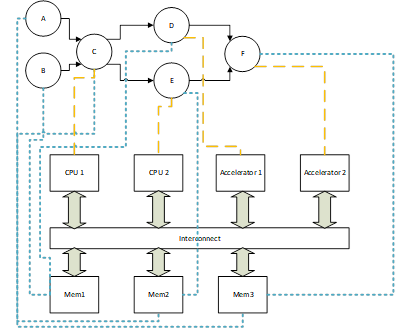
Is there a language construct to explicitly map operators to compute blocks of heterogeneous architectures (as shown in the Figure and code example below)? The memory mapping shown in blue could be done with .scope ?
However, I’m unaware of a mechanism to map compute to individual hardware blocks at TensorIR or TE level, as shown by the yellow lines.
import tvm
from tvm import te
n = te.var("n")
m = te.var("m")
A = te.placeholder((m, n), name="A")
B = te.placeholder((m, n), name="B")
# These are toy examples. Imagine the computes as pipelined and running for \approx 1 ms
C = te.compute((m, n), lambda i, j: A[i, j] * B[i, j], name="C")
D = te.compute((m, n), lambda i, j: C[i, j] + 1, name="D")
E = te.compute((m, n), lambda i, j: te.exp(C[i, j]), name="E")
F = te.compute((m, n), lambda i, j: D[i, j] + E[i, j], name="F")
s = te.create_schedule([F.op])
# BEGIN pseudo code
# Is there a way to map each operator a specific HW?
s[C].map_to = cpu1
s[D].map_to = accelerator1
s[E].map_to = cpu2
s[F].map_to = accelerator2
# I know that VTA uses *.pragma* for a similar issue. But doesn't this typical case
# deserve a language construct for itself?
s[A].set_scope(Mem2)
s[B].set_scope(Mem1)
s[C].set_scope(Mem3)
s[D].set_scope(Mem1)
s[E].set_scope(Mem2)
s[F].set_scope(Mem3)
# END pseudo code
+1 for this feature.
I think you could (ab)use tensorize to get such a thing to work (do a specific tensorization for a specific subtarget).
If you’d like to “automate” the allocation process you can write a relay strategy to lower high-level graphs to allocated parts of your hardware with tensorization.
But to be honest I’d rather have an explicit language construct for this as well, rather than putting everything in a specific not-so-explicit tensorize block .
Also wondering how this relates to the target field that is used in TVM’s backend.
If you would do it through tensorization I think that part remains unused.
If anyone has more experience with this or better suggestions, i’d be happy to hear them as well!
Thank you for bringing such a great idea. As far as I know, TE does not support it and TenorIR also lacks this part of consideration. Tensorize is one path to it (especially for those accelerators instructions) but I agree we need to add “native” support.
Decoupled primitives are one of the features of TensorIR, which means we can add primitives easily in TensorIR for our purpose (like heterogeneous systems support). On the other side, pragma/annotation-liked primitives are one possible way. I don’t know what’s your meaning by “But doesn’t this typical case deserve a language construct for itself?”. Could you please show one example of lowered code?
I think this is somewhat similar to memory scopes being implemented by @csullivan. There is definitely additional work to be done to handle memory planning in a memory scope world. I think some of that falls under [µTVM] microTVM M2 Roadmap.
There are a couple of points to this proposal I’d like to highlight to drive the discussion:
P1. “map to hardware” is currently ambiguous in TVM. Specifically, the “hardware” part. Ostensibly, at runtime, this means “running a computation on a particular DLDevice.” However, getting from the compiler to the runtime is tricky because:
the compiler’s concept of a “device type” is merely the “type” field of DLDevice
in particular, BYOC devices are all considered “ext_dev.” For BYOC device in which the underlying hardware is identical but they are programmed differently (e.g. imagine several small FPGA instances), this is very limiting. There is no way to express “accelerator type.”
even for e.g. CPU co-processors, there isn’t a good way to identify them outside of an integer index. How does a programmer know that DLDevice(kDLCPU, 1) means the DSP core? Do they have to actually maintain some enumeration in both Python (e.g. to drive TVM) and C (e.g. at runtime)? This seems terrible.
We currently conflate the concept of “relay backend” with both the concepts of “accelerator type” (e.g. how is this accelerator programmed? is it used for e.g. convolution or pooling?) and “code generator” (e.g. generating C code implies it will run on target_host–to do something different, subclass CodegenC and name it differently).
In general, in the TVM C++ runtime, this is less of a problem because much of the “device programming” is pushed to “load time,” which in the C++ runtime case, is actually typically done as late as possible by Module#GetFunction. This clashes with what you’d expect in microTVM: pushing as much of the programming into the C compiler as possible. In general, the TVM compiler now is somewhat unaware of its runtime environment.
P2. There are a couple of different ways to interpret set_scope:
Inputs and outputs must be in this memory region
Only outputs need to be in this memory region
P3. When copying between memory scopes, there is often:
synchronous copy, handled by CPU
async copy, handled by e.g. DMA, accelerator
It’d be good to discuss P2 & P3 a bit further to better understand the impact on the runtime and memory planner.
Towards solving P1
It seems like we could help solve this problem by motivating a new e.g. target_arch concept in the compiler, which effectively is device_type but with additional provision for BYOC accelerators and multi-core SoC. target_arch could be things like:
target_host_cpu
dsp_cpu
cuda
fpga_conv2d
accelerator (maybe there is just one of these in a system)
target_arch should be tied to both a codegen and a “load” process, but could largely be a platform-specific string. It should have meaning to the end user e.g. “dsp_cpu” should be a concrete concept to them.
 .
Also wondering how this relates to the target field that is used in TVM’s backend.
If you would do it through tensorization I think that part remains unused.
.
Also wondering how this relates to the target field that is used in TVM’s backend.
If you would do it through tensorization I think that part remains unused.