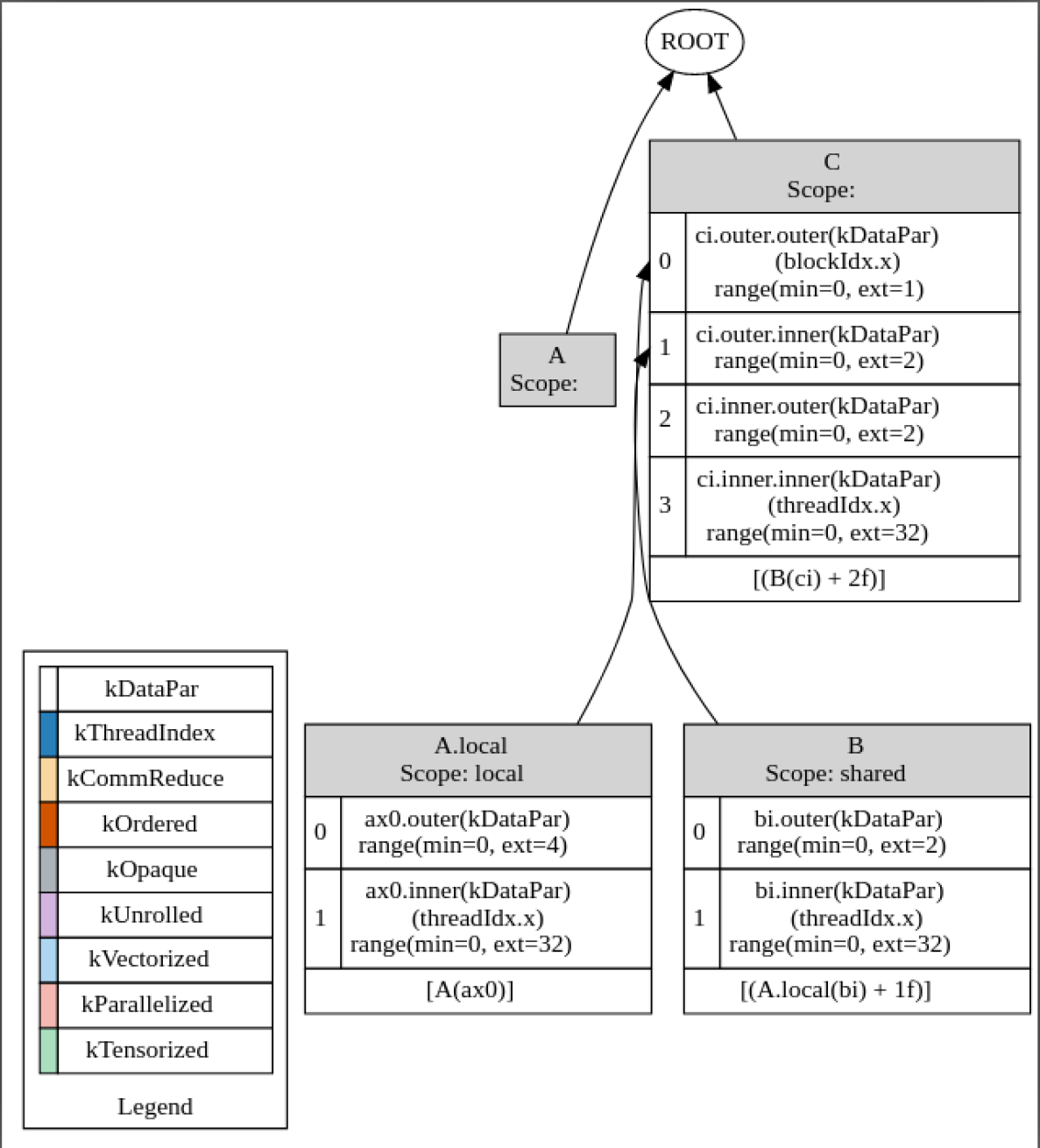
Hello, I found sometimes registers are allocated more than expected in CUDA code generation. It usually happens when data is cached in registers and read to shared memory chunk by chunk.
Here’s a simple example resembling an actual problem I recently encountered. I’m aiming at reading the whole A tensor and caching the data in registers, then calculate B in the shared memory through blocking with this data, and write to C as the output.
import tvm
def schedule(A, B, C):
s = tvm.create_schedule(C.op)
AA = s.cache_read(A, "local", [B])
s[B].set_scope("shared")
block_x = tvm.thread_axis("blockIdx.x")
thread_x = tvm.thread_axis((0, 32), "threadIdx.x")
oc, ic = s[C].split(s[C].op.axis[0], factor=64)
ooc, ioc = s[C].split(oc, factor=2)
oic, iic = s[C].split(ic, factor=32)
s[C].bind(ooc, block_x)
s[C].bind(iic, thread_x)
s[B].compute_at(s[C], ioc)
ob, ib = s[B].split(s[B].op.axis[0], factor=32)
s[B].bind(ib, thread_x)
s[AA].compute_root()
s[AA].compute_at(s[C], ooc)
oaa, iaa = s[AA].split(s[AA].op.axis[0], factor=32)
s[AA].bind(iaa, thread_x)
return s
def test():
A = tvm.placeholder((128,), name="A")
B = tvm.compute((128,), lambda i: A[i] + 1, name="B")
C = tvm.compute((128,), lambda i: B[i] + 2, name="C")
device = "cuda"
ctx = tvm.context(device, 0)
with tvm.target.create(device):
s = schedule(A, B, C)
print(tvm.lower(s, [A, B, C], simple_mode=True))
func = tvm.build(s, [A, B, C], device, name=("test"))
print(func.imported_modules[0].get_source())
if __name__ == "__main__":
test()
However, in the result schedule here:
produce C {
// attr [iter_var(blockIdx.x, , blockIdx.x)] thread_extent = 1
// attr [A.local] storage_scope = "local"
allocate A.local[float32 * 97]
produce A.local {
for (ax0.outer, 0, 4) {
// attr [iter_var(threadIdx.x, range(min=0, ext=32), threadIdx.x)] thread_extent = 32
if (likely((((ax0.outer*32) + threadIdx.x) < 97))) {
if (likely((((ax0.outer*32) + (threadIdx.x*2)) < 128))) {
A.local[((ax0.outer*32) + threadIdx.x)] = A[((ax0.outer*32) + (threadIdx.x*2))]
}
}
}
}
for (i.outer.inner, 0, 2) {
produce B {
for (i.outer, 0, 2) {
// attr [iter_var(threadIdx.x, range(min=0, ext=32), threadIdx.x)] thread_extent = 32
B[(((i.outer.inner*64) + (i.outer*32)) + threadIdx.x)] = (A.local[((i.outer.inner*64) + (i.outer*32))] + 1f)
}
}
for (i.inner.outer, 0, 2) {
// attr [iter_var(threadIdx.x, range(min=0, ext=32), threadIdx.x)] thread_extent = 32
C[(((i.outer.inner*64) + (i.inner.outer*32)) + threadIdx.x)] = (B[(((i.outer.inner*64) + (i.inner.outer*32)) + threadIdx.x)] + 2f)
}
}
}
I find that the compiler allocates 97 registers for A.local which is not what I want. In fact I expect it to allocate only 4 registers per thread which is enough to carry out the computation correctly according to the schedule. What I expect is that each thread reads 4 elements of A, stores them in registers, calculates 2 elements of B and C each time, and repeats that twice.
I think the number 97 comes from: it needs 97 registers to hold A[0], A[32], A[64] and A[96] if the whole chunk of data from A[0] to A[96] is stored in thread 0 (and so on for other threads).
I have encountered a similar problem before, and I solve it by binding the axis ax0.outer to vthread_x. But this time I need to keep the for loop of ax0.outer so vthread is out of the question.
Anyone can help?