I am trying to tune a GPU kernel on 8-card server and want to parallelize to speedup. I follow an old post How to tune CNN networks with multiple gpu devices? - #3 by nicklhy and set separate rpc_server as following
CUDA_VISIBLE_DEVICES=1 python3 -m tvm.exec.rpc_server --key 1080ti --tracker ...
CUDA_VISIBLE_DEVICES=7 python3 -m tvm.exec.rpc_server --key 1080ti --tracker ...
and my tuning configuration is
rpc_runner = auto_scheduler.RPCRunner(
device_key,
host=rpc_host,
port=rpc_port,
timeout=30,
repeat=1,
n_parallel=4,
min_repeat_ms=200,
enable_cpu_cache_flush=True,
)
tuner = auto_scheduler.TaskScheduler(tasks, task_weights)
tune_option = auto_scheduler.TuningOptions(
num_measure_trials=200, # change this to 20000 to achieve the best performance
runner=rpc_runner,
measure_callbacks=[auto_scheduler.RecordToFile(log_file)],
)
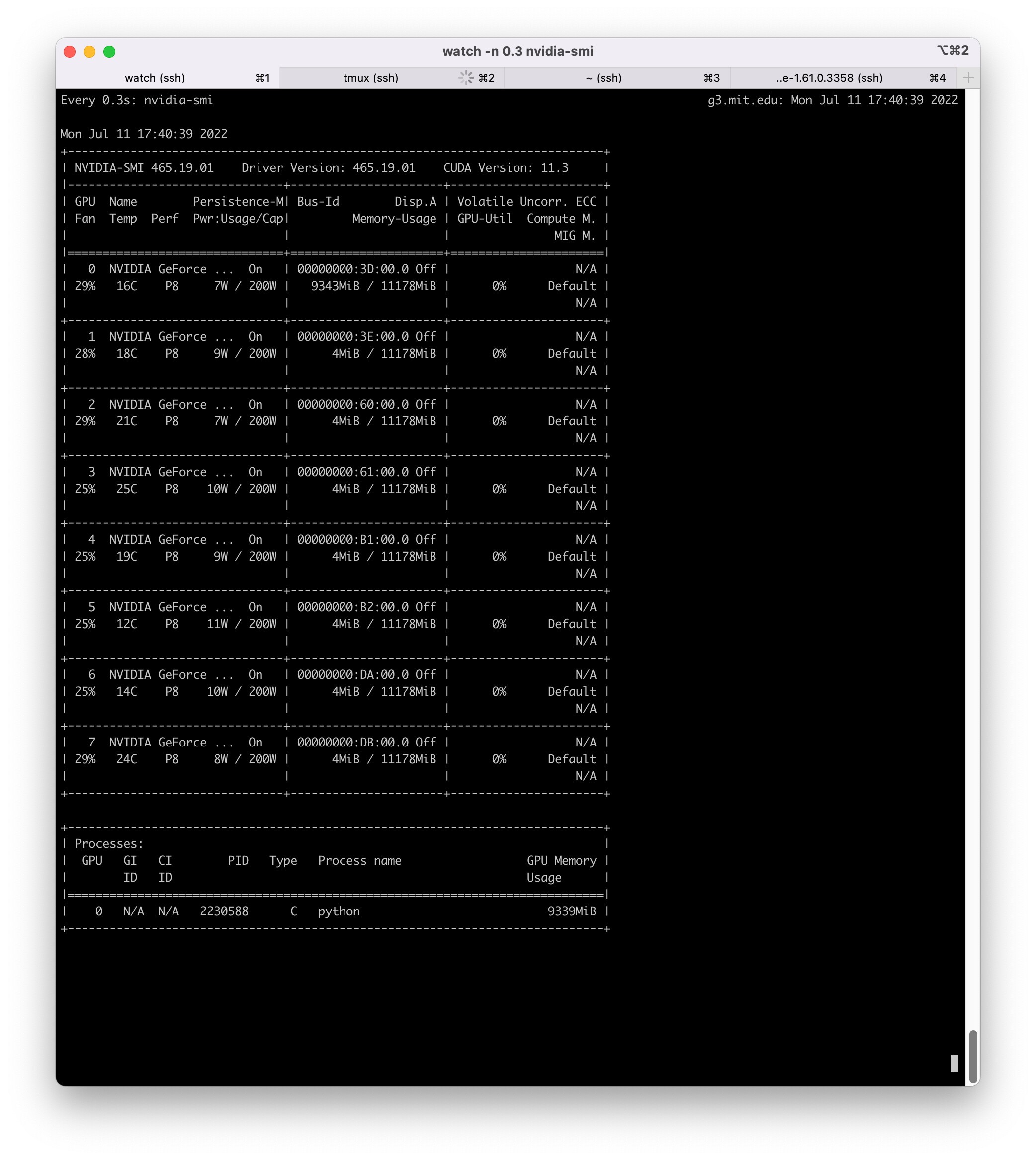
However, only device:0 is utlized
cc @merrymercy