So, we want to use VTCM to acclerate the computation.
And we follow the test file here and everything is ok.
What we want is something similar to preloaded_vrmpy in the test file, as follows.

The TIR of preloaded_vrmpy is like this:
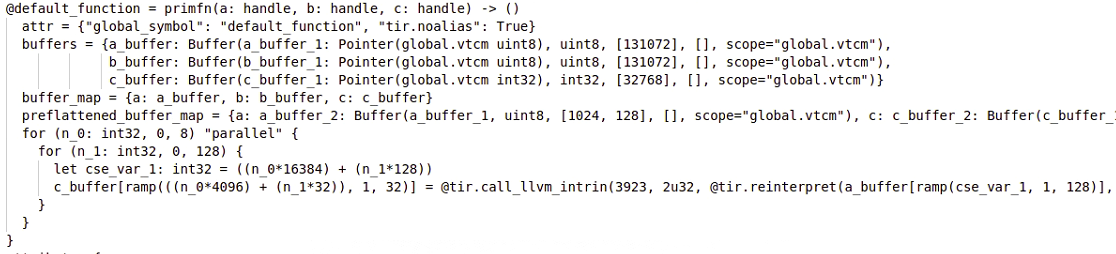
Right now, we have a model imported from tflite.
And we have applied vectorization to it.
However, although we have allocated buffers in the TIR to VTCM as shown above, in some ugly way, the running time does not change before and after using VTCM.
That’s weired. So I wonder if we have missed some other important thing.
If anyone could provide some help or suggestions, it would be greatly appreciated.