Hi, I’m trying to manually run a model generated using relay.build. I get the kernel source code, launch paramter, and graph json. I wish I could launch the kernel in the order of the dependencies in graph json.I wrote a simple mlp demo, and I get some problem.There are only five nodes in graph json, however, when I tested with nsight compute, I found that six kernel were launched. so I’m confused about graph json.Here is my graph json
{
"nodes": [
{
"op": "null",
"name": "input0",
"inputs": []
},
{
"op": "null",
"name": "p0",
"inputs": []
},
{
"op": "null",
"name": "p1",
"inputs": []
},
{
"op": "tvm_op",
"name": "tvmgen_default_fused_nn_dense_add_nn_relu",
"attrs": {
"num_outputs": "1",
"num_inputs": "3",
"flatten_data": "0",
"hash": "3f0723cf7872cbb4",
"func_name": "tvmgen_default_fused_nn_dense_add_nn_relu"
},
"inputs": [
[
0,
0,
0
],
[
1,
0,
0
],
[
2,
0,
0
]
]
},
{
"op": "null",
"name": "p2",
"inputs": []
},
{
"op": "null",
"name": "p3",
"inputs": []
},
{
"op": "tvm_op",
"name": "tvmgen_default_fused_nn_dense_add_nn_relu_1",
"attrs": {
"num_outputs": "1",
"num_inputs": "3",
"flatten_data": "0",
"hash": "ed9033e4da22e0dc",
"func_name": "tvmgen_default_fused_nn_dense_add_nn_relu_1"
},
"inputs": [
[
3,
0,
0
],
[
4,
0,
0
],
[
5,
0,
0
]
]
},
{
"op": "null",
"name": "p4",
"inputs": []
},
{
"op": "null",
"name": "p5",
"inputs": []
},
{
"op": "tvm_op",
"name": "tvmgen_default_fused_nn_dense_add_nn_relu_2",
"attrs": {
"num_outputs": "1",
"num_inputs": "3",
"flatten_data": "0",
"hash": "ccf415d3b301cacc",
"func_name": "tvmgen_default_fused_nn_dense_add_nn_relu_2"
},
"inputs": [
[
6,
0,
0
],
[
7,
0,
0
],
[
8,
0,
0
]
]
},
{
"op": "null",
"name": "p6",
"inputs": []
},
{
"op": "null",
"name": "p7",
"inputs": []
},
{
"op": "tvm_op",
"name": "tvmgen_default_fused_nn_dense_add",
"attrs": {
"num_outputs": "1",
"num_inputs": "3",
"flatten_data": "0",
"hash": "d2b56f07a0b90cc6",
"func_name": "tvmgen_default_fused_nn_dense_add"
},
"inputs": [
[
9,
0,
0
],
[
10,
0,
0
],
[
11,
0,
0
]
]
},
{
"op": "tvm_op",
"name": "tvmgen_default_fused_nn_log_softmax",
"attrs": {
"num_outputs": "1",
"num_inputs": "1",
"flatten_data": "0",
"hash": "841889b03873dc2a",
"func_name": "tvmgen_default_fused_nn_log_softmax"
},
"inputs": [
[
12,
0,
0
]
]
}
],
"arg_nodes": [0, 1, 2, 4, 5, 7, 8, 10, 11],
"heads": [
[
13,
0,
0
]
],
"attrs": {
"dltype": [
"list_str",
[
"float32",
"float32",
"float32",
"float32",
"float32",
"float32",
"float32",
"float32",
"float32",
"float32",
"float32",
"float32",
"float32",
"float32"
]
],
"shape": [
"list_shape",
[
[1, 100],
[400, 100],
[1, 400],
[1, 400],
[1000, 400],
[1, 1000],
[1, 1000],
[2000, 1000],
[1, 2000],
[1, 2000],
[10, 2000],
[1, 10],
[1, 10],
[1, 10]
]
],
"device_index": [
"list_int",
[
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2,
2
]
],
"storage_id": [
"list_int",
[
0,
1,
2,
3,
4,
5,
6,
7,
8,
3,
9,
10,
11,
12
]
]
},
"node_row_ptr": [
0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14
]
}
and here is the visualization
here is the results of nsight compute(CSV file)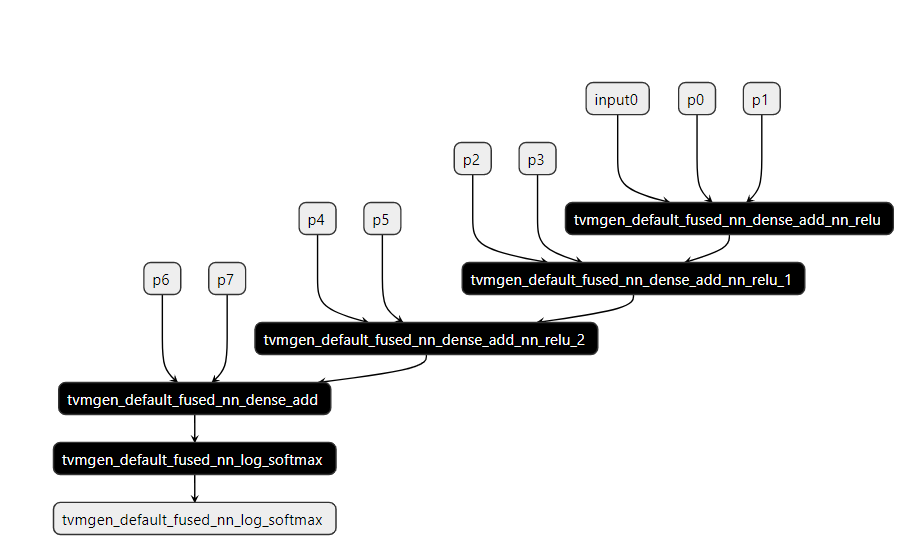
ID,Process ID,Process Name,Host Name,Kernel Name,Context,Stream,Block Size,Grid Size,Device,CC,Section Name,Metric Name,Metric Unit,Metric Value,Rule Name,Rule Type,Rule Description
0,119759,python3.8,127.0.0.1,tvmgen_default_fused_nn_dense_add_nn_relu_kernel0,1,7,"(20, 1, 1)","(400, 1, 1)",0,8.6,Launch Statistics,Dynamic Shared Memory Per Block,byte/block,0,,,
1,119759,python3.8,127.0.0.1,tvmgen_default_fused_nn_dense_add_nn_relu_1_kernel0,1,7,"(20, 1, 1)","(1000, 1, 1)",0,8.6,Launch Statistics,Dynamic Shared Memory Per Block,byte/block,0,,,
2,119759,python3.8,127.0.0.1,tvmgen_default_fused_nn_dense_add_nn_relu_2_kernel0,1,7,"(50, 1, 1)","(2000, 1, 1)",0,8.6,Launch Statistics,Dynamic Shared Memory Per Block,byte/block,0,,,
3,119759,python3.8,127.0.0.1,tvmgen_default_fused_nn_dense_add_kernel0,1,7,"(250, 1, 1)","(10, 1, 1)",0,8.6,Launch Statistics,Dynamic Shared Memory Per Block,byte/block,0,,,
4,119759,python3.8,127.0.0.1,tvmgen_default_fused_nn_log_softmax_kernel0,1,7,"(32, 1, 1)","(1, 1, 1)",0,8.6,Launch Statistics,Dynamic Shared Memory Per Block,byte/block,0,,,
5,119759,python3.8,127.0.0.1,tvmgen_default_fused_nn_log_softmax_kernel1,1,7,"(32, 1, 1)","(1, 1, 1)",0,8.6,Launch Statistics,Dynamic Shared Memory Per Block,byte/block,0,,,