
Hi,
Model: yolov5n (tflite & onnx, dtype: float32)
qconfig: relay.quantize.qconfig(skip_conv_layers=None, calibrate_mode=“percentile”, weight_scale=“max”, skip_dense_layer=False)
part of output
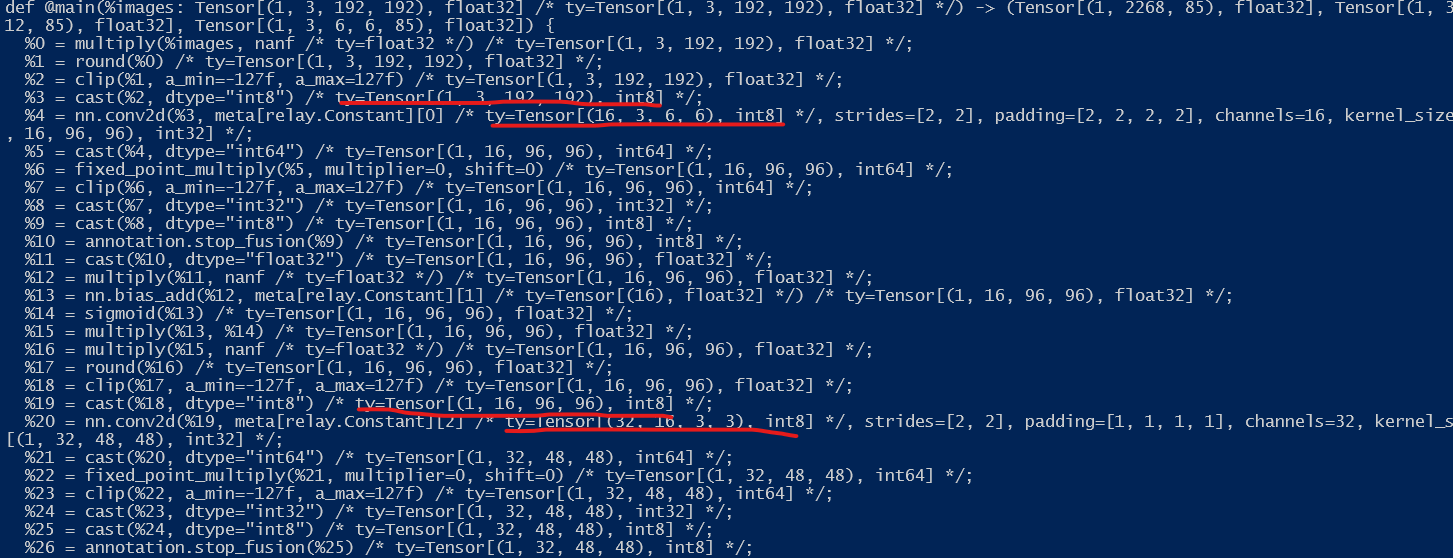
The quantization only apply on conv2D, Do I miss some config arguments?
I want all OPs’ input / output and weight all be quantized to int8, is it possibile?
Thanks~