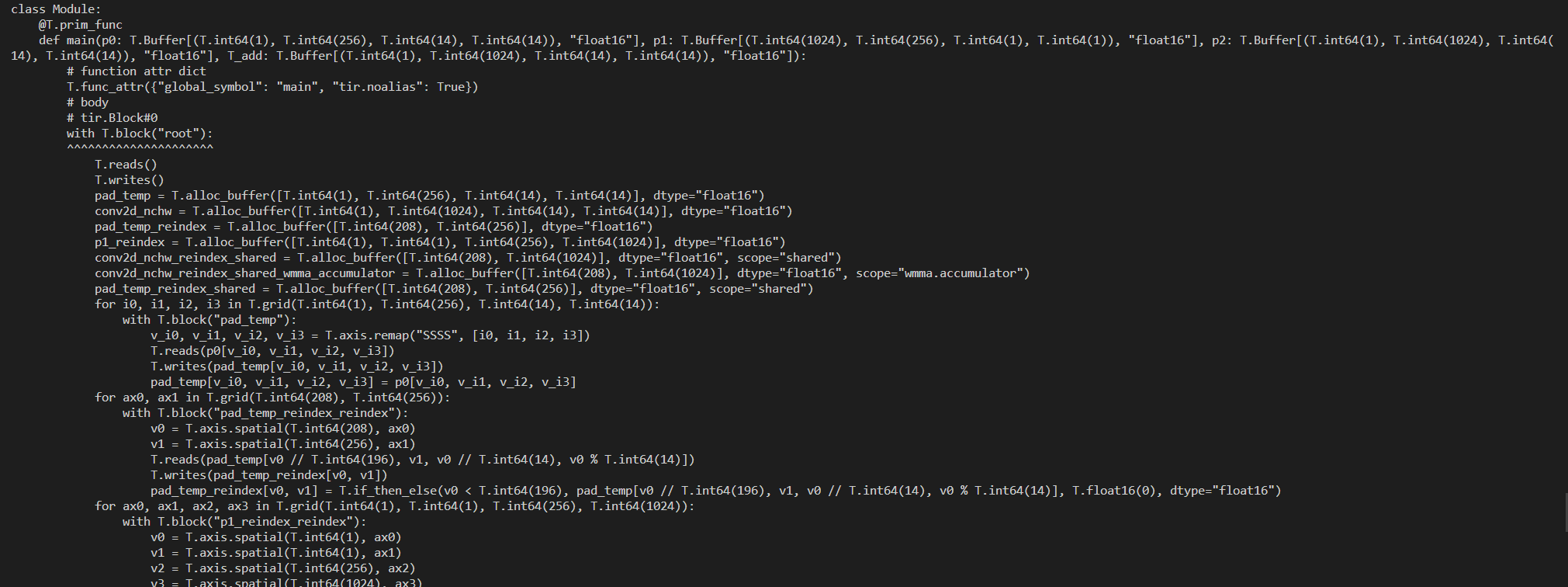
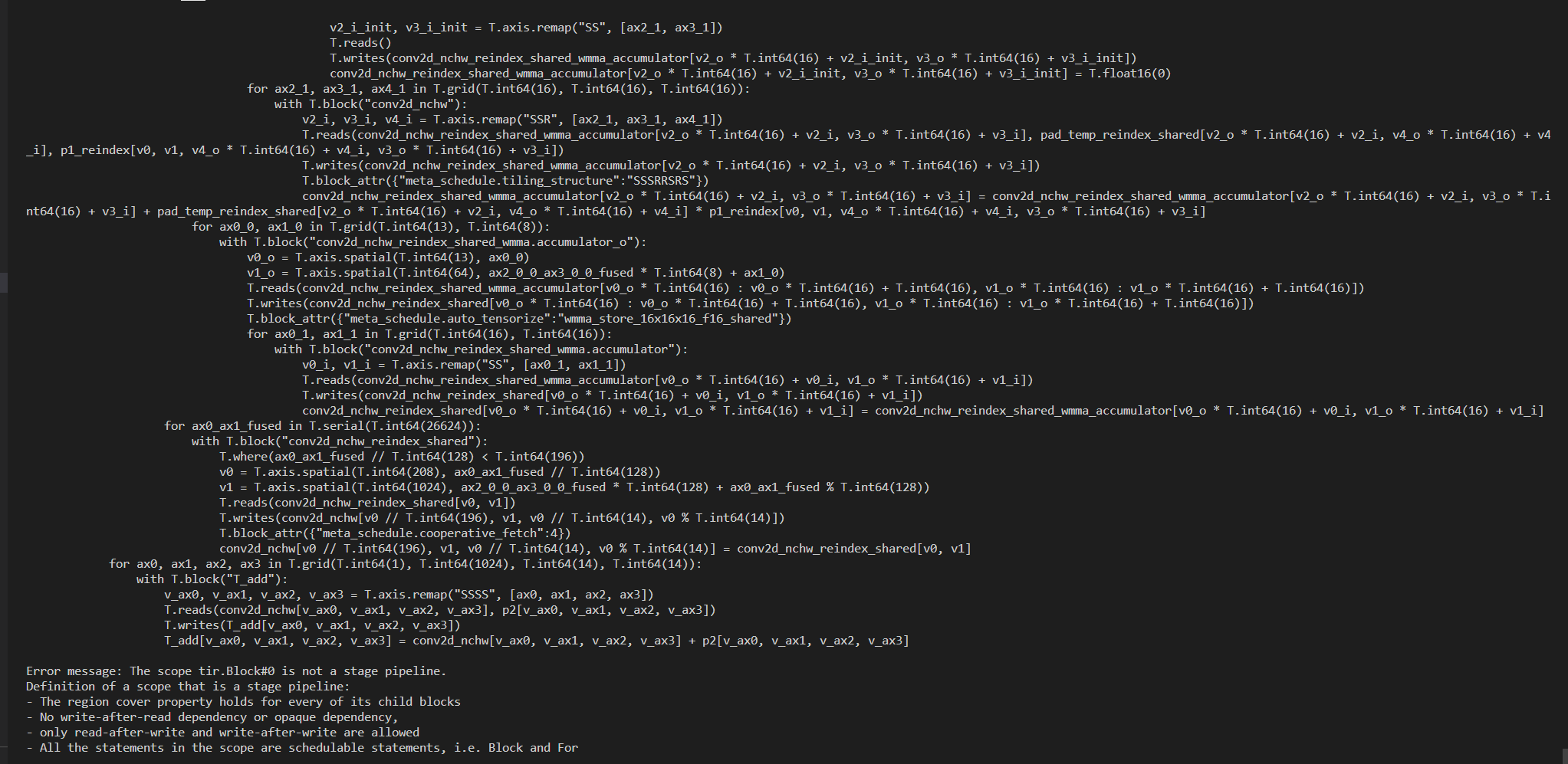
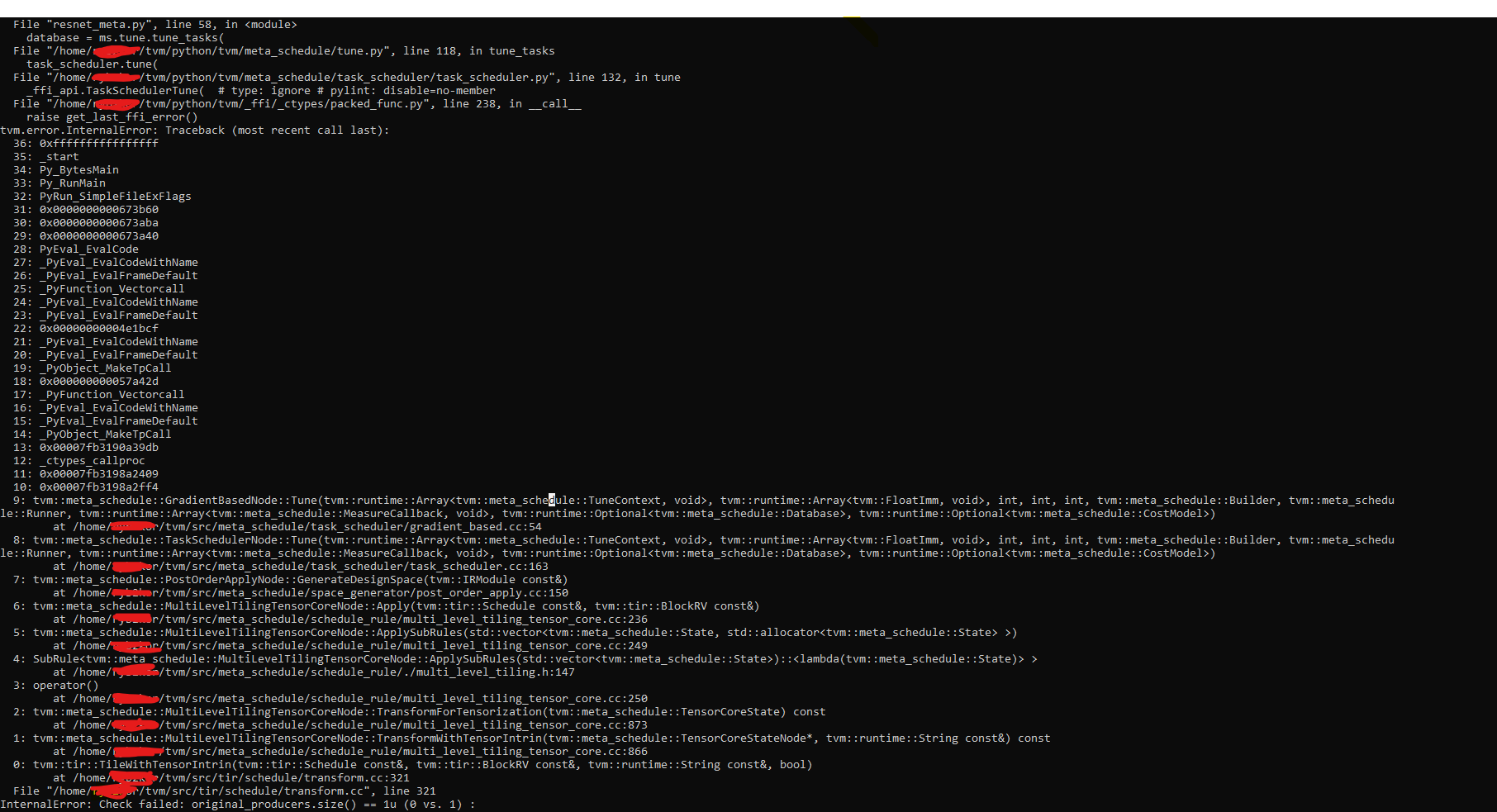
I try to use tensorcore to tune a network. To use tensorcore, I set datatype as “float16”, and I find this error. Besides when I set datatype as “float32”, it runs normally.
Traceback (most recent call last): File “resnet_meta.py”, line 58, in database = ms.tune.tune_tasks( File “/home/pan/tvm/python/tvm/meta_schedule/tune.py”, line 117, in tune_tasks task_scheduler.tune( File “/home/pan/tvm/python/tvm/meta_schedule/task_scheduler/task_scheduler.py”, line 132, in tune _ffi_api.TaskSchedulerTune( # type: ignore # pylint: disable=no-member File “/home/pan/tvm/python/tvm/_ffi/_ctypes/packed_func.py”, line 237, in call raise get_last_ffi_error() tvm.tir.schedule.schedule.ScheduleError: Traceback (most recent call last):
ScheduleError: An error occurred in the schedule primitive ‘compute-at’ … Error message: The scope tir.Block#0 is not a stage pipeline.
I imitate the testing file to write my resnet metaschedule tune file, here is the code:
mod, params = testing.resnet.get_workload( num_layers=50, batch_size=batch_size, image_shape=image_shape, dtype=“float16” )
tune_tasks = ms.relay_integration.extract_tasks(mod, tgt, params)
tasks, task_weights = ms.relay_integration.extracted_tasks_to_tune_contexts( extracted_tasks=tune_tasks, work_dir=work_dir, space=ms.space_generator.PostOrderApply( sch_rules=“cuda-tensorcore”, postprocs=“cuda-tensorcore”, mutator_probs=“cuda-tensorcore”))
database = ms.tune.tune_tasks( tasks=tasks, task_weights=task_weights, work_dir=work_dir, max_trials_per_task=4, max_trials_global=150, )
Please help me check out why this error happens
Many thanks.