Dear all,
I usually run 0-batch tensors in ‘vm’ mode to “inference” and debug the output shape. It works great with vm on arbitrary devices. However, it seems to fail with ‘debug’ (the debugging interpreter) when the target is cuda (it works with llvm/cpu).
To reproduce:
import tvm
import tvm.relay as relay
import numpy as np
from tvm.relay import testing
def example():
data = relay.var("data", relay.TensorType((relay.Any(), 3, 128, 128), "float32"))
simple_net = relay.nn.conv2d(
data=data, weight=relay.var("weight"), kernel_size=(3, 3), channels=8, padding=(1, 1)
)
simple_net = relay.Function(relay.analysis.free_vars(simple_net), simple_net)
return testing.create_workload(simple_net)
if __name__ == '__main__':
data = np.zeros((0, 3, 128, 128))
mod, params = example()
target = tvm.target.Target('cuda')
dev = tvm.cuda()
with tvm.transform.PassContext(opt_level=2):
executor = relay.build_module.create_executor("debug", mod, dev, target)
tvm_out = executor.evaluate()(tvm.nd.array(data.astype('float32')), **params)
When I use cuda-gdb to debug I found it fails at https://github.com/apache/tvm/blob/main/src/relay/backend/interpreter.cc#L571
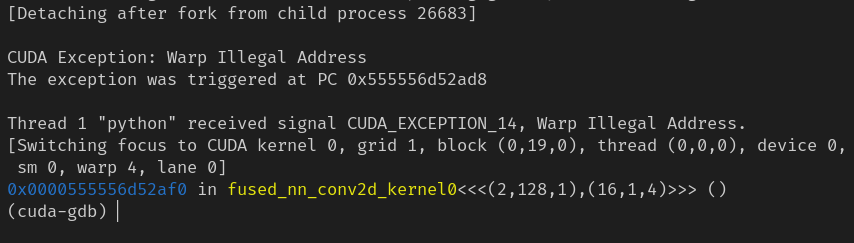
It seems that the debug interpreter did not handle when a zero-batch tensor applied on CUDA kernels.
BTW relay’s VM does not go through line 571 but line 573 (https://github.com/apache/tvm/blob/main/src/relay/backend/interpreter.cc#L573).