Hi,
I’ve been trying to use TVM’s compilation infrastructure for CUDA and torchvision/mxnet models. Everything works fine in terms of compilation and subsequent execution of the models when done sequentially. I.e. 1 model at a time.
As soon as I try to perform compilation using:
graph_module = relay.build( mod, target=target, params=params, target_host=target_host )
in parallel, for example using python’s threading or concurrent.futures modules by the means of ThreadPools or ThreadPoolExecutor, I get Segmentation Fault errors that trace back to tvm/_ffi/_ctypes/packed_func.py:227.
Further inspection of the segfault shows: “malloc_consolidate(): invalid chunk size” Likely something is getting overwritten somewhere…
That gave me a thought that maybe its smth. to do with ctypes. I switched to cython and cythonized the python ffi. The segfault is gone but threads now deadlock. I.e. in any scenario where there are >1 threads going through the relay.build() callstack, execution hangs indefinitely until I kill the parent process.
Just to clarify, I start the worker threads with completely distinct models (i.e. converted from pytorch to relay), so it isn’t the case (I think) that the compiler is reusing the same IR module for 2 concurrent compilation processes.
I’ve managed to trace back the deadlock to (line 203 of src/relay/backend/graph_runtime_codegen.cc):
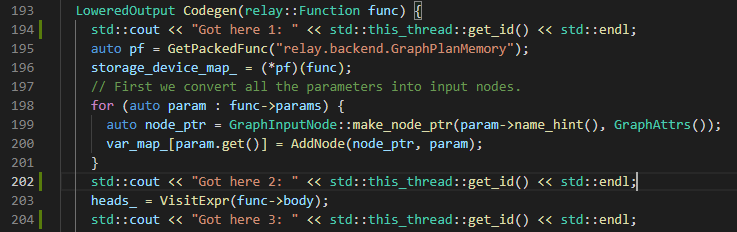
Likely I’m missing something obvious but at this point I’m not sure what else to follow and how to debug this.
Any input would be appreciated! ![]()