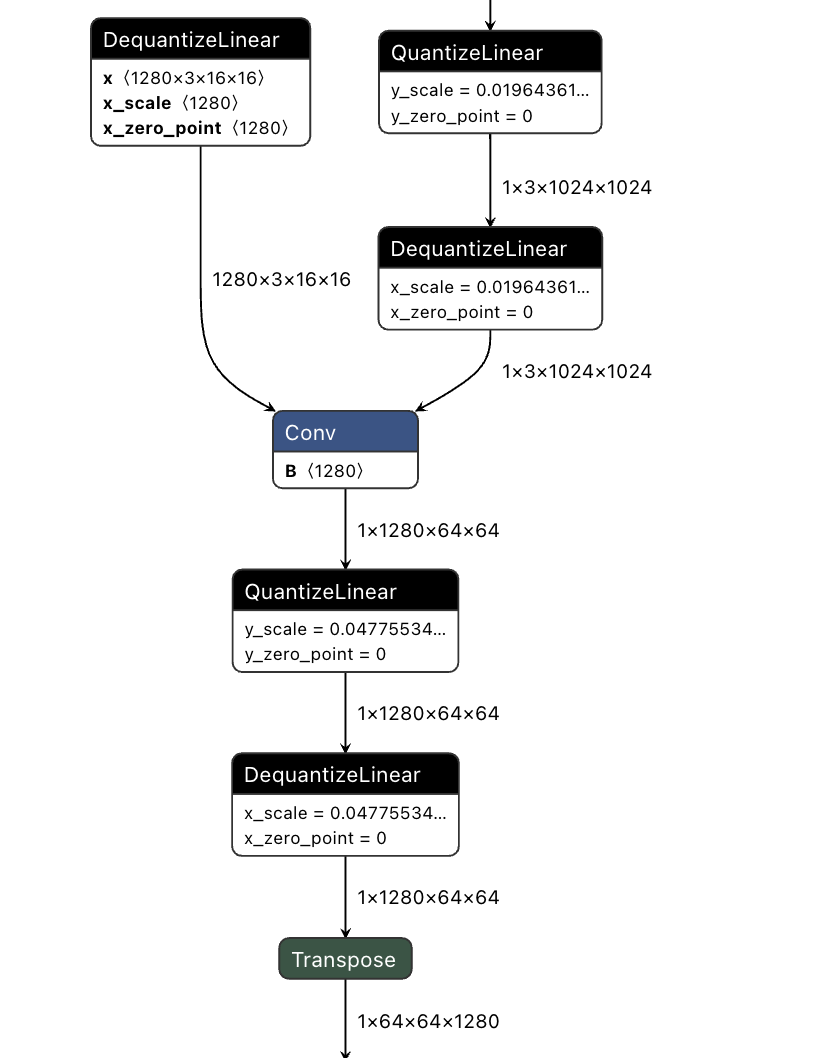
For example, I now have a PTQ finished onnx model, and I now want to make it run under the TVM runtime.
mod, params = relay_from_onnx(
onnx_model, opset=13, freeze_params=True, shape={"input.1": (1, 3, 1024, 1024)}
)
passes = tvm.transform.Sequential([
relay.transform.InferType(),
relay.transform.FakeQuantizationToInteger(),
])
mod = passes(mod)
I tried to use the above code but I feel that TVM doesn’t handle delayed dequant operations, for example I want to do Q-DQ-conv-Q-DQ-conv becomes Q-conv-requant-conv-requant-DQ. i.e. implement full int8 inference. Is there any way to do this?
2 Likes
I think you should do write bettern pattern match relay pass to complete this task, for example propagating DQ you mentioned as far as possible. Take your graph as example, Q-DQ-Conv-Q-DQ is a pattern match, you could become fp32-> Q->i8 → conv → DQ → fp32, however we could do more, because Transpose op is a shape manipulation op, we could propagate DQ. fp32-> Q->i8 → conv → transpose → DQ → fp32. I think current existing relay pass doesn’t handle it very well