Motivation
In its current state TVM compilation flow produces two (or optionally three) artifacts:
- The library containing the operators
- The parameters of the networks (i.e., the weights of the model). This has been made optional with the
--link-paramsoption to the host target. - A json file describing the control flow of the network. i.e., which operators should be run.
Generally speaking, the TVM runtime consists in an interpreter reading the json file (3) and - optionally - the weights (2) and calling the operators contained into the library (1). This mechanism is described in the following picture:
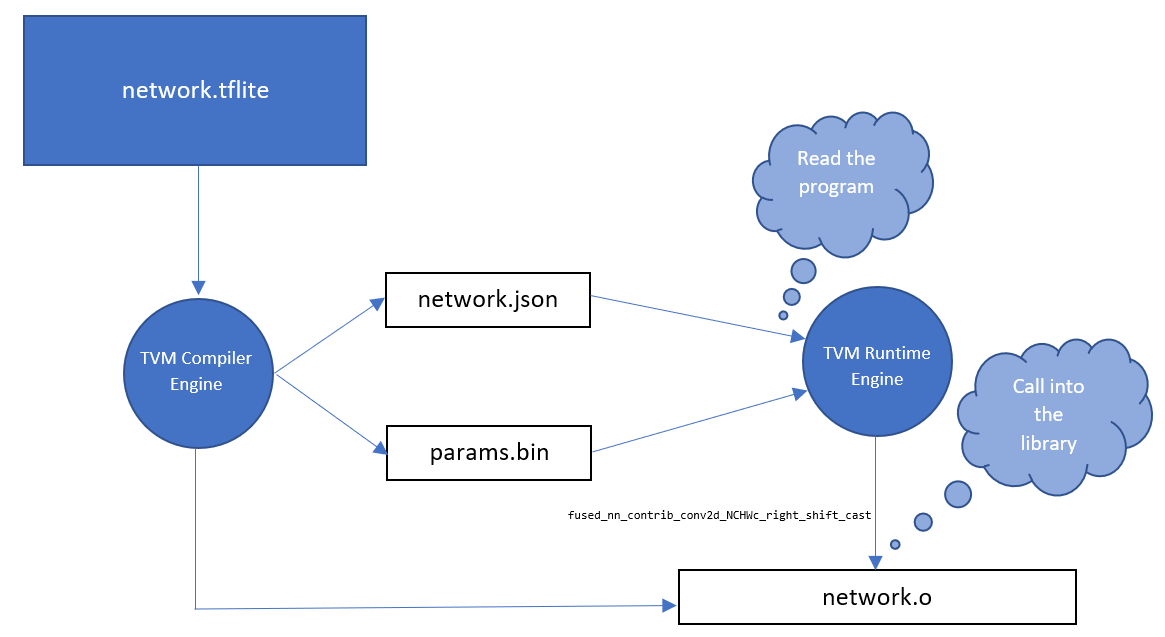
While the params.bin is optional (i.e., we can omit it if we provide a --link-params flag to the compilation, see this RFC), the json file network.json is mandatory.
To be clear, there is actually no flow that allows the user to not provide the json file to the runtime.
This is a problem for two main reasons:
- This workflow is very hard to implement on a micro-controller, since memory is usually a costly resource in embedded environments, and the json file is usually quite large.
- We have a split memory allocation in the current TVM stack, where inter-operator memory is managed at json/relay level while the intra-operator memory is managed at TIR level
We at Arm are working on an AOT flow to get rid of the Json, and to transform the above graph into the following single-artifact scenario:
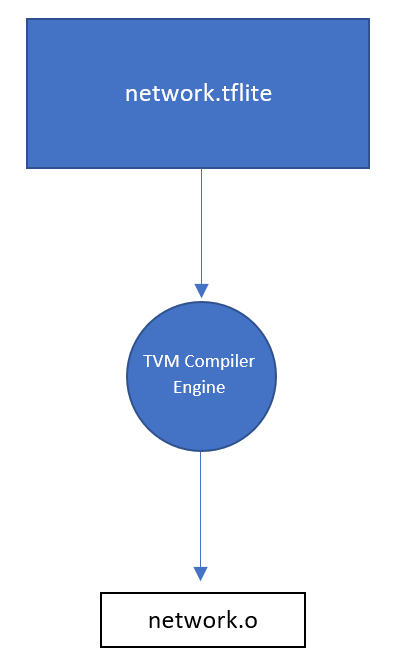
The user can optionally specify the name of the network, so that we can have a network_resnet.o, network_mobilenet.o, etc… For this RFC we will refer to a generic network.o (as shown in the picture).
The idea in the above image is that the network.o will expose a runner function which will take care of calling the different operators in the same library. We will temporarily call this function run_func, but naming is something that we will need to define.
The aim of this RFC is to provide a source of discussion on different topics that can help us through the development of this feature. The main topics of interests are
- Code generation (i.e.,
IRModule+runtime::modulegeneration) - Runtime API
Code generation
The aim of code generation is to go from a Relay graph to a runtime::module containing the control execution of the graph. We split this process in two different parts:
- runtime::Module generation
runtime::Modulebundling
TIR code generation
In recent times TIR has been augmented with runtime functionalities (e.g., the possibility to return a value ) which makes it ready to handle runtime code like creating NDArrays, NDShapes, calling functions, returning values, etc…
This solution provides different benefits:
- We would be reusing a lot of TIR functionalities (less code duplication)
- We can set the foundations to implement a global memory planner, thus reducing the memory footprint of the network (which is quite valuable for microcontrollers)
The signature of the run_func generated by the TIR code generator would be the same of any packed function:
int32_t run_func(void* args, void* arg_type_ids, int32_t num_args, void* out_ret_value, void* out_ret_tcode, void* resource_handle);
In the following sub-sections we highlight some details about the code generation process.
Unpacked calls
Our code generator would issue tir.extern calls, manually packing/unpacking the arguments for the different operators contained in the library (very similar to what happens in the lower_builtin pass). In this way, we are de facto bypassing the function registry.
Runner descriptor
While it would be possible to directly expose run_func in the generated library we would wrap this function around a descriptor, i.e., a struct with the following fields:
typedef struct {
int32_t (*run_func)(void* args, void* arg_type_ids, int32_t num_args, void* out_ret_value, void* out_ret_tcode, void* resource_handle);
uint32_t num_input_tensors;
uint32_t num_output_tensors;
} tvm_model_t
Having run_func wrapped within a descriptor provides with different benefits:
- We can use the fields of the descriptor as a mean for the application to check the sanity of the arguments passed to the
run_func - This will be the only entry point that needs to be exposed by the library
network.o
Name mangling
TVM codegen should not invade the application symbol namespace and use the “implementation defined” namespace , which in C and C++ like languages (or indeed in Elf symbol land) is any symbol name prefixed with a _ . Further symbol names should be unique so that multiple models compiled can be statically linked into the same application. This can be achieved with the following changes:
- The user will specify a name for the network to compile, and the global names will be suffixed with this name
- The inner operators and the
run_funcwill be declared “static” within the library. In this case we shield them from the outside world and we only expose thetvm_model_tentry point (which will be properly suffixed).
Parameters
For now we will assume that the parameters are linked within the library: in other words the flag --link-params is mandatory with the AOT flow.
Bundling all the modules together
In our design we will store the generated IRModule as an additional field of the LoweredOutput data structure.
struct LoweredOutput {
std::string graph_json;
Map<String, IRModule> lowered_funcs;
IRModule aot_runtime; // This is the module generated that contains network_runner code
Array<tvm::runtime::Module> external_mods;
std::unordered_map<std::string, std::pair<int, const tvm::runtime::NDArray>> params;
};
We can then pass the aot_runtime module to CreateMetadataModule :
aot_ir_module = getAOTModule();
auto aot_mod = tvm::build(aot_module, target_host, target_host);
ret_.mod = tvm::codegen::CreateAOTModule(ret_.params, ret_.mod, ext_mods, aot_mod, GetTargetHost());
In the above snippet of code, the function CreateAOTModule will take care of adding the run_func definition in the library and will import the other modules (so that run_func will be common to all the modules).
Target host specification
To kick in the AOT flow we propose to add an additional runtime, namely aot, to the list of existing runtimes available in the target host.
The target host to generate an AOT-ready library would look like:
target_host = 'c --runtime=aot --link-params'
Please note that we don’t need to specify --system-lib anymore, since the system library won’t be included in the generated library.
Runtime changes
This section is about how we can expose to the user the content of the generated library network.o.
Our idea is to create an additional aot_runtime folder which would live next to the crt and graph runtime folders. In this way all the other flows will still be available and unchanged, and in the meanwhile we can gradually extend the aot runtime to support different use cases.
Before we move on in this section, let’s clarify the difference between the aot_runtime and the graph_runtime:
- Graph runtime - is the runtime used to read the json and to call the operators within the library.
- AOT runtime - this represents a shim layer containing helper functions to carry on the execution of the network
Graph runtime removal
The graph runtime in the current state takes care of:
- Initializing the Function Registry
- Initializing the memory manager
- Reading the json and calling into the functions defined in the generated library
With the AOT flow we got rid of (3), and by issuing unpacked calls we avoid the use of the Function Registry(1). The memory handling can be pushed directly into the aot runtime.
To be absolutely clear, we won’t need any Graph Runtime within the aot flow, since this is provided already by the generated library.
AOT runtime
The AOT runtime represents the shim layer provided to the user to invoke the given network compiled in the generated library. The API should include:
- Memory handling (which is traditionally part of the Graph Runtime, which we removed).
- Helpers to create DLTensors
- Helpers to invoke
run_funcinside the generated library
We will be developing the AOT runtime as a C API, so that it will be easy to deploy AOT flows on embedded devices.
It would not be extremely hard in the future to add a C++ API.
User API
Let’s try to flash out what the aot runtime user API should look like below:
// Helper function to initialize a DLTensor
DLTensor TVMInitializeDLTensor(void *data, DLDataType* dtype, DLContext* ctx, int64_t* shape, int64_t num_dim);
// Helper function to run the `run_func` within the generated library network.o.
tvm_crt_error_t TVMRuntime_Run(tvm_model_t *model, DLTensor *inputs, int num_inputs, DLTensor *outputs, int num_outputs);
Internal API
The API to handle memory during the network execution will be mostly internal and not exposed to the user. The idea is to assume those two constants are defined:
#define AOT_MEMORY_NUM_PAGES (1<<10)
#define AOT_MEMORY_PAGE_SIZE_LOG2 12
And use them to instantiate a static memory area. There are currently projects to estimate the memory footprint of the graph directly from TVMC (see, the MicroTVM roadmap)
Self contained example
To make things clearer, below there is a more detailed example that shows (in a pseudo-C language) how we intend everything to fit together. Please note that the library is supposed to be compiled with target=c --runtime=aot --link-param.
Code generation
In this section let’s have a look at what TVM would generate.
operators.c / lib.c
This contains the operators bodies and the body of _lookup_linked_param.
// lib.c
// Linked param lookup function definition
void _lookup_linked_param(TVMValue *,...) {}
// Operators definition
void fused_layout_transform_2(TVMValue *,...) {}
void fused_layout_transform_1(TVMValue *,...) {}
void fused_nn_contrib_conv2d_NCHWc_right_shift_cast(TVMValue *,...) {}
network.c
This file contains the declarations of the operators and the definition of run_func.
// network.c
// Linked param lookup function declaration
void _lookup_linked_param(TVMValue *,...);
// Operators declaration
void fused_layout_transform_2(TVMValue *,...);
void fused_layout_transform_1(TVMValue *,...);
void fused_nn_contrib_conv2d_NCHWc_right_shift_cast(TVMValue *,...);
// Main tvm__run_func (generated by TVM, which lives inside the library lib.o (or lib.c)
TVM_DLL int32_t tvm_run_func(TVMValue* values, ..., void* resource_handle) {
void* sid_3 = TVMBackendAllocWorkspace(1, 0, 32768, 2, 8);
// Call to the first operator. Note as values[1], the output of the network,
// is being used as an intermediate tensor by fused_layout_transform_2
TVMValue tensors_0[2] = { values[0], values[1] };
(void)fused_layout_transform_2(tensors, 2)
// Call to the second operator
TVMValue p0;
(void)_lookup_linked_param(2, &p0);
DLTensor sid_3_tensor = {.data = (*void) sid_3, ...};
TVMValue tensors_1[3] = {values[1], &p0, {.v_handle = sid_3_tensor}};
(void)fused_nn_contrib_conv2d_NCHWc_right_shift_cast(tensors, 3);
// Call to the third operator
TVMValue tensors_2[2] = {sid_3_tensor, values[1]};
(void)fused_layout_transform_1(tensors, 2);
}
// Entry point wrapper (generated by TVM, also lives inside the library)
tvm_model_t network = {
.run_func = _tvm_run_func;
.num_input_tensors = 1;
.num_output_tensors = 1;
}
Memory management
In this section we illustrate how the memory management side of the things will look like.
aot_platform.c
// aot_platform.c
#ifndef AOT_MEMORY_NUM_PAGES
#define AOT_MEMORY_NUM_PAGES (1<<10)
#endif
#ifndef AOT_MEMORY_PAGE_SIZE_LOG2
#define AOT_MEMORY_PAGE_SIZE_LOG2 12
#endif
static uint8 page_size_log2 = AOT_MEMORY_PAGE_SIZE_LOG2
static uint8_t g_aot_memory[AOT_MEMORY_NUM_PAGES * (1 << page_size_log2)];
static MemoryManagerInterface* g_memory_manager;
void* TVMBackendAllocWorkspace(int device_type, int device_id, uint64_t nbytes, int dtype_code_hint,
int dtype_bits_hint) {
void* ptr = 0;
DLContext ctx = {device_type, device_id};
return g_memory_manager->Allocate(g_memory_manager, num_bytes, ctx, ptr);
}
int TVMBackendFreeWorkspace(int device_type, int device_id, void* ptr) {
DLContext ctx = {device_type, device_id};
return g_memory_manager->Free(g_memory_manager, ptr, ctx);
}
MemoryManagerCreate(&g_memory_manager, g_aot_memory, total_size, page_size){
//copied from crt.
}
Shim layer exposed to the user
In this section we describe the shim interface layer used directly by the application.
aot_runtime.c
// aot_runtime.c
tvm_aot_error_t TVMRuntime_Run(tvm_model_t *model, DLTensor *inputs, int num_inputs, DLTensor *outputs, int num_outputs)
{
MemoryManagerCreate(g_memory_manager, g_aot_memory, sizeof(g_aot_memory), AOT_MEMORY_PAGE_SIZE_LOG2);
TVMValue tvm_values[num_inputs+num_outputs];
int i = 0;
for (; i<num_inputs; i++){
tvm_values[i] = {.v_handle = inputs[i]};
}
for (; i<num_outputs; i++){
tvm_values[i] = {.v_handle = outputs[i]};
}
model->run_func(tvm_values, ...);
}
Main application and compilation
In this section we will describe what the end user would write and how the shim would be invoked.
main.c
This file represent the main application written by the user
// main.c
#include <aot_runtime.h>
extern tvm_model_t * network;
int main()
{
DLTensor input = TVMInitializeDLTensor(..);
DLTensor output = TVMInitializeDLTensor(..);
DLTensor inputs[1] = {input};
DLTensor outputs[1] = {output};
TVMRuntime_Run(network, inputs, 1, outputs, 1);
}
We can compile everything with a command similar to:
# Compilation
$ $(CC) main.c lib.c aot_runtime.c aot_memory.c -DAOT_MEMORY_NUM_PAGES=(1<<12)
Conclusions
In this RFC we outlined the different parts of our proposal. These can be categorized in two macro
- Code generation
We decided to generate a
run_funcfunction to issue calls into the operators in the library. The function won’t make use of the function registry and of any helper contained within the library network.o - Runtime API We decided to provide a wrapper library (not generated) to be used by the users in order to call into the main function and create the necessary data structures to be passed to it
Please share your thoughts/feedbacks!
