We have a use case where we need to support running TensorRT (TRT) from TVM. The basic idea is feed subgraphs containing TRT compatible operators to TRT engine for compilation and execution, and compile and run the rest of operators in the graph using TVM.
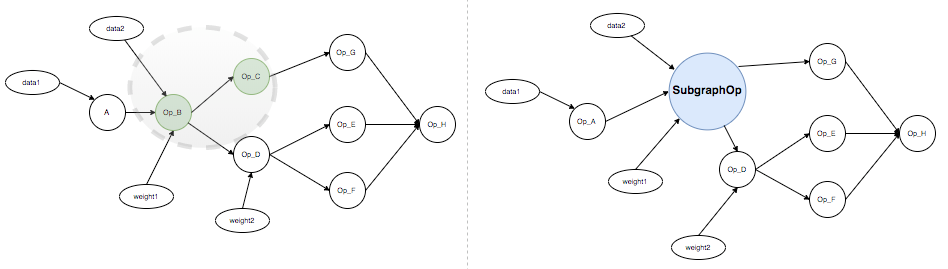
I was thinking about implementing a subgraph operator that contains a subgraph, input and output tensors that can be digested by TRT, and we can do graph partitioning to replace TRT compatible operators with this kind of subgraph operator in the whole graph before compiling and running the whole graph. Taking the following picture as an example, let’s say operator B and C are TRT compatible (left), we group them into a subgraph and use a subgraph op node to replace them in the whole graph (right).
While we did the similar thing for MXNet in this PR, it’s not obvious to me on how to achieve the same effect in TVM. One of the major difficulties that blocks me is when I want to register a subgraph operator with the attribute FTVMCompute, the input/output tensors are just symbols for defining the operator expression, while the TRT engine needs concrete NDArray data as in MXNet’s FCompute attribute.
It seems that I am thinking in the wrong direction of designing the integration pass. Can someone help me sort out a feasible way for the integration? Thanks.
@tqchen@yzhliu
I agree with @yzhliu’s general take, but maybe we still need to wrap the TensorRT a bit in PackedFunc and use extern. We are on the process on adding next generation IR in this release cycle and we can discuss how to integrate that with the new IR
Thank @tqchen and @yzhliu, I will move toward the direction as @yzhliu pointed out. Due to the legacy reason in our use cases, we may have to play with the NNVM IR for quite a while before moving the next gen IR. But I would definitely like to be involved in the discussion on how to support this kind of integration with the new IR.
@tqchen@yzhliu My integration now is able to bypass TensorRT subgraph operators in the compile stage and run subgraphs using the TensorRT engine in the TVM runtime, there is a catch in the situation when all the operators are TRT compatible though. In such a case, there is no generated code for any operators and therefore it leaves the Module instance at default constructed state. When users call export_library() upon the lib returned from nnvm.compiler.build, it would crash as the node_ in tvm::runtime::Module is nullptr. It can be simply reproduced using the following script where the whole graph has just a variable node. Should TVM support such empty Modules in export/import? Thanks.