Hi all, I find an interesting bug when I try to build TVM module in CUDA env. The code example is listed below:
import tvm
from tvm import te, tir
ib = tir.ir_builder.IRBuilder()
bx = te.thread_axis("blockIdx.x")
tx = te.thread_axis("threadIdx.x")
with ib.new_scope():
ib.scope_attr(bx, "thread_extent", 32)
ib.scope_attr(tx, "thread_extent", 32)
t = ib.allocate("float32", 16, name="t", scope="warp")
n = ib.allocate("float32", 16, name="n", scope="local")
n[0] = t[0]
stmt = ib.get()
f = tvm.tir.PrimFunc([], stmt)
f = f.with_attr('from_legacy_te_schedule', True)
m = tvm.lower(f)
tvm.build(m, target=tvm.target.Target('cuda'))
After running this code example, I got an unexpected floating point exception. To further analyze the root cause, I use gdb to trace its execution, and find out that warp_coeff_ can be 0 here.
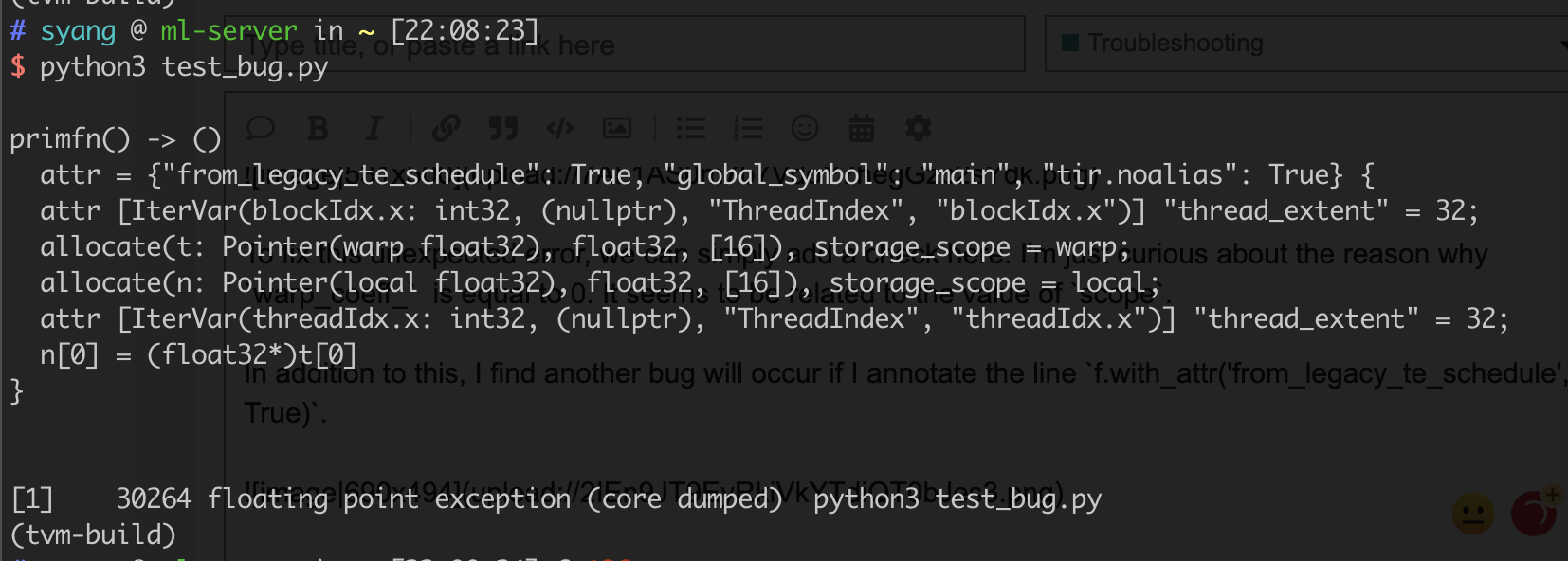
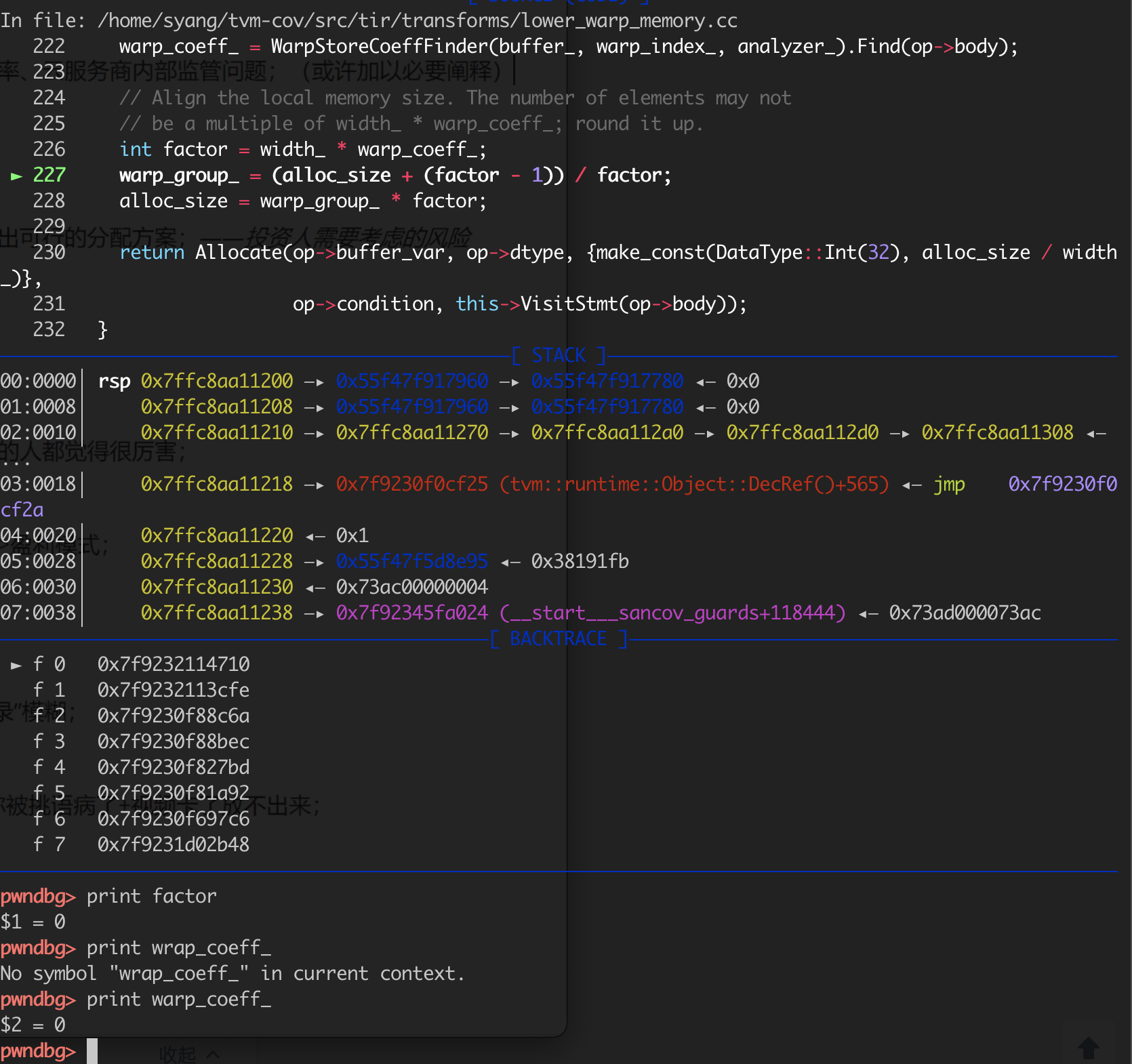
To fix this unexpected error, we can simply add a check here. I’m just curious about the reason why warp_coeff_ is equal to 0. It seems to be related to the value of scope.