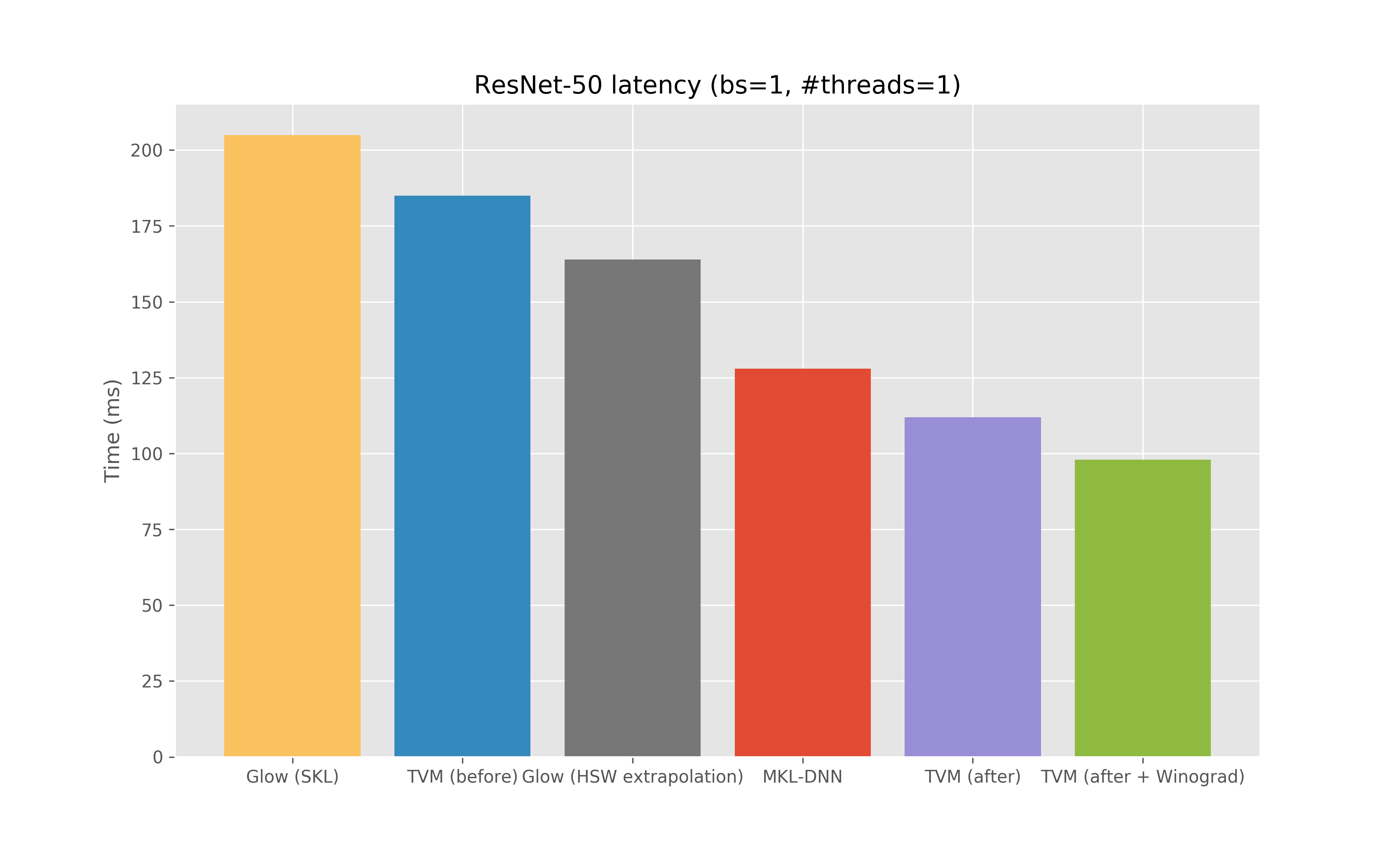
Just a FYI for folks, we’ve been working a bit on the CPU backend for CNNs lately, and I think we’ve got some pretty solid improvements, compared to our previous baselines. This leverages a bunch of code from the current master repo and others, the key modifications have been:
a) implementing various ops in NCHWc format, so we can use it for the entire graph without unnecessary __layout_transform__ ops being inserted in the layout transform passes,
b) AutoTVM’ing the NCHWc implementation
c) Adding a fast NCHWc implementation of F(4x4, 3x3) convolutions.
We end up getting about a 25% improvement over MKL-DNN (via MXNet) in the single-threaded, batch-size 1 case for ResNet-50 on a GCE Intel Skylake, which AFAIK would make TVM the current state of the art on that platform? Note there’s zero platform-specific code here in the implementation (no use of tensorize or other intrinsics, just autotvm on the pure schedules).
We’ll work on preparing some PRs, unless other folks have objections. I think it’d be useful to keep supporting both NCHW and NCHWc layout for our major CPU backends. The main parts if you’re curious are at:
According to my experience, pure NCHWc implemented in the @masahi mentioned, which will behave better than than spatial pack whenthe input data size is large (For example, Resnet50’s first conv2d workload) . But NCHWc schedule will not behave better performance in the small input data size. I am also preparing related blog compared between NCHWc with spatial pack on ARM CPU. Wish @ajtulloch could introduce more information about spatial_pack_NCHWc. According to my test, which is not better than pure NCHWc in the large input data size on ARM CPU.
One recommend conv2d: input tensor, [1, 32, 256, 512], Filter: [4, 32, 1, 1], strides [1, 1], padding [0, 0].
The input tensor data is 1x32x256x512*sizeof(float32) = 16MB. This is one of conv2d workload in our model.
@FrozenGene yeah, I’m not claiming this is the best for everything, and this hasn’t been evaluated substantially on ARM. What workload are you interested in? If filter = [4, 32, 1, 1], then yeah I don’t think the implementation in my branch is very good, since you don’t have sufficient parallelism over output channels CO = 4.
I am interested in the large data size. Like I mentioned before: input tensor, [1, 32, 256, 512], Filter: [4, 32, 1, 1]. If we could not erase the data transformation stage like pure NCHWc implemented, we will occupy much time in the data_vec stage in the spatial pack (or your spatial_pack_NCHWc). I have tested it on ARM, the data transformation time will be the same as convolution compute time. So on my ARM CPU A53 1.5GHz, spatial pack’s convolution will be 89.7075ms, but pure NCHWc only 22.9162ms.
@ajtulloch auto tuning compute_at is an interesting idea, never thought about that.
Looking at your code, I’d imagine that for some workload, all stages in winograd (U, V, M, Y, last) will be fused, while for others fusion behavior can be quite different. I’m curious to see generated winograd schedules. Looking forward to testing on my end!
For large data size, one of the possible strategy is to do per segment spatial pack, i.e. you try to spatially partition your input data, and within each small block, run a spatial pack then conv2d(this will likely keep spatial pack data on cache) between packing and execution
What is the base frequency of your processor? We measured single-thread performance on Amazon EC2 C5 (Intel Skylake running at 3.0GHz), TVM with necessary layout transformation gets 65.09 ms, while the latest MXNet with MKL-DNN gets 50.87 ms.
@ajtulloch To eliminate layout_transform op, did you keep all tile_ic and tile_oc consistent, just like current _fall_back_schedule? If that’s the case, graph tuner might further improve e2e performance by smartly balancing tradeoffs between layout transform and fast kernels.
Also did you use mxnet master branch to do MKL_DNN testing? Recently intel team introduces fusion into mxnet-mkldnn and gets performance boost.
Could you explain more? what is the meaning of per segment? It seems that very similar NCHWc. But I haven’t understood spatially partition the input data
In before, you spatial pack everything before you run conv2d. This causes problem if input is very large, and the intermediate data do not fit into cache. What you can do is to divide your input by height and width into smaller region, and run spatial pack on each of the region sequentially
@masahi The generate schedules were surprising, in all cases V was fully materialized which was a bit weird, I suspect that could be improved by maybe a better loop ordering (which I didn’t really tune here). Another thing to try was the minimal methods (e.g. https://github.com/ajtulloch/tvm/blob/4cebfb323b72dfc7d0f4d5573ea28d87dd99ad24/tensorize/simple_winograd.py#L269-L345) which might allow something like F(6x6, 3x3) to be faster in this impl (4x4 seems to be almost always faster here), but the massive amount of unrolling required is pretty annoying - perhaps an explicit Mul + Transpose + Mul would be better and only need alpha^2 unrolling instead of alpha^4 unrolling.
Thanks @merrymercy, I’ll check that out. I didn’t notice any surprises going from AutoTVM to e2e, but I’ll rebase, perhaps I might see faster convergence or similar.
I noticed some interesting design questions during this work, around cases where modifying autotvm knobs can change the cache footprint of the algorithm. For example, tuning the compute_at location, or precomputing winograd transforms.
If during AutoTVM tuning, we allow a program to fully occupy the cache, and don’t flush cache between iterations, we can (naturally) seek solutions that fully occupy the cache. This has problems then in e2e testing, since arrays that we assume exist in cache (ie. weights) are evicted during e2e runs, which leads to lower performance (one case is e.g. F(6x6, 3x3) winograd, where our weight footprint increases by a factor of (8 / 3)^2.
I can think of a few candidate approaches to work around this, such as:
During AutoTVM profiling, evict everything from cache between iterations, to get a pessimistic lower bound
During AutoTVM profiling, evict just the activations from cache between iterations, to get a perhaps less pessimistic bound
Enable Intel CAT or similar to restrict the amount of cache available during AutoTVM profiling.
Examine the schedule to explicitly compute the amount of cache traffic generated (I believe with some assumptions you can do this analytically), and use this as part of an overall cost metric.
Perhaps with the graph tuning stuff, use a full e2e evaluation process to select between a restricted subset of algorithms (with different cache effects), to avoid being too greedy too early at the local stage?
Curious what you folks think, or if you’ve run into similar problems before?
@yidawang this is a 2GHz base clock GCE Skylake, synthetic GEMM benchmarks (e.g. https://github.com/Mysticial/Flops) hit about 118GFLOP/s. This was using the mxnet-mkl=1.3.0 package from PyPI. I’ll re-run with the master MXNet version.
@kevinthesun this was with mxnet-mkl=1.3.0 from PyPI, so I haven’t rebuilt from master. Good idea to try, thanks. WRT layout_transform, I did indeed fix tile_ic/tile_oc at the native vector width. graph tuner would definitely help, that’s on our list to try, thanks for that work. I think there’s also an interesting opportunity (as I mentioned above in my reply to @merrymercy) to leverage graph tuner to select between different algorithm instantiations with different cache behaviour, to better model the e2e occupancy of weights, etc (for example, while we hit ~200GFLOP/s for the Winograd kernel on e.g. a 512 -> 512 3x3 conv vs ~105GFLOP/s for the direct kernel, it turns out to be faster to use the direct kernel e2e because of the much larger cost of loading the pre-transformed Winograd weights).
We have run into similar problems when trying winograd on some arm cpus.
We also suspected the reason is the increase of weight tensor.
I think (1 or 2) + 5 can be the solution.
We can evaluate 1 and 2 and pick the better one to fix our profiling.
Something like 5 is orthogonal to 1or 2. We can always add that as a final pass.