model: https://github.com/onnx/models/blob/main/vision/classification/resnet/model/resnet50-v1-7.onnx model size: 98M
Compiler:
import numpy as np
from tvm import relay
import tvm
from tvm.contrib import cc
import onnx
model_file = "resnet50-v1-7.onnx"
shape_dict = {"data": (1, 3, 224, 224)}
model = onnx.load(model_file)
mod, params = relay.frontend.from_onnx(model, shape_dict)
target = tvm.target.Target("llvm -mattr=+neon -mtriple=aarch64-oe-linux -mcpu=cortex-a76")
with tvm.transform.PassContext(opt_level=3):
lib = relay.build(mod, target=target, params=params)
lib.export_library("deploy_lib_resnet50.so",
cc.cross_compiler("aarch64-oe-linux-g++",
["--sysroot=/usr/local/oecore-x86_64/sysroots/aarch64-oe-linux"]))
deploy_lib_resnet50.so size: 228M
Next, I deployed and obtained the memory usage at runtime through showmap:
It can be seen that about 700M of memory is used.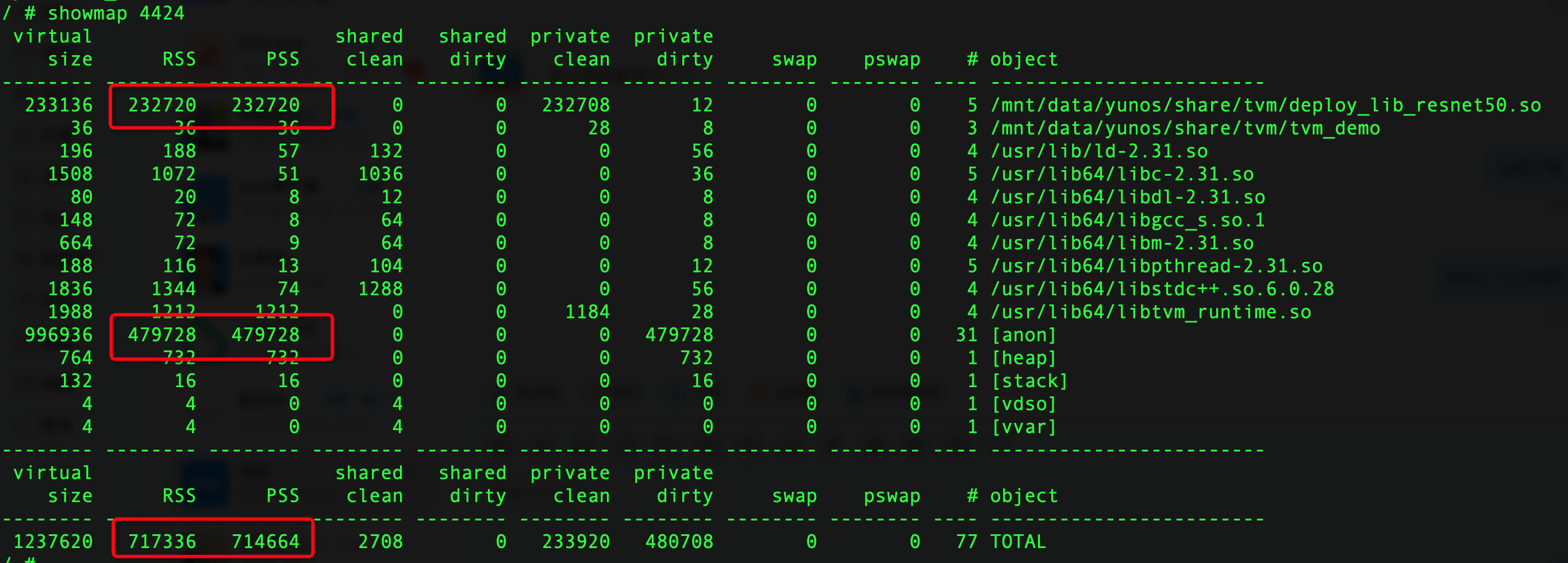
There are 2 questions:
-
Why is the size of the compiled deploy_lib twice that of the model?
-
When deploying, it uses 3 times the size of deploy_lib. Why is this?
The final memory usage is almost 6 times more than the model.