I’m interested in heterogeneous execution on multiple GPU, the basic idea is to schedule different ops to different GPU.
What I expected was:
GPU-0 executes ‘sigmoid’ and ‘tanh’
GPU-1 executes ‘nn.dense’
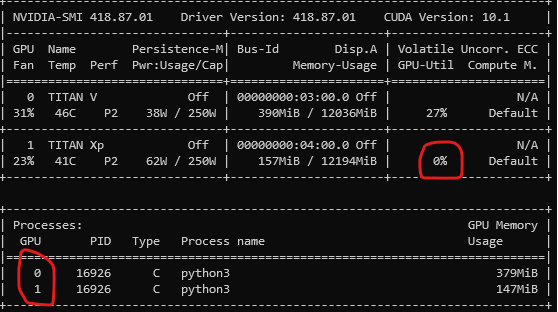
However, the result seems that all the operators are executed on GPU-0, as I observed that only the GPU-0 is busy even if I place all ops to the GPU-1
Any comments and suggestions are greatly appreciated.
The code is referenced from [Heterogeneous execution examle]
annotated_ops_list_gpu0 = {"sigmoid", "tanh"}
annotated_relay_ops_gpu0 = [tvm.relay.op.get(op) for op in annotated_ops_list_gpu0]
annotated_ops_list_gpu1 = {"nn.dense"}
annotated_relay_ops_gpu1 = [tvm.relay.op.get(op) for op in annotated_ops_list_gpu1]
class ScheduleDense(ExprMutator):
def __init__(self, device_0, device_1):
self.device_0 = device_0
self.device_1 = device_1
super(ScheduleDense, self).__init__()
def visit_call(self, expr):
visit = super().visit_call(expr)
if expr.op in annotated_relay_ops_gpu0:
return relay.annotation.on_device(visit, self.device_1)
elif expr.op in annotated_relay_ops_gpu1:
return relay.annotation.on_device(visit, self.device_1)
else:
return visit
def schedule_dense_on_gpu(expr):
sched = ScheduleDense(tvm.gpu(2), tvm.gpu(1))
return sched.visit(expr)
I think that problem might be both GPU-0, GPU-1 which context has same device_type is 2, and maybe in TVM Context Mapping, these GPUs seems to change to one GPU device 0, GPU-0.
It’s not accurate, so I think the Contributor should let you know.
Is this solved? I’m curious too
1 Like
lizexu
November 17, 2021, 8:11am
4
Maxwell-Hu:
I’m interested in heterogeneous execution on multiple GPU, the basic idea is to schedule different ops to different GPU.
What I expected was:
GPU-0 executes ‘sigmoid’ and ‘tanh’
GPU-1 executes ‘nn.dense’
However, the result seems that all the operators are executed on GPU-0, as I observed that only the GPU-0 is busy even if I place all ops to the GPU-1
Any comments and suggestions are greatly appreciated.
The code is referenced from [Heterogeneous execution examle]
annotated_ops_list_gpu0 = {"sigmoid", "tanh"}
annotated_relay_ops_gpu0 = [tvm.relay.op.get(op) for op in annotated_ops_list_gpu0]
annotated_ops_list_gpu1 = {"nn.dense"}
annotated_relay_ops_gpu1 = [tvm.relay.op.get(op) for op in annotated_ops_list_gpu1]
class ScheduleDense(ExprMutator):
def __init__(self, device_0, device_1):
self.device_0 = device_0
self.device_1 = device_1
super(ScheduleDense, self).__init__()
def visit_call(self, expr):
visit = super().visit_call(expr)
if expr.op in annotated_relay_ops_gpu0:
return relay.annotation.on_device(visit, self.device_1)
elif expr.op in annotated_relay_ops_gpu1:
return relay.annotation.on_device(visit, self.device_1)
else:
return visit
def schedule_dense_on_gpu(expr):
sched = ScheduleDense(tvm.gpu(2), tvm.gpu(1))
return sched.visit(expr)
Nín hǎo, zhège wèntí jiějuéle ma
volume_up
11 / 5000
Hello, is this problem solved?