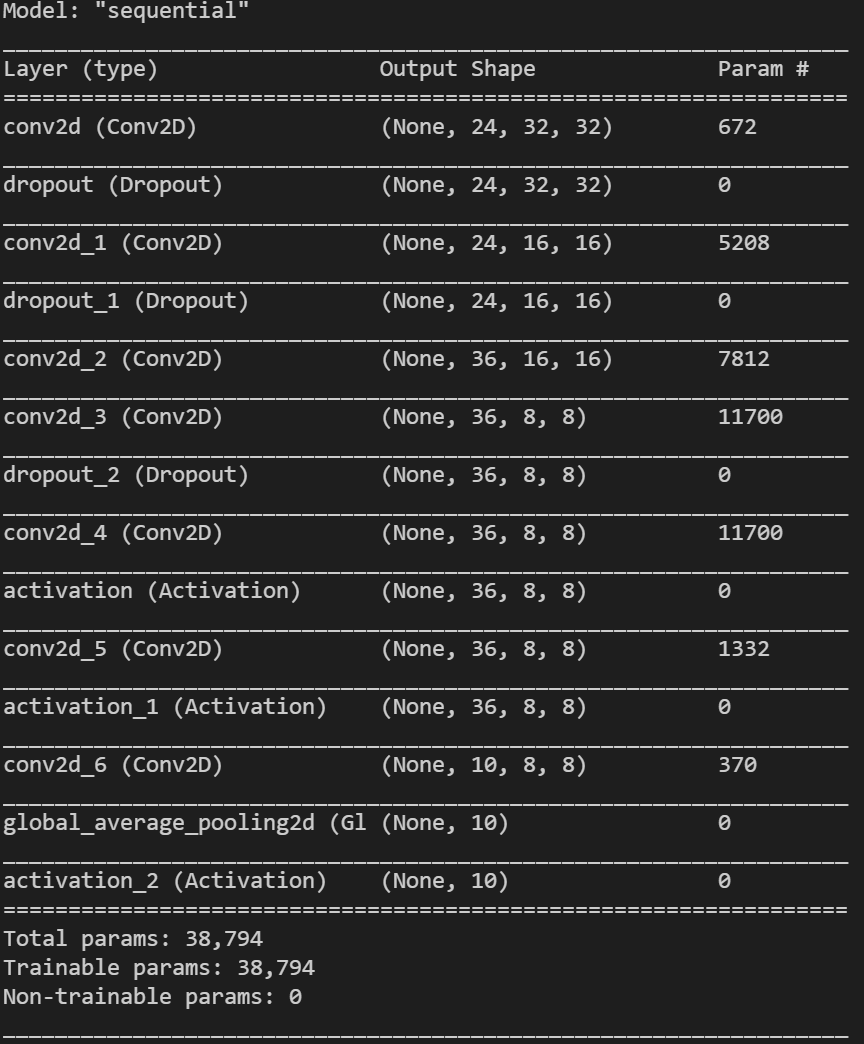
I am using microTVM to deploy a customized VGG model to STM32F746g_disco, this model uses tflite for int8 quantization. The model structure is as follows:
After generated_project.build(), microTVM will generate the default_lib1.c file in the generated-project/model/codegen/host/src directory, you can find that TVMBackendAllocWorkspace alloc for a large memory(about 110KB) in the runtime phase, and the memory will only be released after inference is over. I have the following questions:
The tflite model size is about 52KB, why mictoTVM need so large memory usage(about 110KB) for intermediate variable?
Which part of the IR will determine the memory usage of the TVMBackendAllocWorkspace function? I want to reduce its memory usage.
What are the factors affect the size of memory allocation? Does the current microTVM consider memory reuse between operators?
Can Unified Static Memory Planner(RFC 0009) reduce the runtime memory usage?
Finally, TVM seems to pay more attention to inference acceleration, and the optimization for memory is not perfect(but it could). I do hope microTVM can deploy models with better performence on bare-metal device.
When you say the model size, I presume this is mostly the size params of the model would take rather than the intermediary tensors. If its the case, it might be worth taking a look what is the expectation of the space required by intermediary tensors.
The tir.allocate nodes are what get translated down to TVMBackendAllocWorkspace. The best place to check would be TIR PrimFuncs as produced by the TE compiler in the codegen. I believe you could obtain these out ExecutorFactory that is produced by relay.build(..).
TVM does consider this. However, it is done at two phases independently – once inside a (fused) operator and in-between operators. Which executor are you using ?
This is one of the goals – the primary goal being USMP will plan across whole model (intra- and inter- operator memory usage based on liveness) as opposed to due this in two stages as mentioned before. However, if there are sub-optimal schedules (in terms of memory) being used we need to improve them independently as mentioned above.