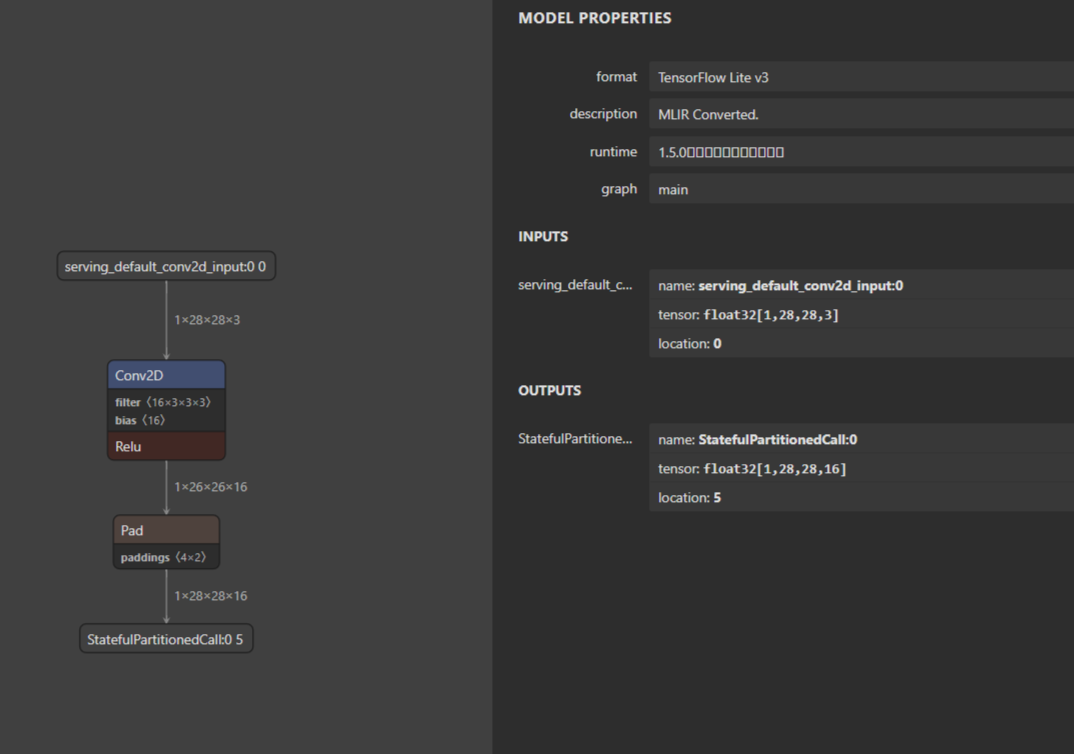
@kvegiraj The generated mod for me is:
def @main(%serving_default_conv2d_input:0: Tensor[(1, 28, 28, 3), float32] /* ty=Tensor[(1, 28, 28, 3), float32] span=serving_default_conv2d_input:0:0:0 */, %v_param_1: Tensor[(3, 3, 3, 16), float32] /* ty=Tensor[(3, 3, 3, 16), float32] span=sequential/conv2d/Conv2D:0:0 */, %v_param_2: Tensor[(16), float32] /* ty=Tensor[(16), float32] span=sequential/conv2d/BiasAdd/ReadVariableOp:0:0 */, output_tensor_names=["StatefulPartitionedCall_0"]) -> Tensor[(1, 28, 28, 16), float32] {
%0 = layout_transform(%serving_default_conv2d_input:0, src_layout="NHWC", dst_layout="NCHW") /* ty=Tensor[(1, 3, 28, 28), float32] */;
%1 = layout_transform(%v_param_1, src_layout="HWIO", dst_layout="OIHW") /* ty=Tensor[(16, 3, 3, 3), float32] */;
%2 = expand_dims(%v_param_2, axis=0, num_newaxis=3) /* ty=Tensor[(1, 1, 1, 16), float32] */;
%3 = nn.conv2d(%0, %1, padding=[0, 0, 0, 0], channels=16, kernel_size=[3, 3]) /* ty=Tensor[(1, 16, 26, 26), float32] span=sequential/conv2d/Relu;sequential/conv2d/BiasAdd;sequential/conv2d/BiasAdd/ReadVariableOp;sequential/conv2d/Conv2D:0:0 */;
%4 = layout_transform(%2, src_layout="NHWC", dst_layout="NCHW") /* ty=Tensor[(1, 16, 1, 1), float32] */;
%5 = add(%3, %4) /* ty=Tensor[(1, 16, 26, 26), float32] */;
%6 = nn.relu(%5) /* ty=Tensor[(1, 16, 26, 26), float32] span=sequential/conv2d/Relu;sequential/conv2d/BiasAdd;sequential/conv2d/BiasAdd/ReadVariableOp;sequential/conv2d/Conv2D:0:0 */;
%7 = nn.pad(%6, 0 /* ty=int32 span=StatefulPartitionedCall:0:0:0 */, pad_width=[[0, 0], [0, 0], [1, 1], [1, 1]]) /* ty=Tensor[(1, 16, 28, 28), float32] span=StatefulPartitionedCall:0:0:0 */;
layout_transform(%7, src_layout="NCHW", dst_layout="NHWC") /* ty=Tensor[(1, 28, 28, 16), float32] */
}
I’m running this using this code to get the mean inference time and getting
InternalError: Check failed: (result == CL_SUCCESS) is false: clEnqueueCopyMLTensorDataQCOM:-48
import tvm
import numpy as np
from tvm import te
from tvm.contrib import graph_executor as runtime
ctx = remote.cl(0)
#ctx = remote.cpu(0)
# Transfer the model lib to remote device
remote.upload(lib_fname)
# Load the remote module
rlib = remote.load_module(lib_fname)
# Create a runtime executor module
module = runtime.GraphModule(rlib["default"](ctx))
# Run
module.run()
# Benchmark the performance
ftime = module.module.time_evaluator("run", ctx, number=1, repeat=10)
prof_res = np.array(ftime().results) * 1000
print("Mean inference time (std dev): %.2f ms (%.2f ms)" % (np.mean(prof_res), np.std(prof_res)))
.png){kind=link}