my aarch64 machine(10), and the first error seems related to line 196
165 def get_tvm_source(rprog, arch, policy, dtype):
166 expr = rprog.Expression()
167 # shape = rprog.Dimensions()
168 shape = args.shape
169 expr_out = expr(shape, dtype, False)
170 in_tensors, out_tensors = expr_out[0], expr_out[1]
171 out_tensor = out_tensors[0]
172 if args.fuse or args.schedule_fuse:
173 pad = get_pad(rprog, out_tensor)
174 print("pad: ", pad)
175 expr_out = expr(shape, dtype, False, pad)
176 in_tensors, out_tensors = expr_out[0], expr_out[1]
177 ori_in = []
178 pad_in = []
179 for ins in in_tensors:
180 if '_pad' in ins.name:
181 pad_in.append(ins)
182 else:
183 ori_in.append(ins)
184 out_tensor = out_tensors[0]
185 write_tensor = out_tensors[-1]
186 s = te.create_schedule(write_tensor.op)
187 align_info = policy.get_align_info_fuse(rprog, arch, args.smem_tiling, args.reg_tiling, target_stage=out_tensor.name, write_stage=write_tensor.name, st_align=args.st_align)
188 cgen = CodeGeneratorR()
189 cgen.rewrite_schedule_fuse(s, rprog, args.smem_tiling, args.reg_tiling, pad_in, out_tensors[:-1], write_tensor, target_stage=out_tensor.name, write_stage=write_tensor.name, align_info=align_info, bank_size=arch.smem_bank_size)
190 func = tvm.build(s, ori_in + out_tensors, "cuda")
191 else:
192 s = te.create_schedule(out_tensor.op)
193 align_info = policy.get_align_info(rprog, arch, args.smem_tiling, args.reg_tiling, target_stage=out_tensor.name, st_align=args.st_align)
194 cgen = CodeGeneratorR()
195 cgen.rewrite_schedule(s, rprog, args.smem_tiling, args.reg_tiling, target_stage=out_tensor.name, align_info=align_info, bank_size=arch.smem_bank_size)
196 func = tvm.build(s, in_tensors + out_tensors, 'cuda')
197 return func.imported_modules[0].get_source()
- the detail error info
File "/home/zhongyunde/source/osdi22_artifact/artifacts/roller/test_op_mp.py", line 196, in get_tvm_source
rt_mod_host = _driver_ffi.tir_to_runtime(annotated_mods, target_host)
rt_mod_host = _driver_ffi.tir_to_runtime(annotated_mods, target_host)
File "/home/zhongyunde/source/venv/lib/python3.10/site-packages/tvm/_ffi/_ctypes/packed_func.py", line 237, in __call__
File "/home/zhongyunde/source/venv/lib/python3.10/site-packages/tvm/_ffi/_ctypes/packed_func.py", line 237, in __call__
func = tvm.build(s, in_tensors + out_tensors, 'cuda')
func = tvm.build(s, in_tensors + out_tensors, 'cuda')
File "/home/zhongyunde/source/venv/lib/python3.10/site-packages/tvm/driver/build_module.py", line 281, in build
File "/home/zhongyunde/source/venv/lib/python3.10/site-packages/tvm/driver/build_module.py", line 281, in build
raise get_last_ffi_error()
rt_mod_host = _driver_ffi.tir_to_runtime(annotated_mods, target_host)
tvm._ffi.base.TVMError: Traceback (most recent call last):
4: TVMFuncCall
3: tvm::runtime::PackedFuncObj::Extractor<tvm::runtime::PackedFuncSubObj<tvm::runtime::TypedPackedFunc<tvm::runtime::Module (tvm::runtime::Map<tvm::Target, tvm::IRModule, void, void> const&, tvm::Target)>::AssignTypedLambda<tvm::__mk_TVM22::{lambda(tvm::runtime::Map<tvm::Target, tvm::IRModule, void, void> const&, tvm::Target)#1}>(tvm::__mk_TVM22::{lambda(tvm::runtime::Map<tvm::Target, tvm::IRModule, void, void> const&, tvm::Target)#1}, std::string)::{lambda(tvm::runtime::TVMArgs const&, tvm::runtime::TVMRetValue*)#1}> >::Call(tvm::runtime::PackedFuncObj const*, tvm::__mk_TVM22::{lambda(tvm::runtime::Map<tvm::Target, tvm::IRModule, void, void> const&, tvm::Target)#1}, tvm::runtime::TVMArgs const&)
2: tvm::TIRToRuntime(tvm::runtime::Map<tvm::Target, tvm::IRModule, void, void> const&, tvm::Target const&)
1: tvm::codegen::Build(tvm::IRModule, tvm::Target)
0: _ZN3tvm7runtime6deta
File "/workspace/tvm/src/target/codegen.cc", line 57
TVMError:
---------------------------------------------------------------
An error occurred during the execution of TVM.
For more information, please see: https://tvm.apache.org/docs/errors.html
---------------------------------------------------------------
Check failed: (bf != nullptr) is false: target.build.cuda is not enabled raise get_last_ffi_error()