I am wondering if I am using a custom accelerator, Can I skip code generation for the sub-graph that have first class support in the accelerator. The accelerator comes with its own SW stack and has its own proprietary code generation which can’t be exposed to TVM. However some operator support is missing, Can I farm the execution on the accelerator at a sub-graph level. In the figure below, can the Blue nodes as a whole be executed on the custom HW without paying the cost of data transfers for in-between layers?
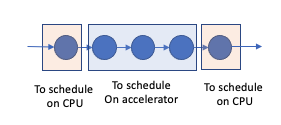
You might want to look into the BYOC flow. TVM Blog - Bring Your Own Codegeneration
It looks like a perfect solution for your task. You most likely need to do three things:
- Define, which subgraphs and nodes need to be mapped to your accelerator
- Interface the Relay graph-level IR with your codegeneration (do not need to expose it to TVM)
- Build Interface for runtime/execution, where TVM and your accelerator can exchange input and output tensors
Thanks @max1996 ! Somehow missed/overlooked this. Looks very promising.