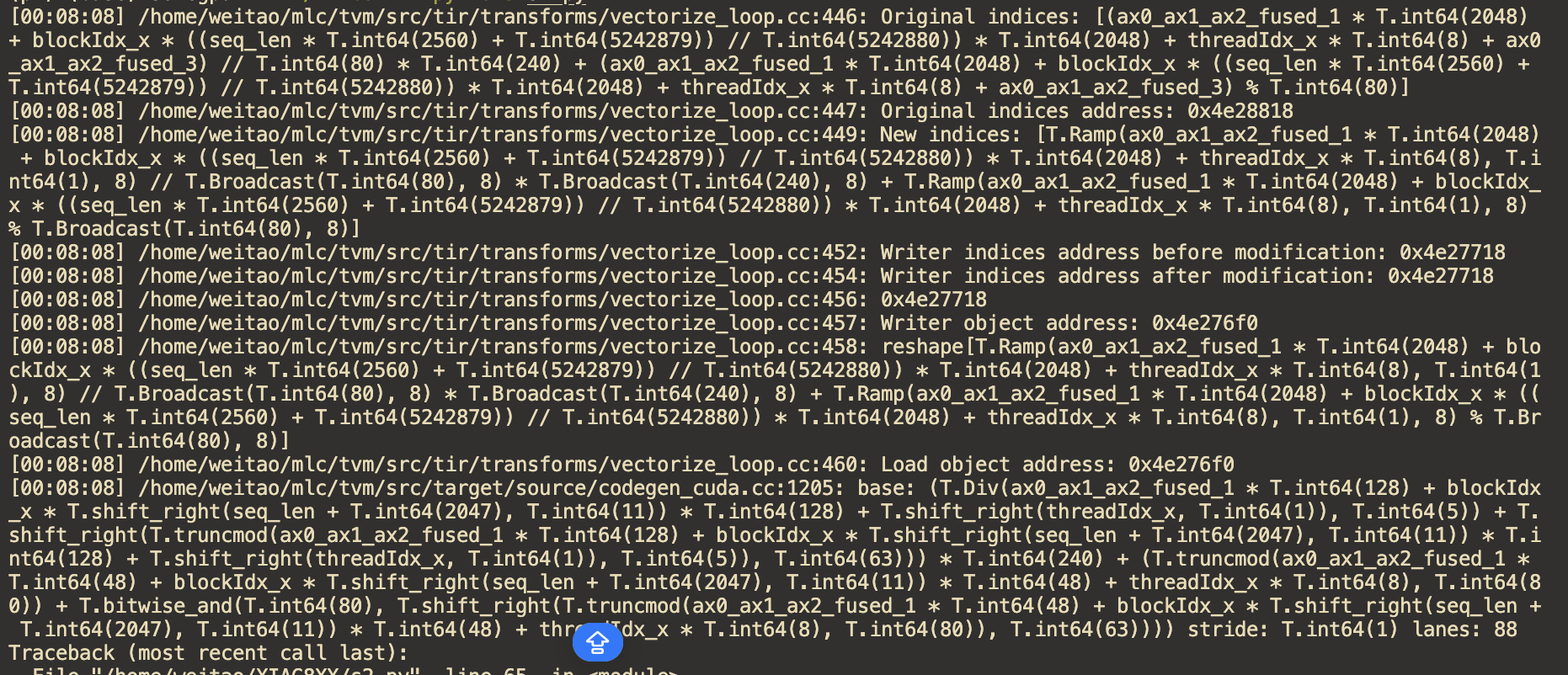
script to reproduce I have apply same schedule to below two programs, but the former one error in codegen,
because
RampNode lanes is 8 > 4 is not allowed.
Howere the later one codegen correctly, and it will not call CodeGenCUDA::VisitExpr_(tvm::tir::RampNode const*, std::ostream&).It’s quite strange, why the former one genereate RampNode in lowering but the later one did’nt ?