Hi.
I’m measuring resnet-50 inference time.
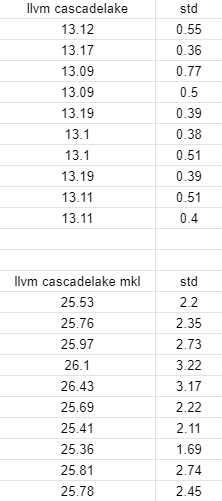
batch size=1, target = “llvm -mcpu=cascadelake”
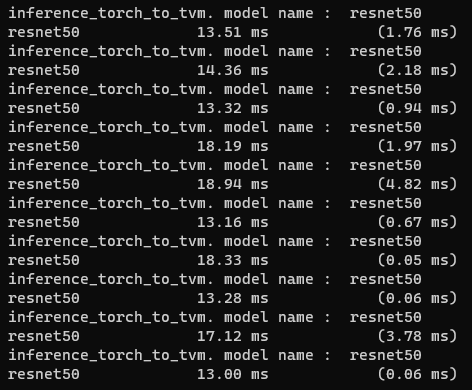
This is result…
Why inference time fluctuate? and How can resolve this problem?
Hi.
I’m measuring resnet-50 inference time.
batch size=1, target = “llvm -mcpu=cascadelake”
This is result…
Why inference time fluctuate? and How can resolve this problem?
Are you using time_evaluator? It will run the model multiple times to average out performance results. But there really isn’t anything you can do to avoid these fluctuations when running on the cpu. The OS and other processes are running and may interfere with your running model.
Oh you are right. At that time, i run another program. So fluctuation occurs.
i have a question about mkl, mkl-dnn
When i turn on the mkl(mkldnn), fluctuation occurs more than before and inference time is more slow.
can i get some hints about this?
Not sure if this applies to you but I have found that there are several system-level factors that can affect your results. Some observations that I can make:
TVM_NUM_THREADS
Of course it all depends on your system and your performance target so as they say your milage may vary.
Hope the above helps!
Thanks you for replying!
using mkl_verbose=1, i found that tvm_num_threads do not affect threads used by mkl.
so i used mkl_num_threads and resolved problems(fluctuation, slow)
with and without -libs=mkl, the inference time is measured approximately the same.
While searching for the reason, I found out that tvm uses mkl to optimize the only dense layer. I also found that auto-tvm can tune the dense layer.
As a result, if not use mkl, the tvm default tuning option applies to all layers. If use it, mkl would be applied a dense layer. is this right?
If I’m right, auto-tvm (default) auto-tvm + mkl(only dense)
these two cases show similar performance, and can i say that the schedule primitives of tvm show as much performance as mkl?