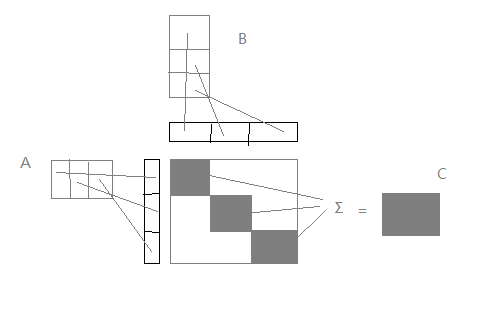
I’m trying to tile matrix in different direction to let them fit the buffer size of blocks in GPU for matrix multiplication. I follow the reduction tutorial and the other type of tiling works well, but i found that we can’t tile matrix throw reduce axis, it won’t work because TVM doesn’t support blocks synchronization.
 I got these three ways but none of them is easy for me.
1.Add blocks synchronization feature but it seems like too complicated and it will spend lot of time.
2.writting this tiling method directly with cuda but its seems like difficult to combine it with TVM.
3.I tried to reshape these two matrix to tile them in other axis like this
I got these three ways but none of them is easy for me.
1.Add blocks synchronization feature but it seems like too complicated and it will spend lot of time.
2.writting this tiling method directly with cuda but its seems like difficult to combine it with TVM.
3.I tried to reshape these two matrix to tile them in other axis like this