Can we use relay.build to convert mod and params to GCC compilable C/C++ code? If so, how do we see (print) the generated code?
2 Likes
+1, interested as well.
I am also interested in this since I have recently found a problem while trying to do the same.
At least for single functions, you can get the “c” source by doing the following:
import tvm
from tvm import te
n = 2
A = te.placeholder((n,), name='A')
B = te.placeholder((n,), name='B')
C = te.compute(A.shape, lambda *i: A(*i) + B(*i), name='C')
s = tvm.te.create_schedule(C.op)
m = tvm.lower(s, [A, B, C], name="test_add")
rt_mod = tvm.build(m, target="c")#look here
print(rt_mod.get_source())
I would imagine using the same target for relay.build(..) would work.
Nonetheless, for a certain network I imported from onnx I get the following problem:
File “~/tvm/src/target/source/codegen_c_host.cc”, line 132 TVMError: Cannot convert type float32x50 to C type
So I would be interested in knowing if I am the only one with this problem. If you try it out for your model and dont get any errors please let me know.
It looks like when the target is “c”, the generated C code only includes individual ops. You can see the code by doing lib.get_source(). However, there is no code for putting those ops into an actual runnable C program. Even the necessary headers are not included in the code from get_source(). It is very confusing.
Well there isn’t an Ahead Of Time compiler at this moment, so you always have to include the runtime code.
There is an example of compiling a standalone static “bundle” app. Here the link to what I mean . I am not really sure how up-to-date this is since I almost never see it being discussed.
Which headers are missing? mind showing some example code?
Using the program you provided as an example, the generated C code is
#include "tvm/runtime/c_runtime_api.h"
#include "tvm/runtime/c_backend_api.h"
void* __tvm_module_ctx = NULL;
#ifdef __cplusplus
extern "C"
#endif
TVM_DLL int32_t test_add(void* args, void* arg_type_ids, int32_t num_args, void* out_ret_value, void* out_ret_tcode, void* resource_handle) {
void* arg0 = (((TVMValue*)args)[0].v_handle);
int32_t arg0_code = ((int32_t*)arg_type_ids)[(0)];
void* arg1 = (((TVMValue*)args)[1].v_handle);
int32_t arg1_code = ((int32_t*)arg_type_ids)[(1)];
void* arg2 = (((TVMValue*)args)[2].v_handle);
int32_t arg2_code = ((int32_t*)arg_type_ids)[(2)];
void* A = (((DLTensor*)arg0)[0].data);
void* arg0_shape = (((DLTensor*)arg0)[0].shape);
void* arg0_strides = (((DLTensor*)arg0)[0].strides);
int32_t dev_id = (((DLTensor*)arg0)[0].ctx.device_id);
void* B = (((DLTensor*)arg1)[0].data);
void* arg1_shape = (((DLTensor*)arg1)[0].shape);
void* arg1_strides = (((DLTensor*)arg1)[0].strides);
void* C = (((DLTensor*)arg2)[0].data);
void* arg2_shape = (((DLTensor*)arg2)[0].shape);
void* arg2_strides = (((DLTensor*)arg2)[0].strides);
if (!(arg0_strides == NULL)) {
}
if (!(arg1_strides == NULL)) {
}
if (!(arg2_strides == NULL)) {
}
for (int32_t i0 = 0; i0 < 2; ++i0) {
((float*)C)[(i0)] = (((float*)A)[(i0)] + ((float*)B)[(i0)]);
}
return 0;
}
The included headers are
“tvm/runtime/c_runtime_api.h”
“tvm/runtime/c_backend_api.h”
I want to know how to generate something like below
// The example Relay graph: conv2d -> add -> relu.
#include <cstdint>
#include <cstdlib>
#include <cstring>
#include <vector>
#include <tvm/runtime/c_runtime_api.h>
#include <tvm/runtime/container.h>
#include <tvm/runtime/packed_func.h>
#include <dlpack/dlpack.h>
#include <dnnl/dnnl_kernel.h>
using namespace tvm::runtime;
using namespace tvm::runtime::contrib;
// Execute the conv2d->add->relu graph with DNNL.
extern "C" void dnnl_0_(float* dnnl_0_i0, float* dnnl_0_i1,
float* dnnl_0_i2, float* out0) {
// Allocate intermediate buffers.
float* buf_0 = (float*)std::malloc(4 * 4608);
float* buf_1 = (float*)std::malloc(4 * 4608);
float* buf_2 = (float*)std::malloc(4 * 4608);
// Pre-implemented op-based DNNL functions.
dnnl_conv2d(dnnl_0_i0, dnnl_0_i1, buf_0, 1, 32, 14, 14, 32, 1, 0, 0, 3, 3, 1, 1);
dnnl_add(buf_0, dnnl_0_i2, buf_1, 1, 32, 12, 12);
dnnl_relu(buf_1, buf_2, 1, 32, 12, 12);
// Copy the final output to the corresponding buffer.
std::memcpy(out0, buf_2, 4 * 4608);
std::free(buf_0);
std::free(buf_1);
std::free(buf_2);
}
// The wrapper function with all arguments in DLTensor type.
extern "C" int dnnl_0_wrapper_(DLTensor* arg0,
DLTensor* arg1,
DLTensor* arg2,
DLTensor* out0) {
// Cast all DLTensor to primitive type buffers and invoke the above
// execution function.
dnnl_0_(static_cast<float*>(arg0->data),
static_cast<float*>(arg1->data),
static_cast<float*>(arg2->data),
static_cast<float*>(out0->data));
return 0;
}
// The TVM macro to generate TVM runtime compatible function "dnnl_0"
// from our generated "dnnl_0_wrapper_".
TVM_DLL_EXPORT_TYPED_FUNC(dnnl_0, dnnl_0_wrapper_);
I want to know what exact python function is responsible for generate the above C code.
Well that code you want to generate looks like this blogpost and also similar to this example in the BYOC tutorial.
But I was never under the impression that such a file could be generated by TVM.
I looked both tutorials but neither mentioned how to generate C code after relay.build. A minimal example (like a LeNet) would be very helpful.
I dont think there is a python function which generates what you want.
There is a c++ file with functions which do generate those output files.
End-to-end I still dont know how to go from the network to here, but there is a small test python script which might help you.
There is an experimental AoT compiler which does what you want https://github.com/uwsampl/relay-aot, @slyubomirsky was working on upstreaming it to master.
Thanks for bringing this thread to my attention, Jared. The AoT compiler right now still relies on TVM’s JIT to handle the operator implementations (it translates Relay code into C++), so to get a complete implementation of the model in C++, I think you would also need to use TVM’s C backend to produce the operator implementations in C. The AoT compiler would have to be extended to properly stitch these together.
Thanks for giving some detail on the AOT.
Would you mind elaborating more on how it would work?
What exactly do you mean here? do you literally mean the JIT function in the CompileEngine?. If I understood you correctly, it seem the AOT compiler would compile everything except the operator implementations and during execution of the graph it would JIT the operators?
AFAIK if we do target the ‘c’ target, then TVM generates a C file (I think its only one but I might be wrong or its an artifact of the examples I have seen), which contains all the primfuncs which are part of the graph after all optimizations at Relay level. The thing which was missing is the graph walker which calls into these functions. That part has always been done by the graph runtime. I would have expected the AOT to output the same file with the primfunc implementations and another file (or other section of code) with the graph walk. Is this not how it is currently designed/planned?
Yes, I was indeed referring to the literal JIT function, which the AoT compiler calls here: https://github.com/uwsampl/relay-aot/blob/master/aot/aot.py#L114
The AoT compiler calls into TVM’s registry to fetch the compiled operator implementations when it needs them: https://github.com/uwsampl/relay-aot/blob/master/aot/to_source.py#L318 (you can see in the rest of the file how it translates everything else in Relay into C++)
The AoT compiler as written saves quite a bit of runtime overhead but, as the line from to_source.py shows, it does still call into TVM to fetch pre-compiled operator implementations. To get a complete network implementation into C++, you would have to replace those calls with the operator implementations generated by the C backend.
Hello, did you solve this question?
1 Like
Hello, did you solve this question?
1 Like
hi @x-huan,
we now have a full solution for this via the AOT compiler. Right now I believe we just have a tutorial on how to do this with Ethos-U, but you could probably adapt the approach by changing the target. It does not require lookup into TVM (it also only works with things targeting c or llvm right now).
let me know if that helps, Andrew
Hi, @areusch it looks helpful. But my model is defined by Pytorch. In this case, I should change my model to TFlite, right? And I get the source code from my model in this way
it shows like below: it’ s a very long file, is that right? And what’ s more, is it exactly what cuda code run in GPU?
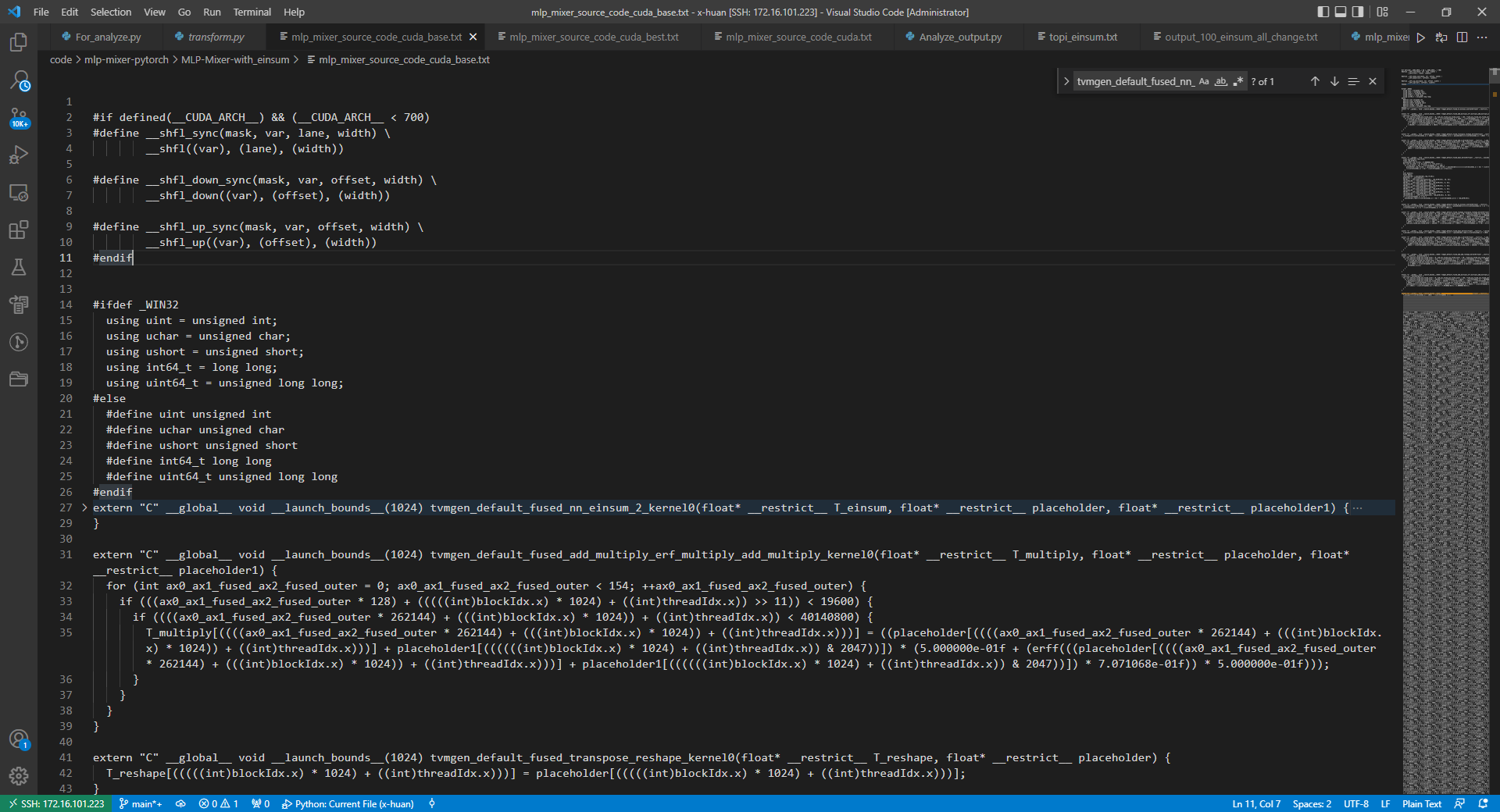
@x-huan the tutorial uses a TFLite model because it’s intended for a microTVM. In principle the workflow should be usable with anything you can import into Relay–so, it should work with those PyTorch models which are supported by our Relay importer.
however, with that said I’d be surprised if it works on CUDA or at least reliably works on CUDA. It will probably only be functional on CPU targets for now, as we can’t yet use all features of the Device API.
So, what you mean is that the cuda code is not the reliable code? It’ s not the correct code. right?
No the CUDA source code is likely fine. AOTExecutor generates another piece of code which runs on CPU and can only work with the CUDA code in limited ways at the moment.